Coalesce With Care
In Spark, there are two common transformations to change the number of tasks; coalesce and repartition. They are very similar but not identical. Let's see how.
Join the DZone community and get the full member experience.
Join For Free
Here is a quick Spark SQL riddle for you; what do you think can be problematic in the next spark code (assume that spark session was configured in an ideal way)?
sparkSession.sql("select * from my_website_visits where post_id=317456")
.write.parquet("s3://reports/visits_report")Hint1: The input data (my_website_visits) is quite big.
Hint2: We filter out most of the data before writing.
I’m sure that you figured it out by now; if the input data is big, and the spark is configured in an ideal way, it means that my spark job has a lot of tasks. This means that the writing is also done from multiple tasks.
This probably means that the output of this will be a large amount of very small parquet files.
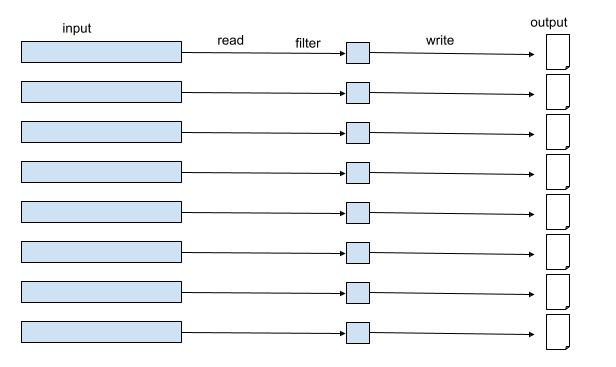
Small files are a known problem in the big data world. It takes an unnecessarily large amount of resources to write this data, but more importantly, it takes a large number of resources to read this data (more IO, more memory, more runtime).
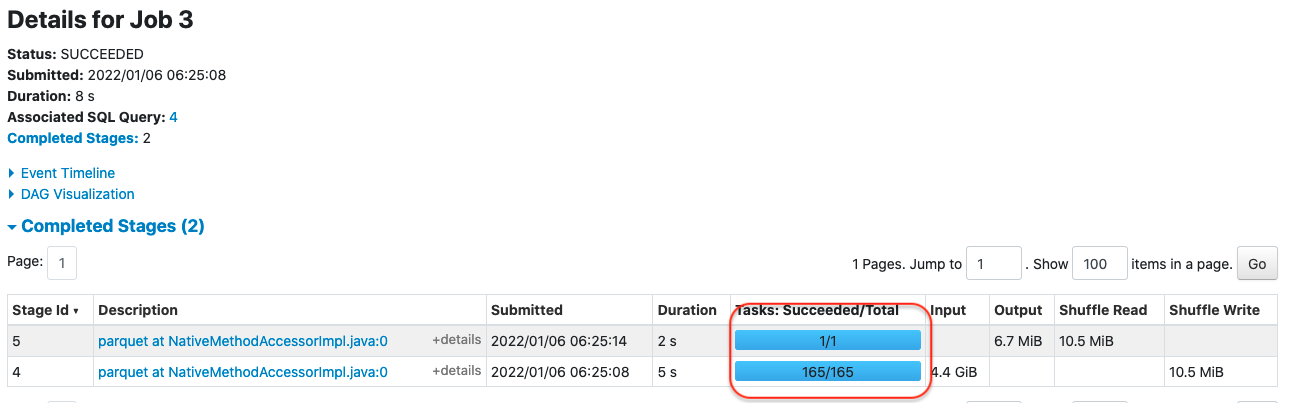
This is how it looks in Spark UI.
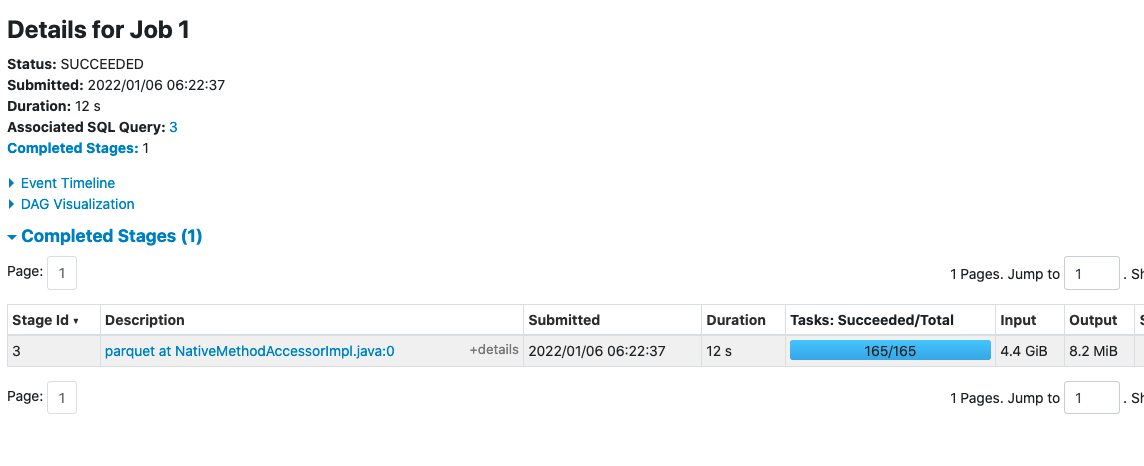
In this case, we have 165 tasks, which means that we can have up to 165 output files. How would you improve this? Instead of writing from multiple workers, let’s write from a single worker.
