Cloud Hardware Diagnostics for AI Workloads
AI workloads need reliable hardware. Cloud providers are developing intelligent diagnostics to predict, detect, and resolve GPU and server failures efficiently.
Join the DZone community and get the full member experience.
Join For FreeWith the recent boom in AI, the footprint of AI workloads and AI-supported hardware servers deployed in cloud data centers has grown exponentially. This growth is spread across multiple regions worldwide over various data centers. To support this growth and to ensure leadership over various cloud competitors (like Azure, AWS, and GCP), they have started building a fleet of specialized high-performance computing servers. The AI workloads that perform a huge amount of data processing, training, and inference of data models require a special kind of hardware, unlike traditional general-purpose compute servers.
Hence, all cloud service providers are investing heavily in GPU, TPU, and NPU-based servers that are effective in hosting AI workloads. The majority of these servers are of the Buy Model type, and cloud service providers are dependent on the ‘Other Equipment Manufacturer’ (OEM) for diagnostics and maintenance of the hardware. This dependency has caused a lot of pain for cloud service providers as the repair SLAs are uncertain and expensive, impacting the fleet's availability.
Hence, the cloud providers are shifting from simple Buy to Make (OEM-designed server maintenance to In-House server maintenance). This shift in the business model has resulted in a transition in the Service Model in data centers from OEM-reliant to self-maintainer. To support this self-reliance and the growth of the AI hardware fleet, every cloud service provider is aiming to reduce the cost of service and build Swift, Remote, Accurate, Automated, and Economical HW Diagnostics.
Why Hardware Diagnostics Matter for AI
AI workloads are unique in nature and require parallel processing and compute-intensive hardware that is reliable and stable. However, HW components often fail, and at times without notice. A single degraded GPU or memory failure can derail hours of training or crash real-time inference endpoints. Some common hardware-related issues impacting AI workloads:
- GPU memory errors (ECC failures, tray issues)
- GPU thermal throttling
- GPU Infini band failures
- CPU IErrs and uncorrectable errors
So, to support customer needs for high availability and uninterrupted service, cloud providers require accurate hardware diagnostics that pinpoint the faulty component.
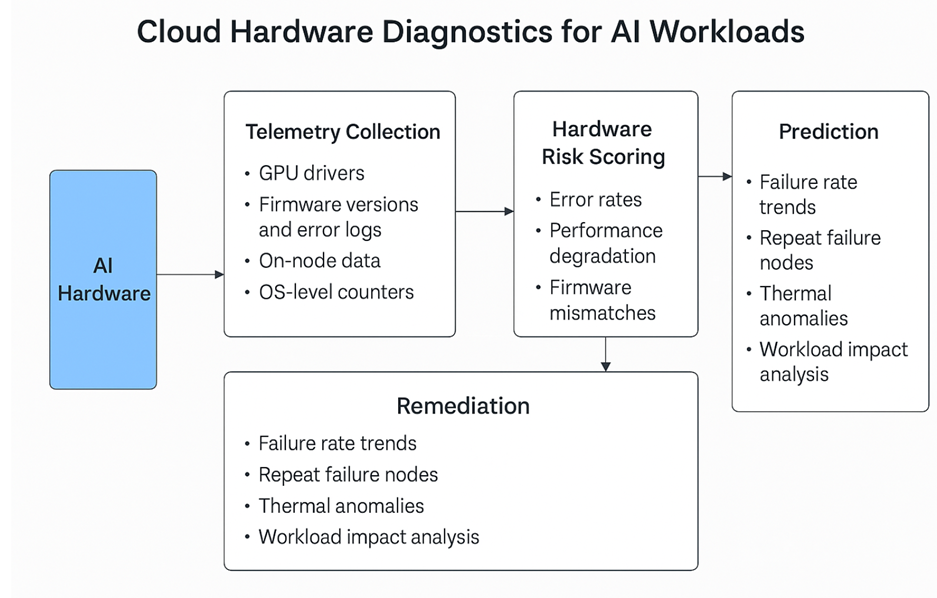
The hardware diagnostics engine for AI hardware will be broken down into the following components:
Telemetry Collection Layer
This layer focuses on collecting real-time hardware telemetry regarding various components:
- GPU drivers
- Firmware versions and error logs (BMC, BIOS)
- On-node data (temperature, utilization, power draw)
- OS-level counters (oom-kill, system crashes, dmesg logs)
The platform will use cloud-based agents to collect and publish hardware telemetry to a centralized location.
Hardware Risk Scoring Layer
This layer is used by diagnostics to lock a hardware risk score based on hardware failure patterns. The Diagnostics engine will sample errors, such as ECC error rates over time, thermal headroom across workloads, GPU performance degradation from baseline, Firmware mismatches versus golden configuration, and hardware retry count per VM allocation.
Sample logic: Node_Health_Score = weighted_sum (ECC_rate, Thermal_Throttle, Firmware_Drift, Allocation_Retry)
The risk score will be used by the diagnostics engine to predict and mitigate hardware failure.
Prediction, Mitigation, and Remediation Layer
The diagnostic engine will use telemetry data from various hardware components and risk rating scores to take various mitigation and remediation actions.
Prediction of Hardware Faults
- It takes place during the LIVE state of the server with LIVE customer workloads running on it.
- The hardware diagnostics engine will collect hardware health attributes (i.e., hardware telemetry) from the telemetry layer and collaborate with other cloud platform-level machine learning services to predict HW Faults.
- Hardware diagnostics will also perform a predictive failure analysis to anticipate impending HW Faults based on the risk rating scores and take proactive action to move the AI workload to a healthy server without interrupting the workload.
Mitigation of Hardware Faults
- It takes place during the LIVE state of the node with LIVE customer workloads.
- If hardware fault prediction is not feasible, then Hardware will attempt to mitigate the HW faults to ensure continuity of the HW service. Some of the mitigation actions currently being used include disk mirroring, memory page offlining, error detection and correction, and auto-reset of the GPU driver on fault.
Remediation of Hardware Faults
- This takes place during an OFFLINE state of the Node when customer workloads are vacated.
- If HW fault mitigation is not feasible, then HW diagnostics will work to efficiently attribute the failures based on device telemetry collected in the telemetry layer. Once the attribution of failure is complete, the hardware faults go through service and component repair at the data centers.
Diagnostics, Metrics, and AI Hardware Fleet-Wide Insights
Build a reporting dashboard to expose GPU/node health metrics:
- Failure rate trends by GPU SKU, zone, or region.
- Repeat failure nodes.
- Heatmaps of thermal or utilization anomalies
- Top SKUs and hosts contributing to model training failures.
- Correlated workload impact analysis (e.g., job retry trends, latencies)
Conclusion
Building robust and reliable diagnostics will help baseline AI hardware health and find out what the hardware health looks like across GPU SKUs and host models. We can correlate hardware failure events with AI model degradations.
Opinions expressed by DZone contributors are their own.
Comments