Constructing Real-Time Analytics: Fundamental Components and Architectural Framework — Part 1
Real-time analytics provide immediate insights on large data sets so data architects can make swift decisions and stay on the cutting edge of their industry.
Join the DZone community and get the full member experience.
Join For FreeThe old adage "patience is a virtue" seems to have lost its relevance in the fast-paced world of today. In an era of instant gratification, nobody is inclined to wait. If Netflix buffering takes too long, users won't hesitate to switch platforms. If the closest Lyft seems too distant, users will readily opt for an alternative.
The demand for instant results is pervading the realm of data analytics as well, particularly when dealing with large datasets. The capacity to provide immediate insights, make swift decisions, and respond to real-time data without any delay is becoming crucial. Companies like Netflix, Lyft, Confluent, and Target, along with thousands of others, have managed to stay at the forefront of their industries partially due to their adoption of real-time analytics and the data architectures that facilitate such instantaneous, analytics-driven operations.
This article is tailored for data architects who are beginning to explore the realm of real-time analytics. It delves into the concept, outlining the fundamental components and the preferred data architecture models that are commonly adopted in the industry.
What Does the Term ‘Real-Time Analytics’ Signify?
Real-time analytics are characterized by two essential features: the freshness of data and the speed of deriving insights. They come into play in applications that are highly sensitive to latency, where the time taken from a new event occurring to generating insight from it is measured in mere seconds.
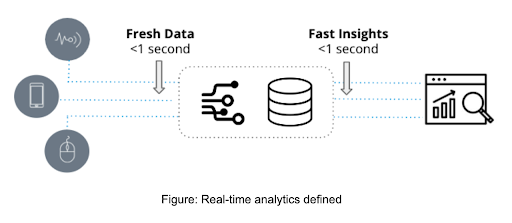
On the other hand, traditional analytics, often referred to as business intelligence, provide static overviews of business data primarily for reporting. This approach typically relies on data warehouses like Snowflake or Amazon Redshift, with visualization facilitated through BI tools such as Tableau or PowerBI.
Unlike traditional analytics that utilize historical data that could be hours, days, or even weeks old, real-time analytics harness the most recent data. This approach is often employed in operational workflows that require swift responses to potentially intricate queries.
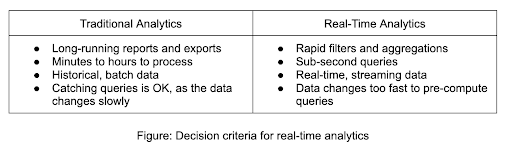
For instance, traditional analytics would be suitable for a supply chain executive seeking to identify historical trends in monthly inventory changes. This is because the executive can afford to wait a little longer for the report to process. On the other hand, a security operations team aiming to detect and investigate anomalies in network traffic would benefit from real-time analytics. This is due to their need to swiftly sift through thousands to millions of real-time log entries in less than a second to identify patterns and scrutinize unusual activities.
Is Selecting the Appropriate Architecture Significant?
Numerous database vendors claim to be adept at real-time analytics, and they do indeed deliver on this front to some extent. Consider weather monitoring as an example. Suppose the use case demands temperature samples every second from thousands of weather stations, alongside queries for threshold-based alerts and some trend analysis. This would be a straightforward task for databases like SingleStore, InfluxDB, MongoDB, or even PostgreSQL. You could create a push API that directs the metrics straight to the database, execute a simple query, and just like that, you've got real-time analytics.
When do real-time analytics truly become challenging? In the preceding scenario, the data set is quite compact, and the analytics are rather straightforward. A single temperature event is produced just once every second, and a SELECT with a WHERE statement to gather the most recent events doesn't demand substantial processing capacity. This is a breeze for any time series or OLTP database.
The true test of databases begins when the number of events ingested increases significantly, the queries encompass numerous dimensions, and the data sets expand into terabytes or even petabytes. One might consider Apache Cassandra for high-throughput ingestion, but its analytics performance might not meet expectations. What if your analytics requirements involve amalgamating multiple real-time data sources on a large scale? The course of action then becomes a challenge.
Here are some considerations to think about that’ll help define the requirements for the right architecture:
- Are you working with high events per second, from 1000s to millions?
- Is it important to minimize latency between events created to when they can be queried?
- Is your total dataset large, and not just a few GB?
- How important is query performance – sub-second or minutes per query?
- How complicated are the queries, exporting a few rows or large-scale aggregations?
- Is avoiding downtime of the data stream and analytics engine important?
- Are you trying to join multiple event streams for analysis?
- Do you need to place real-time data in context with historical data?
- Do you anticipate many concurrent queries?
Should any of these factors be significant for your use case, we will delve into the design of an appropriate architectural solution in Part 2 of this article.
Opinions expressed by DZone contributors are their own.
Comments