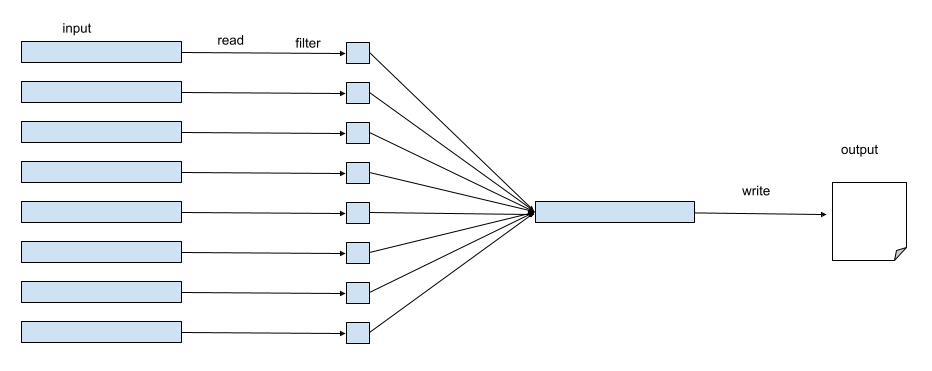
How would this be done in spark?
Coalesce vs. Repartition
In Spark, there are two common transformations to change the number of tasks; coalesce and repartition. They are very similar but not identical.
Repartition in spark SQL triggers a shuffle, where coalesce doesn’t. And as we know, shuffle can be expensive (note: this is true for DataFrames/DataSets). In RDDs, the behavior is a bit different).
So let’s try to use coalesce.
sparkSession.sql("select * from my_website_visits where post_id=317456")
.coalesce(1).write.parquet("s3://reports/visits_report")
That took 3.3 minutes to run, while the original program took only 12 seconds to run.
Now let’s try it with repartition:
sparkSession.sql("select * from my_website_visits where post_id=317456")
.repartition(1).write.parquet("s3://reports/visits_report")That took only 8 seconds to run. How can that be?! repartition adds a shuffle, so it should be more expensive.
Let’s look at Spark UI. This is how it looks when using coalesce.
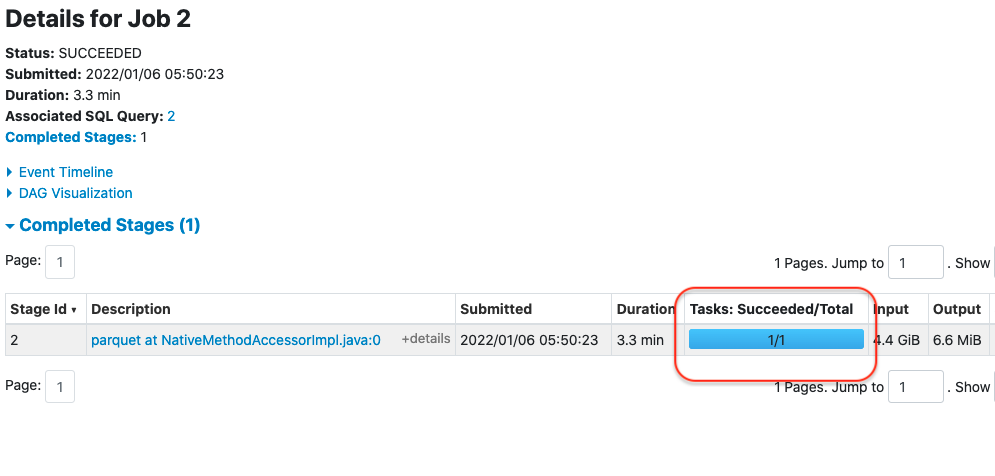
And this is when using repartition:
The reason should be clear. Using coalesce reduces the number of tasks for the entire stage, also for the part which comes before calling the coalesce. This means that the reading of the input and the filtering was done using only a single worker with a single task, as opposed to 165 tasks with the original program.
