Cognitive Load-Aware DevOps: Improving SRE Reliability
SRE reliability depends on human cognition as much as infrastructure. Reducing cognitive load is key to resilient systems.
Join the DZone community and get the full member experience.
Join For FreeThe site reliability engineering (SRE) community has tended to view reliability as a mechanical problem. So we have been meticulously counting "nines," working on the failover groups, and making sure our autoscalers have all the least settings they need. But something appears to be metamorphosing threateningly: people are becoming increasingly lost in high-availability metrics like 99.99%, which seemingly mask an infrastructure that would melt like butter if not for humans stepping in manually.
We have reached the maximum level of complexity. Modern cloud-native ecosystems, including microservices, temporary Kubernetes pods, and distributed service meshes, are experiencing an exponential growth in the amount of traffic they handle. While the infrastructure continues to scale up and down at will, our human cognitive bandwidth, as defined by Miller's Law, simply cannot keep up. We are trying to manage state spaces that approach infinity with something as minimalist as biological bandwidth.
That is why service-level indicators (SLIs) and service-level objectives (SLOs) in their standard guise fail. They evaluate the system's results without considering the mental processes required to resolve incidents. If an engineer is cognitively overloaded, their mental model of the system will break down, leading to heuristic errors and "action paralysis." If our mean time to understand (MTTU) keeps rising as we achieve our SLOs, we are creating a Reliability Paradox in which a system becomes so sophisticated that the instruments proposed to provide observability actually increase the noise-to-signal ratio, thereby diverting cognitive capacity from fixing the technical problem. If we are to improve reliability, we must not rely on telemetry alone; we must shift our focus to protecting the engineer's cognitive throughput.
The Framework: Cognitive Load Theory in a DevOps Context
The use of Cognitive Load Theory (CLT) could be a potential approach to address the Reliability Paradox. When applied to site reliability engineering (SRE), this psychological framework divides mental effort into three types:
- Intrinsic load: The task involves processing a significant amount of information, such as grasping how a distributed consensus algorithm works. It is contained within and part of the task itself.
- Extraneous load: The opposite end of the unnecessary cognitive burden spectrum. This is only friction, borne of the painful parsing of fragmented logs, complex boilerplate manifest configurations, or turbulent infrastructure.
- Germane load: The good load. This alludes to what is actively built in cognitive space to construct and maintain a highly detailed mental model or perform high-quality root-cause analysis (RCA).
Visualizing the Mental Capacity
The following chart explains how irrelevant stresses interfere with meaningful and efficient work.
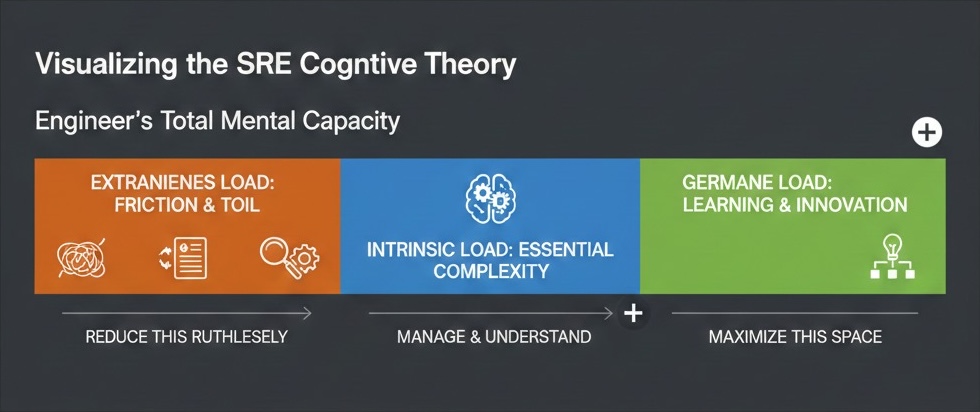
Fig 1: Visual representation of the SRE Cognitive Theory: Categorizing an engineer’s mental capacity into Extraneous Load, Intrinsic Load, and Germane Load.
The Technical Cost of Friction
Moving engineers to interface with low-level abstractions instead of operating at higher layers increases Extraneous Load. This exposes them to the 'Leaking Abstraction' issue, where the brain must manually manage the infrastructure's state, thereby depleting mental resources that could be used for critical problem-solving from the start of an incident.
