Connecting an Autonomous Data Warehouse With Python
In this article, take a look at how to connect an autonomous data warehouse with Python and see a machine learning example.
Join the DZone community and get the full member experience.
Join For Free
In this article, I will connect to an Oracle database running in the cloud (Oracle Autonomous Data Warehouse) and make a simple regression application in python environment with a sample data taken from here.
First of all, I will make this application in Autonomous Data Warehouse (DB) which is offered as a service in Oracle Cloud. All I need is an Oracle Cloud account. You can get Autonomous Data Warehouse service, which is one of the services of Always Free (Oracle Free Tier), free of charge and you can provision and use it on the Cloud in minutes without any installation. You can follow the link for detailed information.
You can start Autonomous Data Warehouse service via Oracle Cloud Infrastructure as shown in the video below.
The second component I need is to install the cx_oracle package in python to connect to the Oracle database in the Cloud from my local environment. The next step is to install an Oracle Client on my machine.
You can do the above mentioned installations by following the link.
I need a data set and a problem to implement it. I choose Boston Housing Prices as a problem. To solve this problem, I will construct a regression model. I get the data set from Kaggle (Boston Housing).
Let's first examine the BOSTON_HOUSING dataset.
| Column Name | Description | Data Type |
| crim | per capita crime rate by the town. | Number |
| zn | the proportion of residential land zoned for lots over 25,000 sq.ft. | Number |
| indus | the proportion of non-retail business acres per town. | Number |
| chas | Charles River dummy variable (= 1 if tract bounds river; 0 otherwise). | Number |
| nox | nitrogen oxides concentration (parts per 10 million). | Number |
| rm | average number of rooms per dwelling. | Number |
| age | the proportion of owner-occupied units built before 1940. | Number |
| dis | the weighted mean of distances to five Boston employment centers. | Number |
| rad | index of accessibility to radial highways. | Number |
| tax | full-value property-tax rate per $10,000. | Number |
| ptratio | the pupil-teacher ratio by the town. | Number |
| black | 1000(Bk – 0.63)^2 where Bk is the proportion of blacks by the town. | Number |
| lstat | lower status of the population (percent). | Number |
| medv | the median value of owner-occupied homes in $1000s. | Number |
Now that we have reviewed the details with our dataset, let's load the BOSTON_HOUSING that we downloaded to our Oracle database.
First, create the Oracle table in which we will load the data set (train.csv) that we downloaded.
xxxxxxxxxx
CREATE TABLE BOSTON_HOUSING
(
ID NUMBER,
CRIM NUMBER,
ZN NUMBER,
INDUS NUMBER,
CHAS NUMBER,
NOX NUMBER,
RM NUMBER,
AGE NUMBER,
DIS NUMBER,
RAD NUMBER,
TAX NUMBER,
PTRATIO NUMBER,
BLACK NUMBER,
LSTAT NUMBER,
MEDV NUMBER
);
xxxxxxxxxx
CREATE TABLE BOSTON_HOUSING_TEST
(
ID NUMBER,
CRIM NUMBER,
ZN NUMBER,
INDUS NUMBER,
CHAS NUMBER,
NOX NUMBER,
RM NUMBER,
AGE NUMBER,
DIS NUMBER,
RAD NUMBER,
TAX NUMBER,
PTRATIO NUMBER,
BLACK NUMBER,
LSTAT NUMBER,
MEDV NUMBER
);
Now that we have created our table, we will load the dataset we downloaded as CSV into the table; we have multiple methods to do this:
- Using Oracle External Table.
- Using Oracle SQL Loader.
- Using SQL-PL/SQL editors (Oracle SQL Developer, Toad, PL/SQL Developer, etc).
I will load the data set with the help of the editor I use. I use Oracle SQL Developer as an editor. With Oracle SQL Developer, you can load data as follows.
xxxxxxxxxx
SELECT * FROM BOSTON_HOUSING;
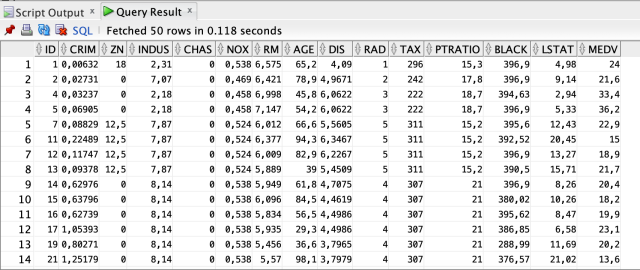
We have completed the dataset loading process.
When we observe the data, we see the details according to the various characteristics of the houses. Each row contains information on the specific characteristics of the house. Our basic parameters for regression analysis are as presented in this table. In this table, we predict the result of the regression analysis. The MEDV column is the target variable that we will use in this analysis.
Now let's start writing the necessary code on the Python side.
xxxxxxxxxx
import cx_Oracle as cx
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
#Connect to Autonomous Data Warehouse
con = cx.connect("ADMIN","yourPass","mltest_high")
query = 'SELECT * from boston_housing'
data_train = pd.read_sql(query, con=con)
query = 'SELECT * from boston_housing_test'
data_test = pd.read_sql(query, con=con)
With cx_oracle, we connected to ADW, and from there we extracted the data from the relevant tables into the data frame via python.
xxxxxxxxxx
data_train.head()
data_test.head()
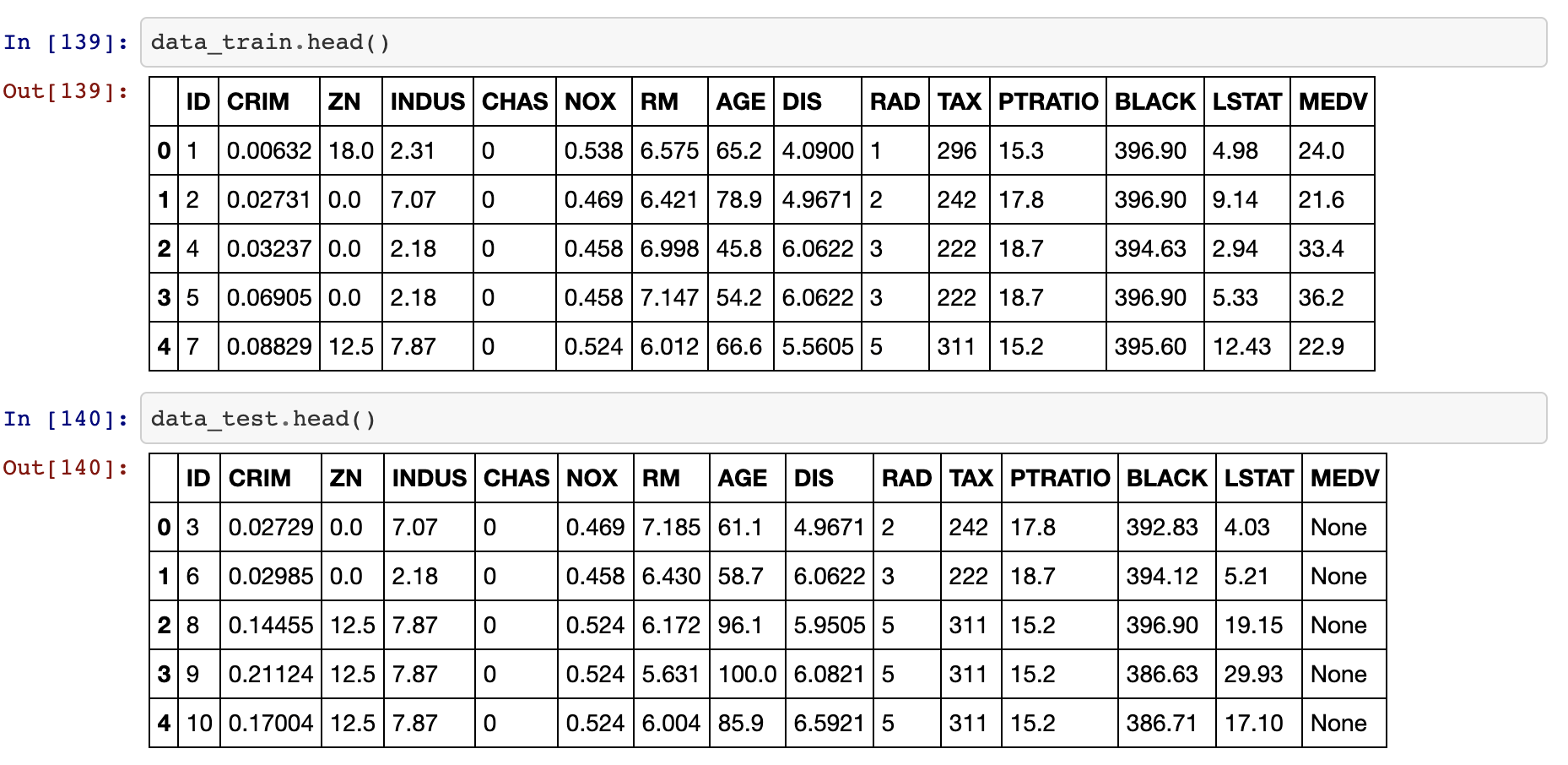
Now let's create and test our model with the data we have.
xxxxxxxxxx
######### Building Model with Boosting Method for Regression #######
from sklearn.ensemble import AdaBoostRegressor
X = data_train.iloc[:,1:14] # features
y = data_train.iloc[:,14:15] # target variable
#training
regr = AdaBoostRegressor(random_state=0, n_estimators=100)
regr.fit(X, y)
#see feature importance
regr.feature_importances_
#model test with test data set from oracle database (data_test df)
data_test.iloc[1:2,1:14] # take one record from data set

Now let's take a test record and make an estimate using the model we created for this record.
xxxxxxxxxx
test_rec = data_test.iloc[1:2,1:14]
testid = data_test.iloc[1:2,0:1] # get test record id for updating result in ADW (database)
id_final = int(test_id["ID"])
#predict value using model
res = regr.predict(test_rec)
pred_medv = res[0]
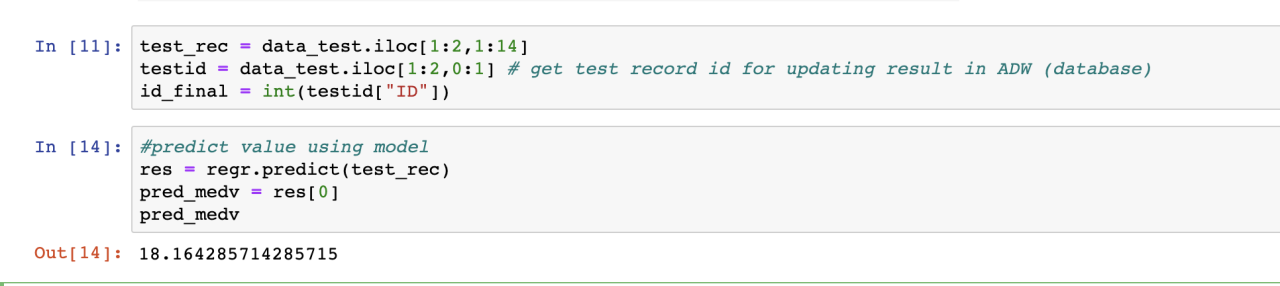
Now let's update the MEDV value of the estimated record in the database.
xxxxxxxxxx
#update database record on ADW
query = 'update boston_housing_test set medv =:result where id=:testrecid'
cur = con.cursor()
cur.execute(query,[pred_medv,id_final])
con.commit()
con.close()
Yes, as we have seen, we extracted data from the Cloud database with Python and then used it in the training of the model we built with sklearn and tested it with a new value.
Opinions expressed by DZone contributors are their own.
Comments