Constructing Real-Time Analytics: Fundamental Components and Architectural Framework — Part 2
The fundamental components of real-time analytics are event streaming and a specialized database that can manage large amounts of data in less than a second.
Join the DZone community and get the full member experience.
Join For FreeIn Part 1, I discussed the growing demand for real-time analytics in today's fast-paced world, where instant results and immediate insights are crucial. It compared real-time analytics with traditional analytics, highlighting the freshness of data and the speed of deriving insights as key features. The article emphasized the need for selecting the appropriate data architecture for real-time analytics and raised considerations such as events per second, latency, dataset size, query performance, query complexity, data stream uptime, joining multiple event streams, and integrating real-time and historical data. And I teased the following Part 2 of the article, which delves into designing an appropriate architectural solution for real-time analytics.
Building Blocks
To effectively leverage real-time analytics, a powerful database is only part of the equation. The process begins with the capacity to connect, transport, and manage real-time data. This introduces our first foundational component: event streaming.
Event Streaming
In scenarios where real-time responsiveness is crucial, the time-consuming nature of batch-based data pipelines falls short, leading to the rise of messaging queues. Old-school message delivery relied on tools such as ActiveMQ, RabbitMQ, and TIBCO. However, the modern approach to this challenge is event streaming, implemented using platforms like Apache Kafka and Amazon Kinesis.
Apache Kafka and Amazon Kinesis outdo the scaling limits of conventional messaging queues by facilitating high-volume pub/sub capabilities. This allows for the gathering and delivery of substantial streams of event data from multiple sources (referred to as producers in Amazon's terminology) to multiple sinks (or consumers in Amazon's parlance), all in real time.
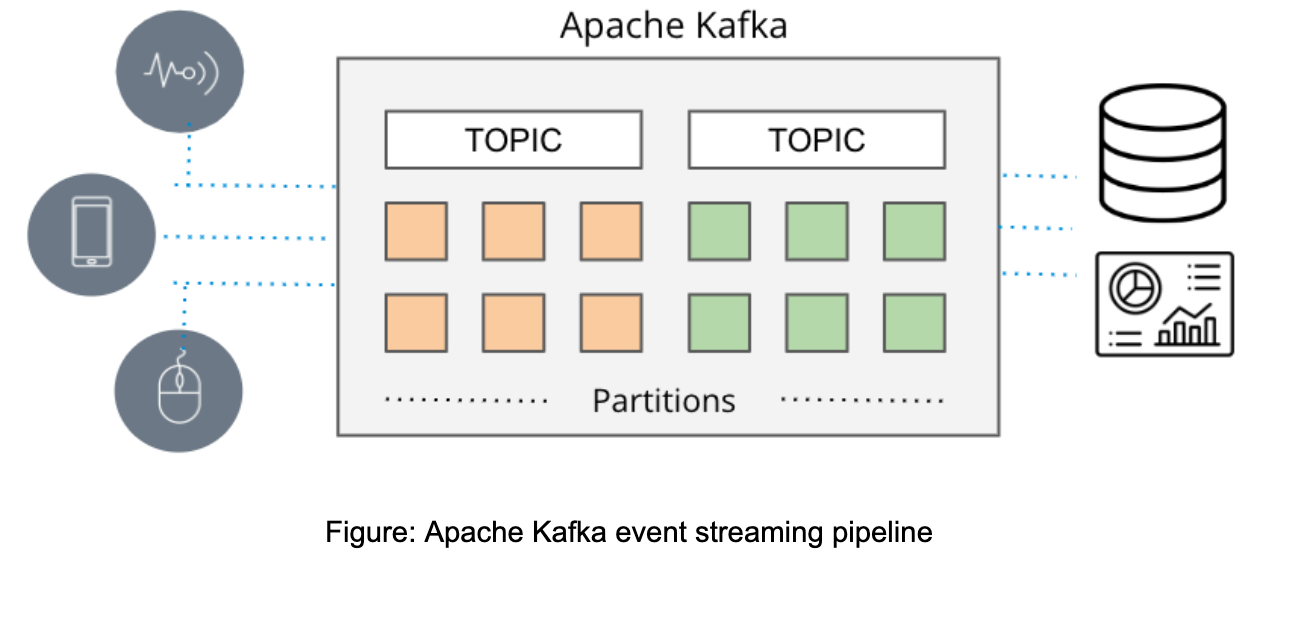
These systems gather data directly from various sources such as databases, sensors, and cloud services, all in the form of event streams, and then distribute these data to other applications, databases, and services in real time.
Given their high scalability (for instance, Apache Kafka at LinkedIn can manage over 7 trillion messages per day) and the ability to process multiple, simultaneous data sources, event streaming has emerged as the standard mode of data delivery when real-time data is required by applications.