High Extraneous Load (Manual and Error-Prone)
The task involves managing various cluster contexts, complicated JSON formatting, and internal container labels that do not significantly aid in the primary goal of service patching.
High friction: Mental overhead spent on syntax and environment state:
spec = {
"template": {
"spec": {
"containers": [
{
"name": "web",
"image": "v2.1.0"
}
]
}
}
}
print(spec)
Low Extraneous Load (The "Paved Road")
We can utilize a simple code or a layer of high-level abstraction to ease the load through focusing on the "what," hence the "how," we would foster the engineer to stay in a state of uninterrupted concentration. It is important for the tooling to manage the finer details to prevent syntax issues and reduce manual errors.
Low friction: Direct expression of intent with automated safety checks:
spec = {
"specification": {
"template_details": {
"specification": {
"container_list": [
{
"container_name": "web_app",
"version": "v2.1.0"
}
]
}
}
}
}
print(spec)Our strategic objective is to become known. As SREs move forward with the ruthless extermination of Arbitrary Load to add slack, they keep the germane entities intact, reducing distractions so SREs can conduct deep-dive learning and system hardening.
Identifying Cognitive "Hotspots" in the SRE Lifecycle
When establishing a reliability strategy that respects natural constraints, it is essential to locate where cognitive load collects. In high-velocity site reliability engineering (SRE) organizations, these "hotspots" usually reach a fever pitch in these three high-friction domains:
The Tooling Tax: The Cost of Context Switching
When an engineer flips between a time-series database for metrics and another cluster for stack traces, the "Tooling Tax" is levied. Each of these flips signifies a complex path towards the normalization of totally different query languages.
The mental effort involved in translating thoughts into code involves continuously switching between conceptual understanding and syntactic structures, rather than experiencing a unified view. Notice the radical shift in syntax for the same logical intent:
import requests
class PaymentAPIErrorInvestigation:
def __init__(self, prometheus_url, kibana_url, jaeger_url):
self.prometheus_url = prometheus_url
self.kibana_url = kibana_url
self.jaeger_url = jaeger_url
def check_metrics(self):
promql_query = (
"sum(rate(http_requests_total{service=\"payment-api\", status=~\"5..\"}[5m])) by (endpoint)"
)
print(f"Executing PromQL query for 500-series errors: {promql_query}")
response = requests.get(f"{self.prometheus_url}/api/v1/query", params={"query": promql_query})
return response.json()
def correlate_logs(self):
lucene_query = "service: \"payment-api\" AND status: [500 TO 599] NOT level: \"INFO\""
print(f"Executing Lucene/KQL query for 500-series errors: {lucene_query}")
response = requests.get(f"{self.kibana_url}/logs/_search", json={"query": lucene_query})
return response.json()
def check_traces(self):
spanql_query = "tags='{\"error\": \"true\", \"http.status_code\": \"500\", \"component\": \"proxy\"}'"
print(f"Executing SpanQL query for 500 errors in proxy component: {spanql_query}")
response = requests.get(f"{self.jaeger_url}/api/traces", params={"query": spanql_query})
return response.json()
def investigate(self):
print("Starting Payment API 500-series error investigation...\n")
# Checking metrics
metrics_data = self.check_metrics()
print(f"Metrics Data: {metrics_data}\n")
# Correlating logs
logs_data = self.correlate_logs()
print(f"Logs Data: {logs_data}\n")
# Checking traces
traces_data = self.check_traces()
print(f"Traces Data: {traces_data}\n")
print("Investigation completed successfully.")
# Initialize with appropriate server URLs
prometheus_url = "http://<prometheus-server>"
kibana_url = "http://<kibana-server>"
jaeger_url = "http://<jaeger-server>"
# Create an instance of the investigation class
investigation = PaymentAPIErrorInvestigation(prometheus_url, kibana_url, jaeger_url)
# Run the investigation
investigation.investigate()
Alert Fatigue: Signal-to-Noise Exhaustion
The constant high-volume alerting occupies the prefrontal cortex, the brain area responsible for advanced problem-solving, continuously. When on-duty personnel are bombarded with frequent, distracting alerts, their brains instinctively rely on simple, quick mental shortcuts.