Repartition on the other hand creates a shuffle, and this indeed adds to the runtime, but since the 1st stage is still done using 165 tasks the total runtime is much better than coalesce. Does this mean that coalesce is evil? Definitely not. Let’s see an example where coalesce is actually a better choice.
Limit With Coalesce
sparkSession.sql("select * from my_website_visits").limit(10)
.write.parquet("s3://reports/visits_report")This ran for 2.1 minutes, but when using coalesce:
sparkSession.sql("select * from my_website_visits")
.coalesce(1).limit(10).write.parquet("s3://reports/visits_report")It ran for only 3 seconds(!)
As you can see coalesce helped a lot here. To understand why we need to understand how does the limit operator work. Limit is actually dividing the program into 2 stages with a shuffle in between. In the 1st stage, there is a LocalLimit operation, which is executed in each of the partitions. The filtered data from each of the partitions are then combined into a single partition where another limit operation is executed on that data. This operation is defined as the GlobalLimit.
This is how it looks in the SQL tab in Spark UI:
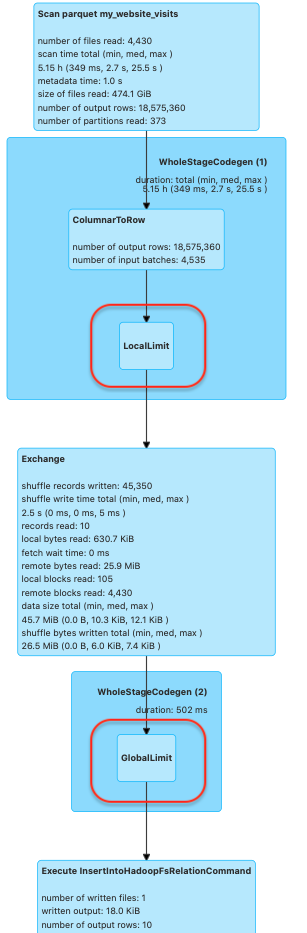
Notice that the local limit and global limit are in separate stages. Now if this data was ordered in some way, that would have made sense to execute the local limit on each partition before doing the global limit. But since there is no order here at all, this is obviously a wasteful operation, we could’ve just taken those 10 records randomly from one of the partitions, logically it wouldn’t make a difference and it would’ve been much faster.
When using coalesce(1) though it helps in 2 ways.
First, as seen, it sets the number of tasks to be 1 for the entire stage. Since the limit also reduces the number of tasks to 1, then that extra stage and shuffle which limit adds are not needed anymore.
But there is another, more important reason why coalesce(1) helps here. As seen, coalesce(1) reduces the number of tasks to 1 for the entire stage (unlike repartition which splits the stage), the local limit operation is done only on a single partition instead of doing it on many partitions. And that helps the performance a lot.
Looking at this in spark UI when using coalesce, you can clearly see that the local and global limits are executed on the same stage.
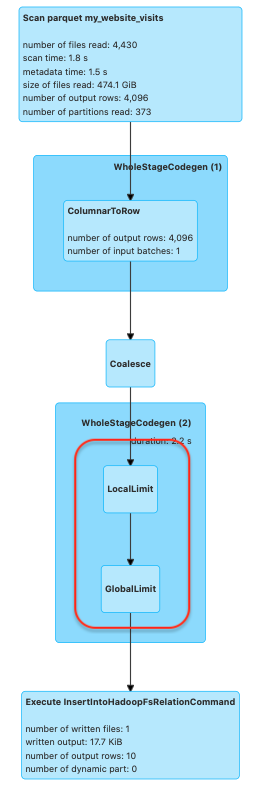
And what about Repartition for this case?
sparkSession.sql("select * from my_website_visits").repartition(1).limit(10)
.write.parquet("s3://reports/visits_report")It takes 2.7 seconds. Even slower than the original job. This is how it looks in the SQL tab in spark UI:

We see that in this case local and global limits are also executed on the same stage on that single task, like coalesce. so why it is slower here?
Repartition as opposed to coalesce doesn’t change the number of tasks for the entire stage, instead, it creates a new stage with a new number of partitions. This means that in our case it is actually taking all the data from all the partitions and combining them into a single big partition. This of course has a huge impact on performance.
Conclusion
As seen, both coalesce and repartition can help or hurt the performance of our applications, we just need to be careful using them.
Published at DZone with permission of Avi Yehuda. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments