Cleaning Up an S3 Bucket With the Help of Athena
Learn how to detect unused objects within your S3 buckets and do some spring cleaning using the Athena query service.
Join the DZone community and get the full member experience.
Join For FreeImagine your basement or attic would provide unlimited capacity for storing stuff. Sounds great? Maybe at first. But imagine how much stuff would pile up over the years if you were not forced to clean up because of limited storage space every now and then. S3 (Simple Storage Service) offers unlimited storage capacity. And that is why data can pile up endlessly if you don't clean up unused data from time to time. You will learn how to detect unused objects within your S3 buckets in this article.
S3 provides lifecycle management which allows you to define a lifetime for your objects. The life of an object starts with its upload and ends after the lifetime you have specified in days. In many use cases, deleting files after a fixed period of time is not sufficient because, for example, some objects are downloaded regularly for years. Other objects are uploaded once and never downloaded again.
So how do you clean up files from your S3 bucket that have not been downloaded for a long period of time? By using the following building blocks:
- S3 Access Logs: writes every request to your S3 bucket into a log file.
- S3 Inventory: provides a CSV or ORC file containing a list of all objects within a bucket daily.
- Athena: allows you to query structured data stored on S3 ad-hoc.
We will use Athena to query the access logs and inventory lists from S3 to find objects without any read requests within the last 90 days.
Configuring S3 Inventory
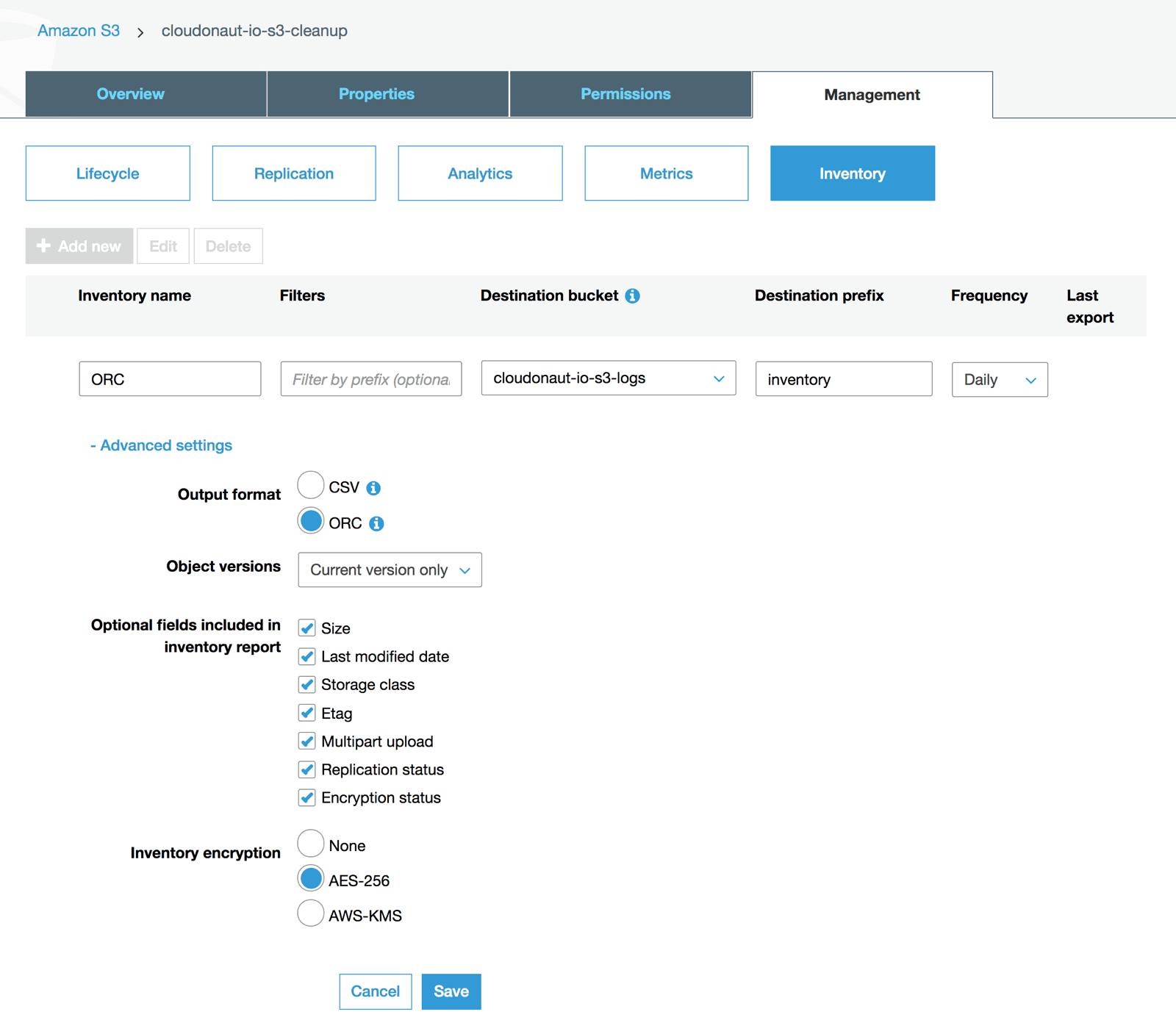
First of all, you should create a separate S3 bucket to store access logs and inventories, which I have named cloudonaut-io-s3-logs. Next, create a new inventory configuration for the bucket you want to clean up, cloudonaut-io-s3-cleanup in my example. The following screenshot shows the most important configuration options.