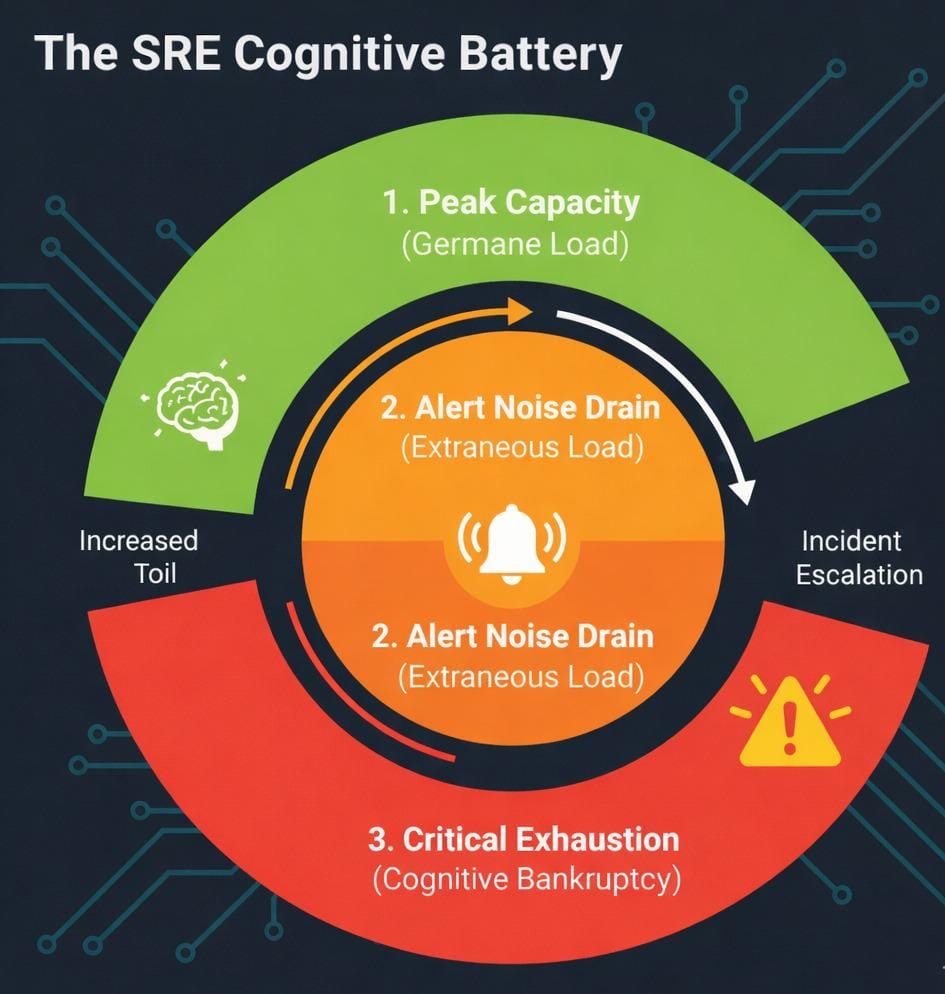
Figure 2: Visualizing the "Cognitive Battery," the depletion of mental bandwidth from peak analytical capacity to critical heuristic survival mode.
The Color Spectrum of Cognitive Load
- Green (Peak Capacity): High Germane load availability. The engineer is capable of conducting a thorough investigation into the root cause through deep-dive analysis and also strengthening the systems proactively through hardening.
- Yellow/Orange (Alert Noise Drain): High extraneous load. Mental activity is consumed by the activity of "Toil," which begins with alerts emanating from points of little context and then culminates in unique downtime to give a run for no practical purpose.
- Red (Critical Exhaustion): Cognitive bankruptcy. The brain, set to "survival mode" as its default, draws on muscle memory and takes the easy way out. It is at this point that high-risk manual mistakes and "Action Paralysis" are most frequent during outages.
Documentation Debt: The Paradox of Information
At its core, reliability is merely a search-and-retrieval problem. SREs during critical outages have to deal with the Information Paradox: they have access to vast amounts of documentation but have no actionable answers. A key cause of this issue is 'Documentation Debt,' which indirectly increases the mean time to understand (MTTU), the primary obstacle in the entire incident response procedure.
