Clean Code - Robert C. Martin's Way
Check out this breakdown of some of the elements from Robert C. Martin's acclaimed book, Clean Code.
Join the DZone community and get the full member experience.
Join For Free
Writing good code in accordance with all the best practices is often overrated. But is it really? Writing good and clean code is just like good habits which will come with time and practice.
We always give excuses to continue with our patent non-efficient bad code, reasons like no time for best practices, meeting the deadlines, angry boss, tired of the project, etc. Most of the time we try to procrastinate by saying will make it efficient and clean later but that time never comes.
Bad code is not problematic for us to understand but for the other developers who will handle that after us.
So, let me get you to the points by Robert C. Martin in his captivating book Clean Code.
Meaningful Names
We name our variables, class, directories, packages, jar files, war files, ear files. We name, we name and we name. So, we should name well.
Choosing good names takes time but saves more than it takes. Everyone who reads your code (including you) will be happier if you do.
So while naming anything, we should be able to answer these three questions:
- why it exists
- what it does
- how it is used
And if we can't answer them, that means we are not doing it right.
If a name requires a comment, then the name doesn't reveal its intent. Say for example:
int d; // elapsed time In days
So just by looking at this " d", no one is going to understand what this d is doing and eventually waste time over it. Our names should be such that says its intention, like,
int elapsedTimeInDays;
Avoid Disinformation
Programmers must avoid leaving false clues that obscure the meaning of the code. We shouldn't use type information in names.
Do not refer to a grouping of accounts as an accountList unless it's actually a List. The word list means something specific to programmers. If the container holding the accounts is not actually a List, it may lead to false conclusions. So, accountGroup or bunchOfAccounts or just plain accounts would be better.
Don't be afraid to make a name long. A long descriptive name is better than a short enigmatic name.
A long descriptive name is better than a long descriptive comment.
Just have a look at this snippet. Having a hard time to tell what is it doing? I, too, have few questions:

1. What kinds of things are in theList?
2. What is the significance of the zeroth subscript of an item in theList ?
3. What is the significance of the value 4?
4. How would I use the list being returned?
So a refactored better version of the above snippet could be something like this:

Now, things get clear.
Functions
The first rule of functions is that they should be small. The second rule of functions is that they should be smaller than that. The smaller and more focused a function is, the easier it is to choose a descriptive name. According to Martin, your functions should be as small as possible, maximum length should be less than 20 lines. If it exceeds this limit, you should segregate the logic into different smaller functions.
Talking about the arguments, the number of arguments should be as minimum as possible. The ideal number of arguments for a function is zero. Such a function doesn't depend on any input so there's always going to be some trivial output from it. It will be easy to test. Next comes one (monadic) which is based on functional programming rules, followed closely by two (dyadic). Three arguments (triadic) should be avoided wherever possible. More than three (polyadic) requires very special justification and then shouldn't be used anyway.
If any in case the number of arguments are more than 3, then we should group them into a meaningful object.
Arguments are even harder from a testing point of view. Imagine the difficulty of writing all the test cases to ensure that all the various combinations of arguments work properly.
Avoid output arguments: Anything that gets modified or mutated but is not returned by the function. An array passed to a function, which changes the body of the array but not returning it, then it is the output argument.
If the name of the function doesn't tell the developer about all the functionalities implemented by it. Then these hidden functionalities are called side effects. Side effects are lies!
Your function promises to do one thing, but it also does other hidden things. Sometimes it will make unexpected changes to the variables of its own class. Sometimes it will make them to the parameters passed into the function or to system globals. In either case, they are devious and damaging mistruths that often result in strange temporal couplings and order dependencies.
See this example:

So, as you can see that the intent of this function (as its name says) is to just check the password. But it is initializing the session, too. This could be misleading because whosoever calls this function, in fact, will not aware of this hidden functionality and might cause blunder in your code.
Do One Thing!
Your function should do only one thing. If it does two or more, better break them into different functionalities. Keep It Simple, Stupid!
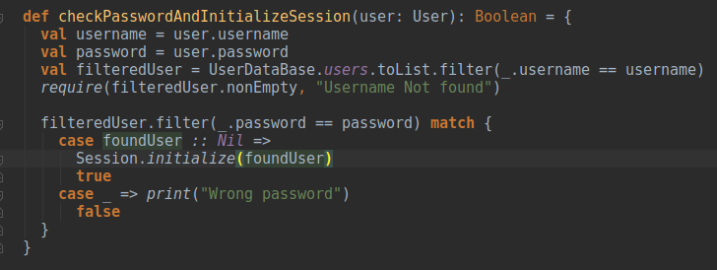
This function is doing two things first it checks the password and then initializing the session. The better way could have been checkPassword and initializeSession would be two separate functions and caller would just call them accordingly.
Data Structures and Objects
Objects hide their data behind abstractions and expose functions that operate on that data. Data structure expose their data and have no meaningful functions. They are virtual opposites. In the case of objects, it is easy to add new objects but harder to add new behavior. Let's understand this through an example:

As you can see, if I want to add a new type of shape, say for example, rhombus, I can simply add its class extending Shape trait and provide the implementation for the area method. That's all I need to do. But its hard to add new behavior. Why? If suppose I need to a new method say volume. Then all the subclasses extending this trait need to change.
Now consider data structures example:
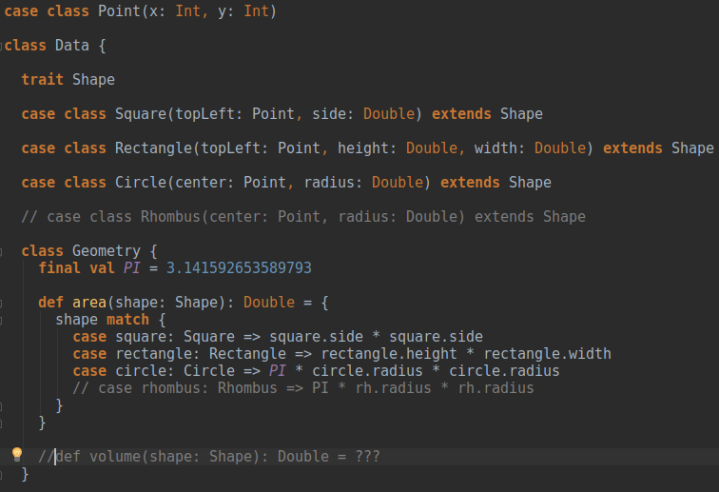
Here I have created a separate class, Geometry, containing method area(). In this, if I need to add new behavior, say, volume, then I can easily add that without making any trouble and provide implementations for the different shapes. But in case I need to add new shape (new object), I need to add its implementation in all the methods of the Geometry class.
Procedural code (code using data structures) makes it easy to add new functions without changing the existing data structures. OO code, on the other hand, makes it easy to add new classes without changing existing functions.
In any complex system, there are going to be times when we want to add new data types rather than new functions. For these cases, objects and OO are most appropriate. On the other hand, there will also be times when we'll want to add new functions as opposed to data types. In that case, procedural code and data structures will be more appropriate.
The Law of Demeter
It says our function should only access the classes/objects that it has direct access to which are:
i. Objects in class parameter
ii. An object in function parameter
iii. An object in class members
iv. Objects created inside the function body.
In short, the Law of Demeter aims to keep you from doing things like this:
objectA.getObjectB().doSomething();
or even worse, this:
objectA.getObjectB().getObjectC().doSomething();
It might seem odd to have a section about error handling in a book about clean code. Error handling is just one of those things that we all have to do when we program. Input can be abnormal and devices can fail. In short, things can go wrong, and when they do, we as programmers are responsible for making sure that our code does what it needs to do.
"Error handling is important, but if it obscures logic, it's wrong. "
A few tips to keep in mind while doing error handling in your code:
- Use unchecked Exceptions. The price of using checked exceptions is an Open/Closed Principle violation. If you throw a checked exception from a method in your code and the catch is three levels above, you must declare that exception in the signature of each method between you and the catch. This means that a change at a low level of the software can force signature changes on many higher levels. The changed modules must be rebuilt and redeployed, even though nothing they care about changed.
- Don't return NULLWhen we return null, we are essentially creating work for ourselves and foisting problems for our callers. All it takes is one missing null check to send an application spinning out of control.
- Don't pass NULLReturning null from methods is bad, but passing null into methods is worse. Unless you are working with an API which expects you to pass null, you should avoid passing null in your code whenever possible.
So these were just a few topics from the book Clean Code. This book has everything you are looking for. So, go give it a read. For more topics from this book, you can refer to this blog.
I hope this blog helped you!
Published at DZone with permission of Ramandeep Kaur. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments