Connecting Apache Kafka With Mule ESB
Learn about the capabilities of the Apache Kafka message queuing system and how to integrate it with Mule ESB in this tutorial.
Join the DZone community and get the full member experience.
Join For Free1.0 Overview
Apache Kafka was originated with LinkedIn and later became an open-sourced Apache platform in 2011. Kafka is a message queuing system and is written in Java and Scala. Kafka is a distributed publish-subscribe messaging system that is designed to be fast, scalable, and durable.
Kafka has four core APIs:
The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems.
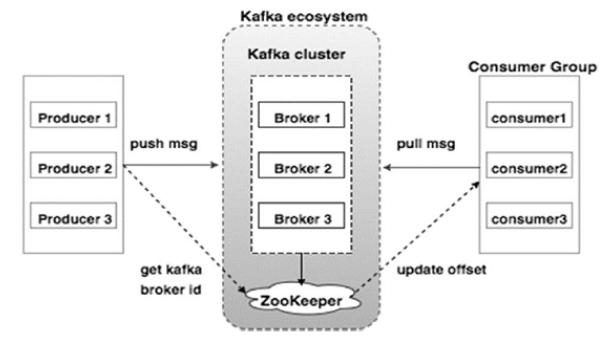
2.0 Components of Apache Kafka
Topic is the name of the category or feed where records have been published. Topics are always multi-subscriber as they can have zero or more consumers that subscribe to the data written to them.
Producers publish data to topics of their choice. It can publish data to one or more Kafka topics.
Consumers consume data from topics. Consumers subscribe to one or more topics and consume published messages by pulling data from the brokers.
Partition: Topics may have many partitions, so they can handle an arbitrary amount of data.
Partition offset: Each partitioned message has a unique id and it is known as an offset.
Brokers are simple system responsible for maintaining the published data. Each broker may have zero or more partitions per topic.
Kafka Cluster: Kafka's server has one or more brokers, called Kafka Cluster.
3.0 Apache Kafka Use Cases
Below are some use cases where Apache Kafka can be considered:
3.1 Messaging
In comparison to other messaging systems, Apache Kafka has better throughput and performance, partitioning, replication, and fault-tolerance, which makes it a good solution for large scale message processing applications.
3.2 Website Activity Tracking
Website activity like number of views, number of searches, or any other actions that users may perform is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases, including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
3.3 Metrics
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
3.4 Log Aggregation
Kafka can be used across an organization to collect logs from multiple services and make them available in a standard format to multiple consumers.
3.5 Stream Processing
Popular frameworks such as Storm and Spark Streaming read data from a topic, process it, and write processed data to a new topic where it becomes available for users and applications. Kafka’s strong durability is also very useful in the context of stream processing.
4.0 Setup Zookeeper on Windows Server
Now you will learn how to setup Zookeeper on Windows Server. Make sure JRE8 has been installed and the JAVA_HOME path is set up in the environment variable.
4.1 Download & Install Zookeeper
Zookeeper also plays a vital role, serving so many other purposes such as leader detection, configuration management, synchronization, detecting when a new node joins or leaves the cluster, etc.
Download ZooKeeper and extract it (e.g. zookeeper-3.4.10).
Go to your Zookeeper directory (e.g. C:\zookeeper-3.4.10\conf).
Rename the file zoo_sample.cfg to zoo.cfg.
Open zoo.cfg file in a text editor like Notepad or Notepad++.
Search for dataDir=/tmp/zookeeper and update path to dataDir=\zookeeper-3.4.10\data.
Add two environment variables:
a. Add System Variables ZOOKEEPER_HOME = C:\zookeeper-3.4.10
b. Edit System Variable named Path add ;%ZOOKEEPER_HOME%\bin;
By default, Zookeeper runs on port 2181 but you can change the port by editing zoo.cfg.
4.2 Starting Zookeeper
Open the command prompt and run the command zkserver and it will start Zookeeper on port localhost:2181.
5.0 Setup Apache Kafka on Windows Server
Now you will learn how to setup Apache Kafka on a Windows Server.
5.1 Download & Install Apache Kafka
Download Apache Kafka and extract it (e.g. kafka_2.11-0.9.0.0).
Go to your Kafka config directory (e.g. C:\kafka_2.11-0.9.0.0\config).
Open file server.properties in a text editor like Notepad or Notepad++.
Search for log.dirs=/tmp/kafka-logs and update path to log.dirs=C:\kafka_2.11-0.9.0.0\kafka-logs.
5.2 Starting the Apache Kafka Server
Open the command prompt and make sure you are at path C:\kafka_2.11-0.9.0.0.
Run the below command to start Kafka server.
.\bin\windows\kafka-server-start.bat .\config\server.properties
6.0 Creating a Topic on the Apache Kafka Server
Now we will create a topic with replication factor 1, as only one Kafka server is running.
Open command prompt and make sure you are at path C:\kafka_2.11-0.9.0.0\bin\windows.
Run the below command to create a topic.
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic muleesb7.0 Installing the Anypoint Kafka Connector
Ingest streaming data from Kafka and publish it to Kafka with this connector.
By default, the Kafka connector is not part of the Mule palette and you can install the Kafka connector by connecting to Anypoint Exchange from Anypoint Studio. You just need to accept the license agreement and at the end of installation, it will ask you to restart Anypoint Studio.
Streamline business processes and move data between Kafka and Enterprise applications and services with the Anypoint Connector for Kafka.

Kafka Connector enables out-of-the-box connectivity with Kafka, allowing users to ingest real-time data from Kafka and publish it to Kafka.
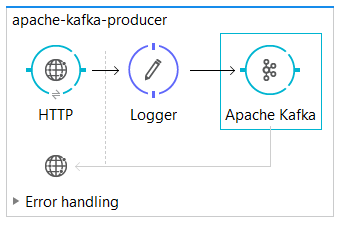
8.0 Integrating Apache Kafka With Mule ESB as Producer
We will implement flow that will publish a message to Apache Kafka server.
Place the HTTP connector at the message source and configure it.
Drag and drop the Apache Kafka connector and configure it by clicking on the add button. Configure Bootstrap Servers, Producer Properties File, and Consumer Properties File. Press OK.
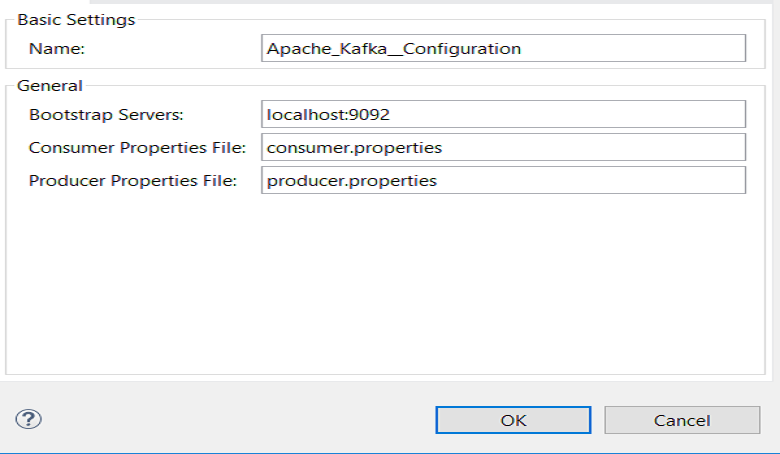
| Field | Description |
Bootstrap Server |
Comma-separated host-port pairs for establishing the initial connection to the Kafka cluster — same as |
Consumer Properties File |
Path to properties file where you can set the Consumer — similar to what you provide to Kafka command line tools. If you do not specify a value for |
Producer Properties File |
Path to properties file where you can set the producer — similar to what you provide to Kafka command line tools. If you do not specify a value for bootstrap.serverswithin properties file, the value provided with Bootstrap Servers is going to be used. Also if you do not specify a value for key.serializerand value.serializerthey will be set to org.apache.kafka.common.serialization.StringSerializer. |
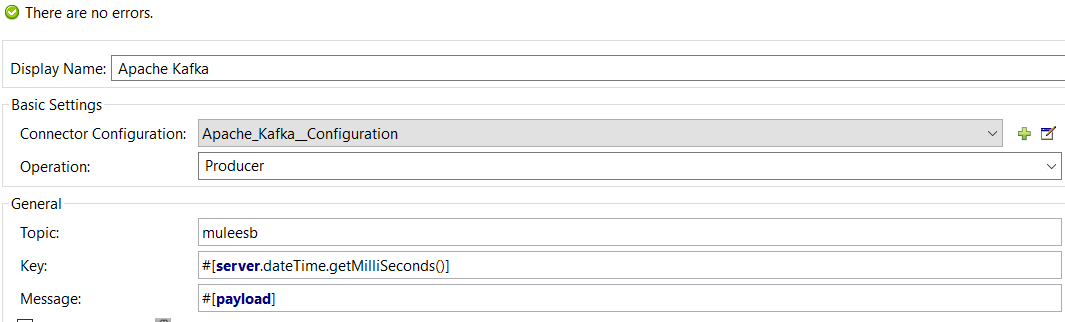
Configure Operation to Producer, topic name, and key (it is a unique key that needs to publish with message).
Add consumer.properties and producer.properties files to the Mule application build a path (src/main/resources). Both properties files can be found at location C:\kafka_2.11-0.9.0.0\config.
9.0 Integrating Apache Kafka With Mule ESB as Consumer
We will implement a flow that will consume messages from the Apache Kafka server.
Place the Apache Kafka connector at the message source and configure it by clicking on the add button. Configure Bootstrap Servers, Producer Properties File, and Consumer Properties File as shown above. Press OK.
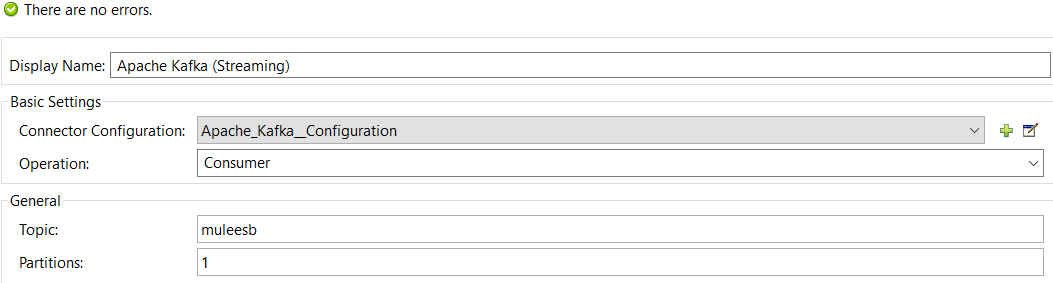
Configure Operation to Consumer, topic name, and Partitions (the number of partitions you have given while creating the topic).
Drag and drop the file connector and configure it. This will be used to save the message consumed from Apache Kafka server.
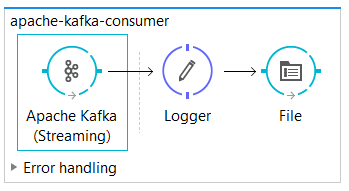
10.0 Mule Flow [Code]
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:file="http://www.mulesoft.org/schema/mule/file" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns:apachekafka="http://www.mulesoft.org/schema/mule/apachekafka" xmlns:tracking="http://www.mulesoft.org/schema/mule/ee/tracking" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:spring="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/ee/tracking http://www.mulesoft.org/schema/mule/ee/tracking/current/mule-tracking-ee.xsd
http://www.mulesoft.org/schema/mule/apachekafka http://www.mulesoft.org/schema/mule/apachekafka/current/mule-apachekafka.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd">
<http:listener-config name="HTTP_Listener_Configuration" host="0.0.0.0" port="8081" doc:name="HTTP Listener Configuration"/>
<apachekafka:config name="Apache_Kafka__Configuration" bootstrapServers="localhost:9092" consumerPropertiesFile="consumer.properties" producerPropertiesFile="producer.properties" doc:name="Apache Kafka: Configuration"/>
<flow name="apache-kafka-producer">
<http:listener config-ref="HTTP_Listener_Configuration" path="/kafka" allowedMethods="POST" doc:name="HTTP"/>
<logger message="Message Published : #[payload]" level="INFO" doc:name="Logger"/>
<apachekafka:producer config-ref="Apache_Kafka__Configuration" topic="muleesb" key="#[server.dateTime.getMilliSeconds()]" doc:name="Apache Kafka"/>
</flow>
<flow name="apache-kafka-consumer">
<apachekafka:consumer config-ref="Apache_Kafka__Configuration" topic="muleesb" partitions="1" doc:name="Apache Kafka (Streaming)"/>
<logger message="Message Consumed : #[payload]" level="INFO" doc:name="Logger"/>
<file:outbound-endpoint path="src/test/resources/consumer" responseTimeout="10000" doc:name="File"/>
</flow>
</mule>
11.0 Testing
You can use Postman to test the application. Send the POST request to the producer flow and it will publish the message to Apache Kafka. Once the message is published, it will be consumed by the consumer flow and save the message to the specified directory. For more details on testing, please watch the below demonstration video.
12.0 Connecting Apache Kafka With Mule ESB [Video]
13.0 Useful Apache Kafka Commands
Start Zookeeper: zkserver
Start Apache Kafka: .\bin\windows\kafka-server-start.bat .\config\server.properties
Start Producer: kafka-console-producer.bat --broker-list localhost:9092 --topic topicName
Start Consumer: kafka-console-consumer.bat --zookeeper localhost:2181 --topic topicName
Create Topic: kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topicName
List Topics: kafka-topics.bat --list --zookeeper localhost:2181
Describe Topic: kafka-topics.bat --describe --zookeeper localhost:2181 --topic topicName
Consume messages from beginning: kafka-console-consumer.bat --zookeeper localhost:2181 --topic topicName --from-beginning
Delete Topic: kafka-run-class.bat kafka.admin.TopicCommand --delete --topic topicName --zookeeper localhost:2181
14.0 Conclusion
Apache Kafka is a very powerful distributed, scalable, and durable message queuing system. Mule ESB provides the Apache Kafka connector that can publish message to Kafka server and consume message from Kafka server (i.e. can act as producer as well as consumer.
Now you know how to integrate or connect Apache Kafka with Mule ESB.
Opinions expressed by DZone contributors are their own.
Comments