This can be fixed by applying the "30-Second Rule”: If a runbook or wiki requires more than 30 seconds to read for a clear, technical recovery step, it has failed as a reliability tool. In this instance, the documentation is no longer a support tool but a source of Extraneous Load, compelling the engineer to manually "garbage collect" on obsolete data while the system is down.
Strategy 1: Platform Engineering and the "Paved Road"
To scale reliability, it is necessary to go beyond manual intervention and embrace Platform Engineering as a cognitive shield. The decoupling of SRE from the system through the provision of Abstraction as a Service reduces the "surface area" that SRE must master. The implementation of "sensible defaults" reduces the mental effort required to enter a new service context; when every service follows the same deployment pattern and naming convention, the brain relies on pattern recognition rather than manual discovery.
The switch from "Ticket-Ops" to self-service infrastructure is indispensable for the flow state. The substitution of human-in-the-loop requests with API-driven workflows removes the context switching associated with high latency. This "Paved Road" strategy guarantees that the most reliable way to deploy is also the easiest, thus transforming the platform into a reliability engine that automatically handles Extraneous Load.
Strategic Shift: From Low-Level Primitives to High-Level Intent
The transition from infrastructure drudgery management to self-service and high-level abstraction is expounded upon in the comparisons below:
import subprocess
class RDSInstanceCreator:
def __init__(self, db_identifier, db_class, engine, storage, security_group_id, publicly_accessible):
self.db_identifier = db_identifier
self.db_class = db_class
self.engine = engine
self.storage = storage
self.security_group_id = security_group_id
self.publicly_accessible = publicly_accessible
def create_rds_instance(self):
print(f"Creating RDS instance for {self.db_identifier}...")
# AWS CLI command to create RDS instance
aws_command = [
"aws", "rds", "create-db-instance",
"--db-instance-identifier", self.db_identifier,
"--db-instance-class", self.db_class,
"--engine", self.engine,
"--allocated-storage", str(self.storage),
"--vpc-security-group-ids", self.security_group_id,
"--publicly-accessible", str(self.publicly_accessible).lower()
]
# Execute the command
subprocess.run(aws_command, check=True)
print(f"RDS instance {self.db_identifier} created successfully.")
class PavedRoadRDSCreator:
def __init__(self, service_name, environment, tier):
self.service_name = service_name
self.environment = environment
self.tier = tier
def create_rds_instance(self):
print(f"Creating RDS instance for service: {self.service_name} ({self.environment} environment, {self.tier} tier)...")
# Simulate the self-service command
platform_command = f"platform create rds --service {self.service_name} --env {self.environment} --tier {self.tier}"
# Print the simulated command
print(f"Simulated command: {platform_command}")
# Here, you can call a method to execute the real service if needed.
# For example: subprocess.run(platform_command, shell=True)
# Old: Manual Infrastructure Setup
rds_creator_old = RDSInstanceCreator(
db_identifier="payments-db-prod",
db_class="db.t3.large",
engine="postgres",
storage=20,
security_group_id="sg-0a1b2c3d",
publicly_accessible=False
)
rds_creator_old.create_rds_instance()
# New: Self-Service Infrastructure Setup
rds_creator_new = PavedRoadRDSCreator(service_name="payments", environment="prod", tier="critical")
rds_creator_new.create_rds_instance()
The move to platform-escalated technical execution frees SRE minds to focus on high-level system behavior and architectural hardening.
Strategy 2: Modern Observability and AIOps
The journey from "Monitoring" to "Modern Observability" signifies a shift from tracking certain outputs to the introspection of hidden processes. To preserve the cognitive energy of the SREs, the move must be from raw data dumps to intent-based insights.
1. AIOps as a Noise Filter
As a crucial step in templating the Extraneous Load, AIOps is not an "installation that automatically solves problems." Thousands of flapping events can coalesce into a single high-signal incident by reasoning with an extreme machine-learning capability for anomaly correlation and deduplication. This ensures that, in the event of an outage, the first interaction an engineer has is not log-reviewing, which can be a needless hassle.
2. Service Maps: Exploiting Spatial Memory
The human brain's processing speed for visual data exceeds that for text by a factor of 60,000. This neatly sidesteps any need for an SRE to mentally reconstruct a microservices architecture from log lines, so long as the spatial memory retained through the Dynamic Service Maps can immediately show where a failure occurred.
