Understanding Apache Spark Join Types
Three join types in Spark data frame SQL operations are crucial for the performance of big data Apache Spark applications.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we are going to discuss three essential joins of Apache Spark.
The data frame or table join operation is most commonly used for data transformations in Apache Spark. With Apache Spark, a developer can use joins to merge two or more data frames according to specific (sortable) keys. Writing a join operation has a straightforward syntax, but occasionally the inner workings are obscured. Apache Spark internal API suggests several algorithms for joins and selects one. A basic join operation could become costly if you do not know what these core algorithms are or which one Spark uses.
Spark considers the size of the data frames while choosing a join algorithm. To simply choose the algorithm to implement, it will consider the join type, condition, and any clues and hints that were provided. The two main power join types that power Spark SQL joins are typically Sort Merge joins and Shuffle Hash joins. However, Broadcast Hash join is very important to performance if the size of one of the data frames is below a predetermined threshold.
Broadcast Hash Join (BHJ)
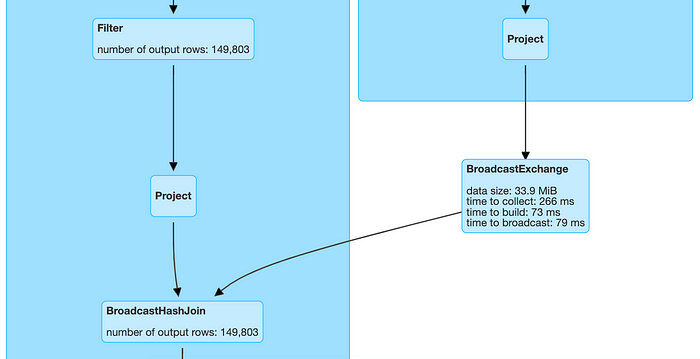
The data frame from one of the branches broadcasts to each node that contains the other data frame, as the above diagram illustrates. The final join operation is then carried out by Spark in each node. This is how Spark communicates per node.
When one of the data frame sizes is smaller than the threshold specified in ‘spark.sql.autoBroadcastJoinThreshold’, Spark employs the Broadcast Hash join.
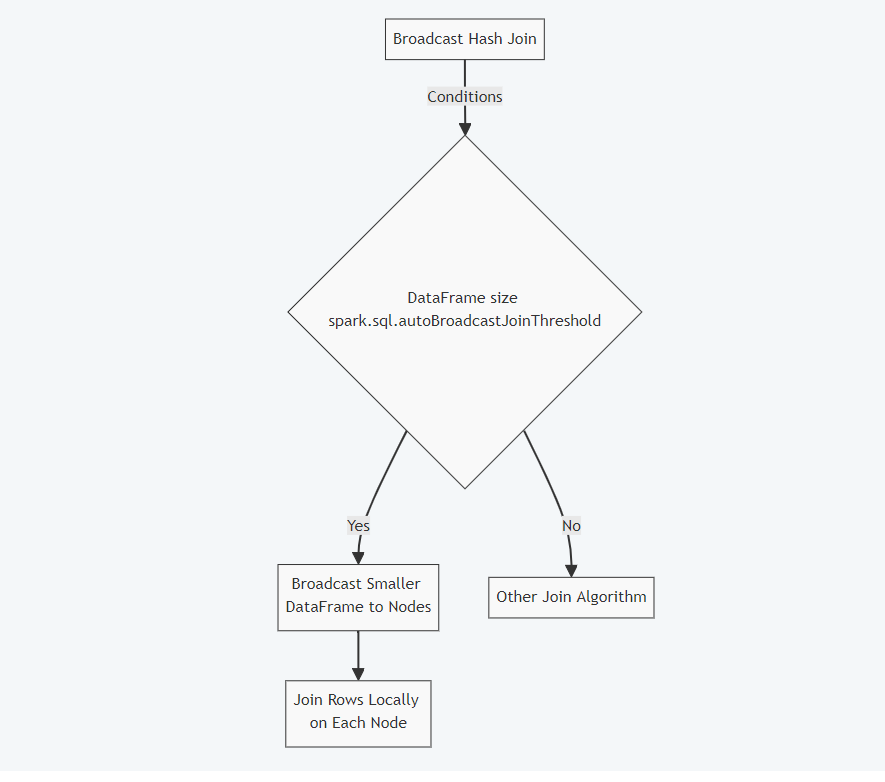
The Spark SQL property below can be used to alter its default value of 10 mb.
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 100 * 1024 * 1024)This technique means that no shuffle is needed on the other side of the join. In comparison to alternative algorithms that would need to perform the shuffle, if this other side is particularly large, not performing the shuffle will result in a noticeable speedup.
Large dataset broadcasts may potentially result in timeout issues. A broadcast operation's maximum duration, beyond which it fails, is set by the spark.sql.broadcastTimeout setting. Although five minutes is the default timeout value, it can be changed as follows:
spark.conf.set("spark.sql.broadcastTimeout", time_in_sec)Sort Merge Join (SMJ)
Spark API internal join algorithm uses Sort Merge Join if neither of the data frames can be broadcast. Spark shuffles the data throughout the cluster with this technique and employs the node-node communication strategy.
Both sides of the join must have the proper partitioning and order for the Sort Merge join to work. Typically, this is accomplished by sorting and shuffling in both join branches, as shown below.
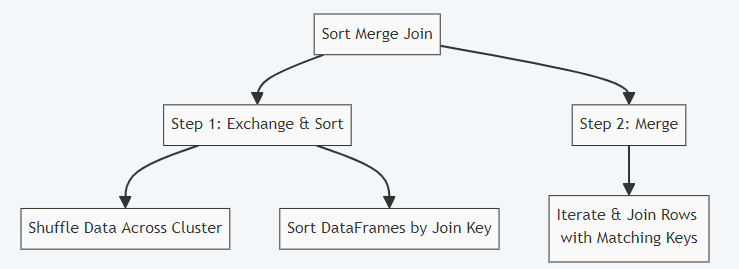
There are two steps in this algorithm. The datasets are exchanged and sorted in the first stage, and the sorted data is then merged in the second step by iterating over the elements and joining the rows with the same value based on the join key.
In theory, it is preferable to generate data frames from appropriately bucketed tables in order to avoid the very costly shuffle and sort operations. As a result, join execution is more effective.
Merge-Sort join is the default join algorithm. in Spark. The internal parameter "spark.sql.join.preferSortMergeJoin," which is set to true by default, is disabled by setting it to false.
Shuffled Hash Join (SHJ)
The map-reduce concept is the foundation of the Shuffle Hash join. The values of the join column are used as the output key, as it maps over the data frames. The data frames are then shuffled according to the output keys. Now, the same machine will contain the rows from several data frames that have the same keys. Spark thereby connects the data frames during the reduce step.
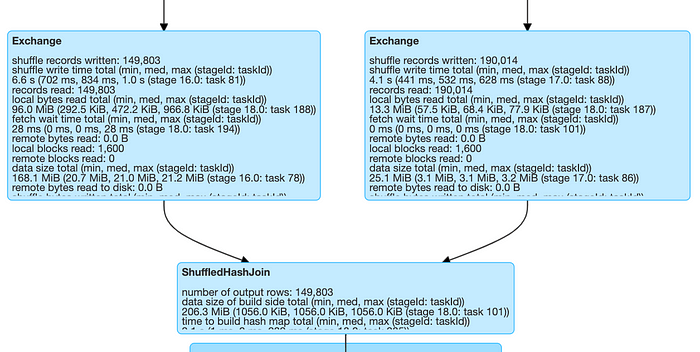
Since preferSortMergeJoin is set to true by default, Spark chooses SortMergeJoin over ShuffleHashJoin. On the other hand, even if preferSortMergeJoin is set to false, Spark will choose the shuffled hash join.
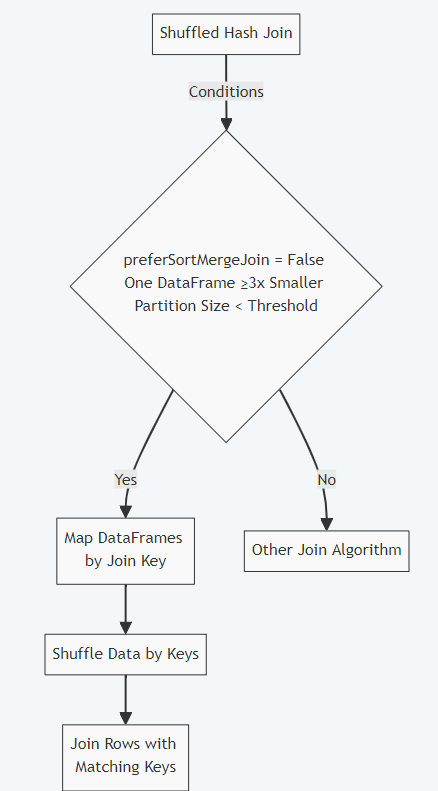
In the same way, Shuffle Hash join also requires the data to be partitioned correctly. Also, it will introduce a shuffle in both branches of the join. However, as opposed to the former, it doesn’t require the data to be sorted, and because of that, it has the potential to be faster than Sort Merge join.
Conclusion
Although joins in Apache Spark internally choose the best join algorithm, by hinting, developers can ask Spark to implement the corresponding join. Developers should not specify hints without understanding that data may lead to OutofMemoryError or build a HashMap for a large partition. On the other hand, Developers are not familiar with the underlying data; without specifying the hint, the developer might lose an opportunity to optimize the join operation.
Opinions expressed by DZone contributors are their own.
Comments