- Type in
ORCas inventory name. - Select the logs and inventories bucket,
cloudonaut-io-s3-logsin my example. - Type in
inventoryas the key prefix. - Select
dailyas the delivery frequency for the inventory. - Choose output format
ORCwhich is a perfect fit when analyzing data with Athena. - If versioning is not enabled for your bucket, choose
Current version only. - Select all optional fields, better safe than sorry.
- Server-side encryption with
AES-256is selected by default, as you export the encryption status.
Next, we need to set up the second data source: S3 Access Logs.
Configuring S3 Access Logs
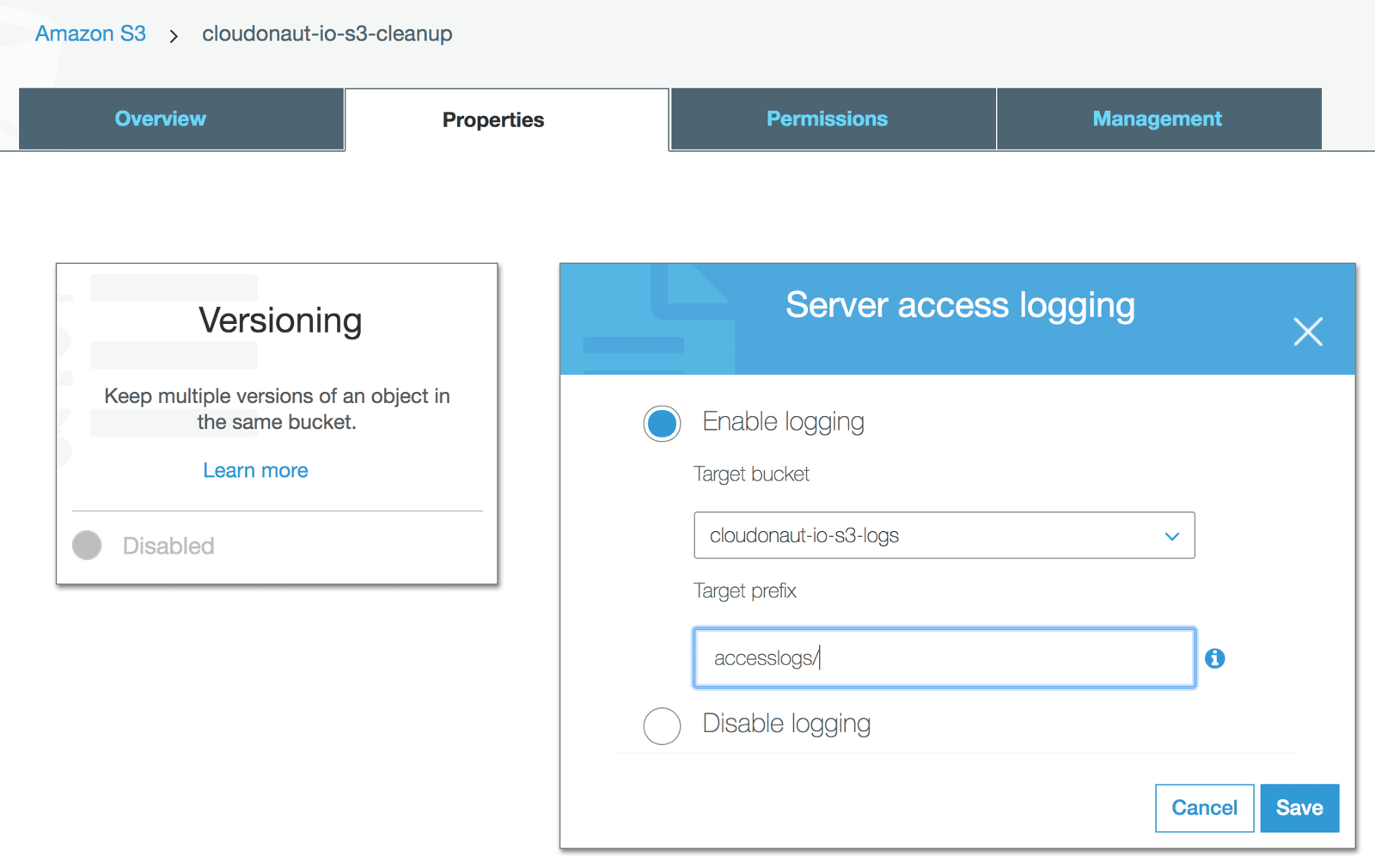
Enable Access Logs for the bucket you want to clean up, cloudonaut-io-s3-cleanup in my example.
- Select the logs and inventories bucket as target bucket, which is
cloudonaut-io-s3-logsfor me. - Choose
accesslogs/as the prefix for the log files.
It will take up to 48 hours until access logs and the inventory are available. It makes sense to stop here and wait until the needed data is available before proceeding with the next steps.
Creating Athena Tables
Athena is a query service which we will use to query the access logs as well as the inventory. Athena executes ad-hoc queries on data stored on S3. To be able to query data tables we need to define temporary tables.
Open Athena's Query Editor and run the following query to create the inventory table. The table accesses the inventory files stored on S3 in ORC format. You have to replace the name of the S3 bucket cloudonaut-s3-logs with your bucket containing the logs and inventories.
CREATE EXTERNAL TABLE inventory(
bucket string,
key string,
size bigint,
last_modified_date timestamp,
e_tag string,
storage_class string,
is_multipart_uploaded boolean,
replication_status string,
encryption_status string
)
PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 's3://cloudonaut-io-s3-logs/inventory/cloudonaut-io-s3-cleanup/ORC/hive';The access logs are stored in CSV-alike files on S3. The following query will create the table containing the access logs. A regular expression is used to parse the S3 access log files with Athena. You have to replace the name of the S3 bucket cloudonaut-s3-logs with your bucket containing the logs and inventories.
CREATE EXTERNAL TABLE accesslogs(
owner string,
bucket string,
time string,
remoteip string,
requester string,
requestid string,
operation string,
key string,
requesturi string,
httpstatus int,
errorcode string,
bytessent int,
objectsize int,
totaltime int,
torunaroundtime int,
referrer string,
useragent string,
versionid string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' = '^([^\\s]*)\\s([^\\s]*)\\s\\[([^\\]]*)\\]\\s([^\\s]*)\\s([^\\s]*)\\s([^\\s]*)\\s([^\\s]*)\\s([^\\s]*)\\s\\"([^\\"]*)\\"\\s([^\\s]*)\\s([^\\s]*)\\s([^\\s]*)\\s([^\\s]*)\\s([^\\s]*)\\s([^\\s]*)\\s\\"([^\\"]*)\\"\\s\\"([^\\"]*)\\"\\s([^\\s]*)$'
)
LOCATION 's3://cloudonaut-io-s3-logs/accesslogs/';We have prepared everything we need to detect objects that have not been accessed for a long period of time.
Detecting Unused Objects With Athena
Before running any queries you need to update the partitions of the inventory table. Run the following query to do so.
MSCK REPAIR TABLE inventory;The accesslogs table is not partitioned by default. Therefore, you should think about limiting the number of access log files that Athena needs to scan. For example, by using a lifecycle policy to delete access logs after 90 days.