3. Curated, Incident-Specific Dashboards
Universal dashboards often generate cognitive resistance during use. Modern observability platforms should provide contextual views that, whenever an SLO is breached, will self-trigger. For instance, if the "Payment Latency" SLO is frowning, the SRE should not be shown CPU metrics for "Marketing Blog"; rather, they would see just the crucial telemetry data for the payment path. By curating visual insights from vast, high-cardinality data, we can reduce MTTU (Mean Time to Understand) and prevent cognitive brownout during critical escalations.
Figure 3: Transforming high-cardinality telemetry into high-signal insights through automated correlation and visual topology.
Strategy 3: Human-Centric SRE Practices
We need to shift our thinking from managing machines to managing people to maintain reliability. The human-centric SRE approach considers mental capacity the most vital resource in the system.
- Bounded-context teams, by providing roles with essential leadership, bring the right tools and designate the right gaps such that SRE remains focused on the existing problem landscape.
- Toil Budgets: Human mental energy must be viewed as a limited resource, like an Error Budget. If "Toil"—doing repetitive, manual, low-value work — crosses a defined threshold, the team must stop feature work and devote itself to reducing "cognitive debt."
- The "30-Second Rule": Any critical technical step for recovery must be deduced and acted upon within the first 30 seconds after an engineer is paged. If an SRE is taking minutes to find a runbook, documentation has failed, contributing to Extraneous Load.
Measuring Success: Metrics That Matter
Typical SLIs/SLOs are lagging indicators of the system's health; we need indicators of Engineer Health.
- Developer experience (DevEx) and MTTL: The mean time to learn (MTTL) measures the time taken for a cross-trained engineer to become incident-ready on the new service. High MTTL means the system is too complex to operate reliably.
- Context-switching frequency: To preserve the SRE flow state, the "Interruption Rate" is tracked frequently. A fast-paced context-switching between non-critical tasks and deep work is the primary driver of cognitive bankruptcy.
Implementation: Tracking Context-Switching via CLI
The script below, as an example, shows how companies could systematically track "interruptions" by recording non-essential manual interventions during working sessions, rather than during deep work.
# SRE Context Tracker - Measuring Cognitive Interruptions(PYTHON)
import time
def log_event(event_type, duration_minutes):
"""
Tracks whether work is 'Flow State' (Germane) or 'Interruption' (Extraneous).
Aim for a Flow: Interruption ratio of > 4:1.
"""
print(f"Logging {event_type} for {duration_minutes}m...")
# In a real scenario, this would push to an internal DevEx dashboard
# to calculate the 'Interruption Rate' metric.
# Example: An SRE shift
log_event("DEEP_WORK_SYSTEM_HARDENING", 120) # Germane Load
log_event("JIRA_TICKET_INTERRUPTION", 15) # Extraneous Load (Context Switch)
log_event("SLO_DASHBOARD_CURATION", 45) # Germane Load
Looking into human-centric metrics allows us to invest in High-Availability Cognition so that, whenever systems fail, humans are prepared to make sense of these failures and resolve them.
Conclusion: The Future of SRE Is Socio-Technical
The development of site reliability engineering has reached a crucial point where machine scalability is itself insufficient. One must argue that reliability is not a simple feature of our code or our cloud infrastructure, but a sociotechnical property of the whole system, where the human mind lies at its foundation. Working to build a reliable system challenges users to consider the human brain as a primary component with fixed biological constraints, and to make direct claims that our technological decisions are not allowed to go beyond human reasoning.
Throwing millions of dollars at scaling the clusters, which are forever optimized with autoscalers and database shards for near-infinite traffic, is all for naught if the humans behind these systems operate under cognitive bankruptcy. We need to turn our full focus on high-availability cognition to scale engineers' ability to think clearly, recognize patterns, and maintain and quickly evolve their mental models of the systems they operate.
Progress begins with a new outlook during key learning opportunities. Consider conducting a 'Cognitive Load Audit' as part of our upcoming post-incident review or after-action report. Do not merely ask what broke; ask what made the problem difficult to understand. By identifying and ruthlessly automating the extraneous friction found during these audits, we can ensure that our systems remain not only up and running but also truly understandable and resilient in the face of ever-increasing complexity.
Opinions expressed by DZone contributors are their own.
Comments