Designing Configuration-Driven Apache Spark SQL ETL Jobs with Delta Lake CDC
Simplify complex ETL pipelines and enable scalable, maintainable data processing with Spark SQL and Delta Lake Change Data Capture.
Join the DZone community and get the full member experience.
Join For FreeModern data pipelines demand flexibility, maintainability, and efficient incremental processing. Hardcoding transformations into Spark applications leads to technical debt and brittle pipelines. A configuration-driven approach separates business logic from execution, allowing easy changes, collaboration between developers and analysts, and promoting scalable ETL workflows.
In this article, we'll explore how to build config-based Spark SQL ETL jobs that integrate Delta Lake Change Data Capture (CDC) for efficient upserts.
Why Configuration-Driven Spark SQL ETL?
Benefits include:
- Separation of Concerns: Decouple SQL logic and business rules from code
- Flexibility: Modify queries, schemas, and parameters via configuration.
- Non-Developer Friendly: Analysts can update configurations without coding.
- Incremental Processing: Efficiently handle changes using CDC and UPSERTS.
- Environment Agnostic: Promote jobs across dev, staging, and production with simple config updates.
- Version Control: Track changes through configuration repositories.
Understanding Spark SQL in ETL Workflows
Apache Spark SQL is a distributed SQL query engine that runs on top of Apache Spark. It allows querying structured and semi-structured data using SQL or a DataFrame API while leveraging Spark’s parallelism and scalability.
Key strengths for ETL:
- Distributed Processing: Parallelizes SQL queries across a cluster.
- Unified Data Access: Supports multiple file formats (Parquet, Delta, Avro, JSON, etc.).
- Performance Optimizations: Catalyst optimizer rewrites queries for efficiency, and Tungsten engine enhances execution.
- Ease of Integration: Compatible with data lakes, data warehouses, and BI tools.
- Temporary Views: Allows you to register DataFrames as SQL-accessible views, enabling SQL transformations.
By using configurations to manage SQL queries, even non-developers can leverage Spark SQL’s power without needing to write code.
What Is Delta Lake CDC?
Delta Lake adds ACID (Atomicity, Consistency, Isolation, Durability) transactions and versioning to data lakes built on top of Apache Spark.
Change Data Capture (CDC) in Delta Lake allows:
- Tracking Row-Level Changes: Inserts, updates, deletes between table versions.
- Efficient Incremental Loads: Process only changed data, avoiding full table scans.
- Historical Change Querying: Use the
table_changesfunction to review or replay changes. - Simplified UPSERTS: Delta Lake’s
MERGE INTOSQL command simplifies incremental updates.
Advantages of using Delta CDC:
- Performance: Reduces data scanning and compute time.
- Cost Efficiency: Lowers the operational cost of updating large tables.
- Data Consistency: ACID compliance ensures reliable data updates.
Core Architecture
The architecture is made up of four primary layers working together.
Key Components:
- Configuration Files: Define sources, transformations, and targets.
- Spark SQL ETL Engine: Reads config, applies SQL queries, executes jobs.
- Delta Lake CDC: Enables row-level change capture for efficient upserts.
- Data Lake/Warehouse: Stores output tables.
Configuration File Example (YAML)
sources:
customers_changes:
cdc: true
table: customers
starting_version: 10
transformations:
- name: upsert_customers
type: merge
query: |
MERGE INTO customers AS target
USING customers_changes AS source
ON target.customer_id = source.customer_id
WHEN MATCHED AND source._change_type = 'delete' THEN DELETE
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *;
targets:
upsert_customers:
format: delta
path: /data/processed/customers
upsert_keys:
- customer_id
Let’s break it down to details.
1. Configuration Files (Control Layer)
Purpose:
Define all ETL logic externally from the application code.
What’s inside:
- Sources: Where data comes from (
Deltatables,Parquet,CSV, etc.). Can also specifyCDCmode and starting version. - Transformations:
SQLqueries or merge operations to apply. - Targets: Where to write results, including
UPSERTkeys for DeltaMERGE.
Benefits:
- No need to rewrite code for changes in source, target, or logic.
- Supports dynamic pipeline updates by modifying
YAMLorJSONfiles only. - Empowers both developers and analysts.
2. Spark SQL ETL Engine (Execution Layer)
Purpose:
Interprets the configuration and executes the ETL logic.
Main Functions:
- Load Sources:
- If CDC is enabled → use
table_changes()to read only changes. - If not → load the full data from the specified path or table.
-
Register Temporary Views:
So Spark SQL queries can reference them easily. - Execute Transformations:
- Runs SQL queries.
- Executes
MERGEstatements forUPSERTlogic where specified.
- Write Targets:
- If
UPSERTkeys exist → programmatically apply Delta Lakemerge()(for dynamic upserts). - Otherwise → overwrite the target.
Advanced Features Supported:
- Schema evolution
(autoMerge.enabled = true). - Dynamic switching between
overwriteandUPSERT. - Handles both full-refresh and incremental loads in the same engine.
3. Delta Lake CDC (Incremental Data Layer)
Purpose:
Enable efficient incremental processing of data changes rather than full loads.
Key Concepts:
-
table_changes():
Extracts inserted, updated, and deleted rows between versions of a Delta table. - Change Types:
_change_type = 'insert'_change_type = 'update_postimage'_change_type = 'delete'
-
MERGE INTO(SQL):
Executes UPSERT logic, applying changes into the target Delta table. -
DeltaTable.merge()(PySpark API):
Alternative to SQLMERGEfor programmatic upserts.
Why It Matters: Processing only changed data saves compute time and reduces cloud storage IO costs.
4. Data Lake / Warehouse (Storage Layer)
Purpose:
Store the processed data for downstream consumption (analytics, BI tools, reporting, ML training).
Can Be:
- Delta Tables → support versioning, ACID transactions, time travel.
Parquet/ORC→ for raw or snapshot data.- External Warehouses → Synapse, Snowflake, BigQuery, Redshift (if desired).
Supports:
- Schema enforcement and evolution.
- Time travel (querying previous data versions).
- Fine-grained data updates through
UPSERT.
Spark SQL ETL Engine Pseudocode
import yaml
from pyspark.sql import SparkSession
from delta.tables import DeltaTable
def load_config(path):
with open(path, 'r') as file:
return yaml.safe_load(file)
def main(config_path):
spark = SparkSession.builder \
.appName("Config-Based ETL with Delta CDC") \
.config("spark.databricks.delta.schema.autoMerge.enabled", "true") \
.getOrCreate()
config = load_config(config_path)
# Step 1: Load sources and create views
for src, details in config['sources'].items():
if details.get('cdc'):
cdc_df = spark.sql(
f"SELECT * FROM table_changes('{details['table']}', {details['starting_version']})"
)
cdc_df.createOrReplaceTempView(src)
else:
df = spark.read.format(details['format']).load(details['path'])
df.createOrReplaceTempView(src)
# Step 2: Apply transformations
for transform in config['transformations']:
if transform.get('type') == 'merge':
merge_sql = transform['query']
spark.sql(merge_sql)
else:
df = spark.sql(transform['query'])
df.createOrReplaceTempView(transform['name'])
# Step 3: Write targets (UPSERT or overwrite)
for tgt, details in config['targets'].items():
df = spark.table(tgt)
target_path = details['path']
if details.get('upsert_keys'):
upsert_keys = details['upsert_keys']
if DeltaTable.isDeltaTable(spark, target_path):
delta_target = DeltaTable.forPath(spark, target_path)
merge_condition = " AND ".join(
[f"target.{key} = updates.{key}" for key in upsert_keys]
)
delta_target.alias("target").merge(
source=df.alias("updates"),
condition=merge_condition
).whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
else:
df.write.format(details['format']).mode('overwrite').save(target_path)
else:
df.write.format(details['format']).mode('overwrite').save(target_path)
spark.stop()
if __name__ == "__main__":
main("etl_config.yaml")Flow Diagram: Dynamic UPSERT Logic
The flow for the above upsert logic:
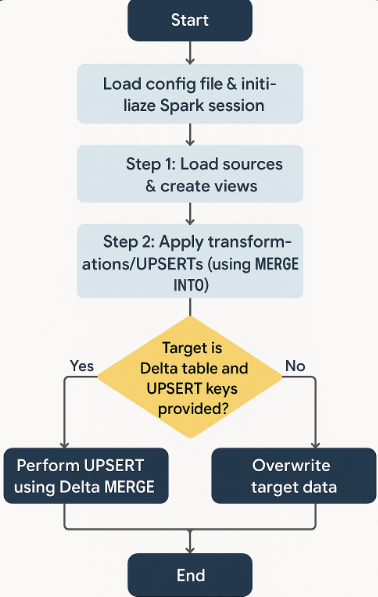
Advanced Features to Consider
- Parameterization: Runtime value injection into queries.
- Validation Layer: Schema checks and join validations.
- Error Handling & Logging: Detailed job logging and error capture.
- Workflow Orchestration: Compatible with
Airflow,Dagster, orPrefect. - Data Quality Checks: Supports Deequ or Great Expectations.
- Delta CDC for Incremental UPSERTS: Read row-level changes and update targets efficiently.
- Schema Evolution: Auto-merge new columns into Delta tables.
Benefits Comparison
|
Feature |
Traditional ETL |
Config-Driven Spark SQL ETL + Delta CDC |
|
Flexibility |
Low |
High |
|
Incremental Processing |
Complex or unavailable |
Native with Delta Lake |
|
Maintainability |
Complex code changes |
Simple config updates |
|
Collaboration |
Developer-only |
Developers + Analysts |
|
Deployment Time |
Slow |
Fast |
Conclusion
By combining configuration-driven Spark SQL ETL with Delta Lake CDC and UPSERTS, you can create scalable, maintainable, and efficient data pipelines. This architecture empowers both developers and analysts to iterate quickly while maintaining control, flexibility, and optimal performance in your data workflows.
The future of data engineering lies in abstracting complexity while embracing flexibility and scalability, and this pattern accomplishes exactly that.
Opinions expressed by DZone contributors are their own.
Comments