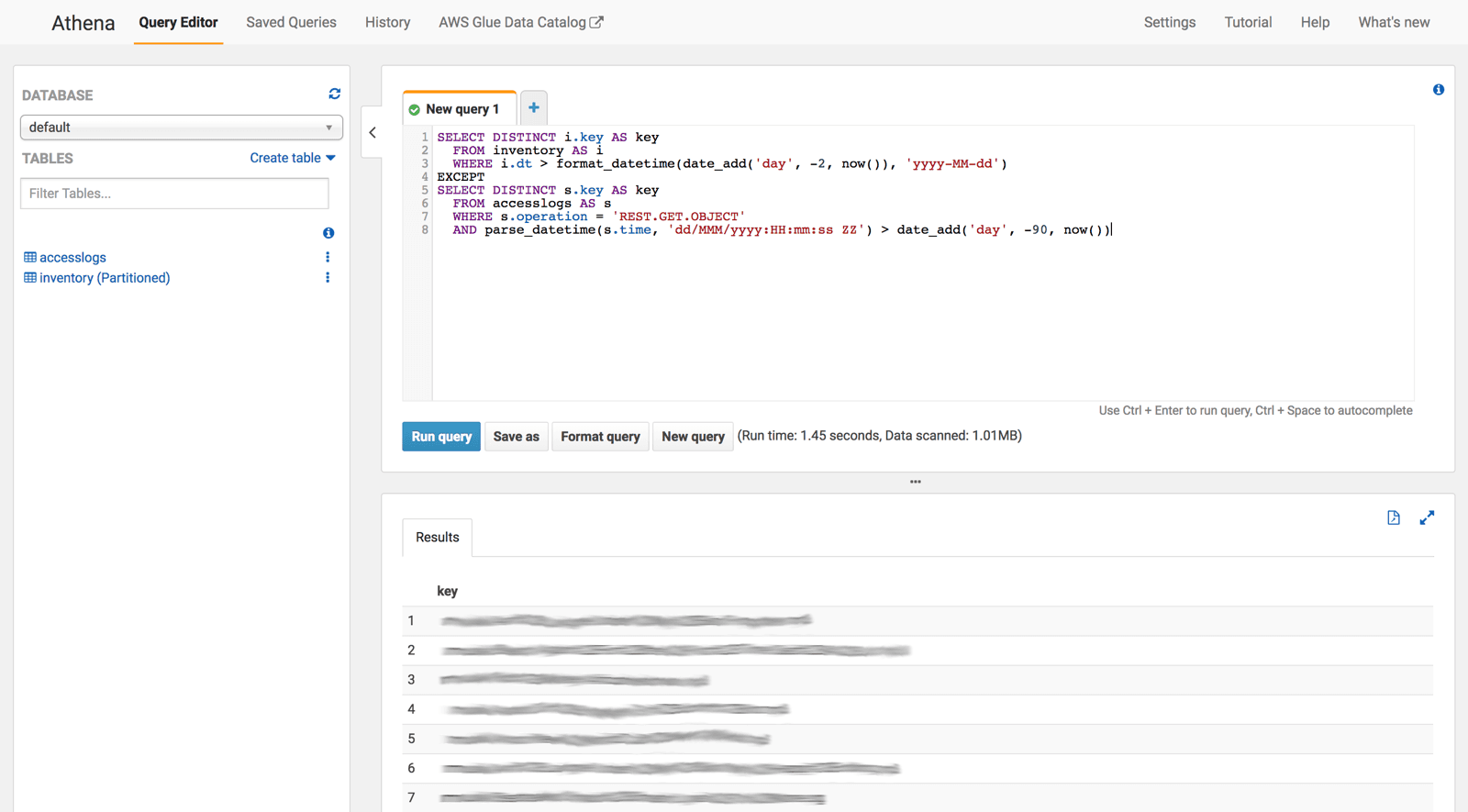
The following query lists the keys of all objects that haven't been read within the last 90 days.
SELECT DISTINCT i.key AS key /* select all object keys that have been recorded within the last 2 days */
FROM inventory AS i
WHERE i.dt > format_datetime(date_add('day', -2, now()), 'yyyy-MM-dd')
EXCEPT
SELECT DISTINCT s.key AS key /* select all object keys that have been accessed within the last 90 days */
FROM accesslogs AS s
WHERE s.operation = 'REST.GET.OBJECT'
AND parse_datetime(s.time, 'dd/MMM/yyyy:HH:mm:ss ZZ') > date_add('day', -90, now())The output of the query gives you a list of objects which are not used anymore. You could use the list to delete all these objects manually or automatically.
As Athena allows you to query the access logs and inventory in a very flexible way you are able to adapt the query to your specific needs. For example, you could rest the lifetime of an object not only when the object is downloaded but also when a new version of the object is uploaded.
Go and spring-clean your S3 buckets!
Published at DZone with permission of Andreas Wittig. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments