Choosing the Right Approach to Enterprise Data Pipelining
Data management is like a compass for organizations to use information effectively and access valuable insights while maintaining data accuracy.
Join the DZone community and get the full member experience.
Join For FreeThere’s no better way to explain data management than a compass that guides organizations on their journey to harness the power of information. It enables CIOs to benefit from qualitative insights on demand while ensuring data integrity at the same time.
Since the global market for enterprise data management is on its path to a CAGR of 12.1% (2023-2030), it is imperative for businesses to benefit from such a hockey-stick trajectory. The key is orchestrating and automating the data flow from source to destination. Exactly what data pipelining stands for.
What Is a Data Pipeline, and Why Is It Important?
As we know, data pipelining is the process of extracting data from multiple sources and further transforming it for analytical consumption. Its workflow defines all dependencies and specifies target locations and logs for troubleshooting. Data doesn’t move from one point to another. In fact, it is copied from the sources and transformed as required before finally storing it at the destination. Here, sources refer to web applications, social platforms, devices, and others that define the above-mentioned workflow. While we are at it, ETL plays a crucial role in data integration, enabling organizations to process data from different source systems and further restructure it as per exclusive business needs.
The Extract, Transform, Load (ETL) data pipeline process extracts data from various sources, transforming it into a consistent format and then loading it into a target data repository or database.
Key Considerations in Choosing a Data Pipelining Approach
A well-defined approach requires multiple key parameters that must be taken into account. These include but are not limited to the following:
Scalability
The methodology must handle dynamic data volumes crucial for future growth. With an increase in the influx of data, pipelining should be able to scale seamlessly and thereby ensure uninterrupted data processing.
Flexibility
The chosen approach must also be versatile enough to handle business data varying in format, structure, data types, and source with minimal effort on reengineering. This is important to keep enterprises stay in relevance with evolving data requirements.
Reliability
Next, the ability to perform error handling and implement various recovery mechanisms define the reliability factor of the chosen approach. Apart from lessening data loss due to failures, providing logging and monitoring to maintain data integrity is important.
Security
The selected approach must implement stringent security measures such as encryption, access controls, and compliance with data protection standards.
Cost
And finally, all of the above factors directly contrive to one major differentiator - Costing! Data pipelining comes with various direct and hidden costs across setup, maintenance, operations, etc. While optimal performance requires qualitative infrastructure, the chosen solution must align with cost-effectiveness.
Developing a Data Pipeline Strategy
IBM’s insightful post provides a comprehensive breakdown of the steps in enterprise data pipelining.
The first phase of Ingestion collects data from multiple sources in structured and unstructured formats. It might sound simpler, but it lays the foundation for a high-performing pipeline. The captured (ingested) data sets are furthered for processing and analysis through the pipeline. The right tool excels at batch processing, real-time streaming, and various event-driven approaches for efficient pipelining.
Next, Transformation prepares the ingested data sets for analytical consumption. At this stage, the collected batch is filtered into a qualitative feed. It includes strategies such as data normalization, type conversions, validations, and implementing business rules. By the end of this step, the ‘enriched’ data is prepared for the standardized format in sync with the requirements of ML algorithms.
Integration, as understood, merges the multiple types of data sets (from different sources) into a unified view. The reconciliation phase involves tasks such as merging and deduplication. This is the core of the pipelining lifecycle for enterprises as it delivers a holistic, meaningful view of all the data processed so far.
To further store this processed data in a repository for analysis, Data Storage selects appropriate systems from warehouses, lakes, cloud systems, on-premise, or even a hybrid landscape. Factors such as volume, velocity, and analysis are considered in pursuing the same. This choice is highly important because it ensures seamless accessibility and further supports efficient retrieval for reporting.
Finally, the processed data is fed from the storage to the destination points such as reporting dashboards, analytical platforms, visualization dashboards, CRM systems, or any custom application.
That being said, it is important to consider the impact of testing, monitoring, and continuous improvement are important for an effective data pipeline. While thorough testing detects possible issues, monitoring helps in resolving them. Furthermore, continuous improvement ensures the system is adaptive to dynamic business needs, thereby unlocking valuable returns.
However, one size doesn’t fit all!
Like any data process, pipelining too has its own share of challenges. The pipelining approach can be customized for an optimal outcome to address issues that might vary from organization to organization.
I stumbled upon the two-approach system from Skyvia, a comprehensive platform that supports a wide range of data integration sources and destinations, thereby widening the scope of pipelining.
They provide two approaches for building data pipelines: an easy approach using the Replication tool and a complex approach with Data flow. The Replication tool offers a simple three-step process for moving data between locations, while Data flow supports advanced transformations and integration of multiple data sources.
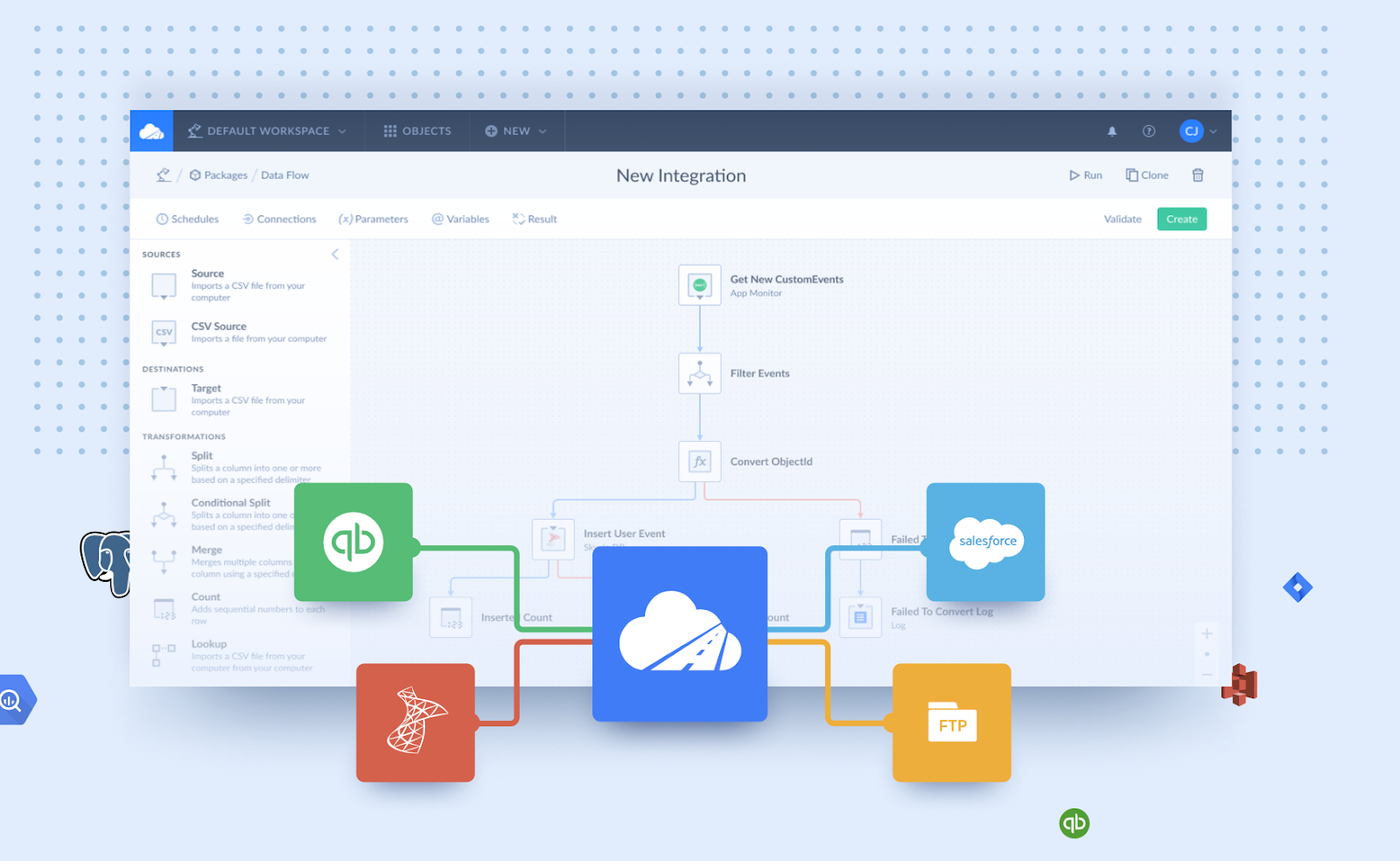
It is ideal for scenarios requiring simultaneous data loading, multistage transformations, or data enrichment. For instance, in a Mailchimp subscriber list scenario, Data flow can add new subscribers and update existing records in a database table based on target presence. Skyvia offers flexibility to address diverse data pipeline needs. Nontechnical users can create and manage data pipelines with a visual drag-and-drop interface.
Likewise, there’s Stitch, an open-source ETL connector that provides various pre-built connectors. There’s Fivetran which is popular for a no-code pipelining for a range of sources and destinations. AWS DMS provides migration and replication through a fully-managed service.
I always recommend a set of bare minimum outcomes to expect before deciding upon your preferred data pipelining tool.
What should be the expected outcomes from the pipelining process?
The Expected Outcomes From a Well-Executed Data Pipelining Process Should:
- Make the data readily accessible from a wide range of sources. Enhanced data availability helps in making informed and timely decisions.
- Produce and feed qualitative data sets by incorporating validation checks at multiple points. Such increased readability converts into better reporting.
- Deliver a holistic view of data from disparate data sources through efficient integration. This enables cross-functional analysis.
- Reduce latency by streamlining the end-to-end processing of data. The purpose is to achieve agile responsiveness to dynamic business needs.
- Facilitate governance practices to stay in compliance with regulations such as GDPR.
- Facilitate an optimal mix of automation and human intelligence to minimize errors and enhance operational efficiency.
- Accelerate the time from raw data to finished, actionable insights.
Conclusion
In the age of automation, businesses should also look at outcomes beyond just the process. Successful data management isn’t only about storing and streaming. It has to produce actionable knowledge and drive meaningful growth.
It all depends upon how you treat data; as a strategic asset of just raw pieces of information. The choice is yours.
Opinions expressed by DZone contributors are their own.
Comments