With real-time data capture in place, the next question becomes, how do we effectively analyze this data in real-time?
Real-Time Analytics Database
For real-time analytics to be effective, a specialized database is required. One that can harness the power of streaming data from Apache Kafka and Amazon Kinesis and deliver instant insights. This is where Apache Druid comes into play.
Apache Druid, a high-powered real-time analytics database designed specifically for streaming data, has emerged as the preferred option for constructing real-time analytics applications. Capable of genuine stream ingestion, it can manage large-scale aggregations on terabytes to petabytes of data while maintaining sub-second performance under load. Furthermore, thanks to its native integration with Apache Kafka and Amazon Kinesis, it is the preferred choice when quick insights from fresh data are paramount.
When choosing an analytics database for streaming data, considerations such as scale, latency, and data integrity are crucial. Questions to ask include: Can it manage the full scale of event streaming? Is it able to ingest and correlate multiple Kafka topics (or Kinesis shards)? Does it support event-based ingestion? In the event of an interruption, can it prevent data loss or duplicates? Apache Druid satisfies all these criteria, offering even more capabilities.
Druid was engineered from the ground up to quickly ingest and instantaneously query events as they arrive. Unlike other systems that mimic a stream by sequentially sending batches of data files, Druid ingests data on an event-by-event basis. There's no need for connectors to Kafka or Kinesis, and Druid ensures data integrity by supporting exactly-once semantics.
Similar to Apache Kafka, Apache Druid is purpose-built to handle massive volumes of event data at the internet scale. With its services-based architecture, Druid can independently scale ingestion and query processing to virtually unlimited levels. By mapping ingestion tasks to Kafka partitions, Druid seamlessly scales alongside expanding Kafka clusters, ensuring optimal performance and scalability.
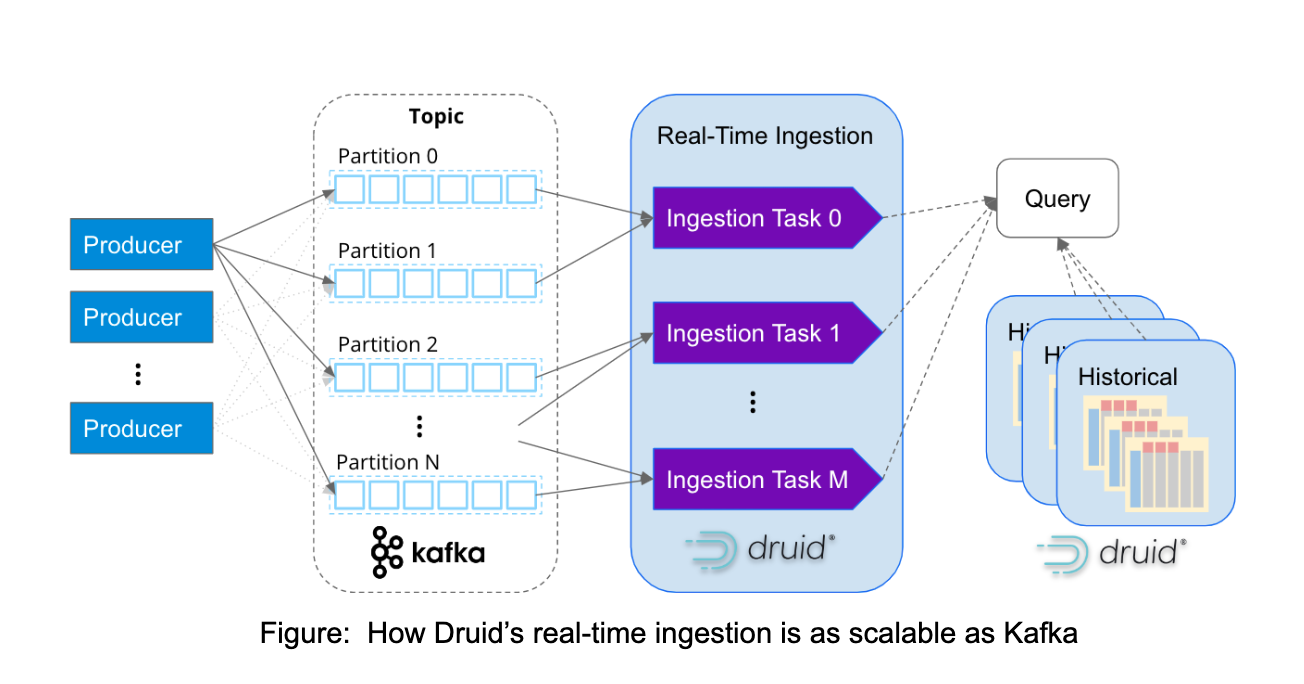
It is increasingly common to witness companies ingesting millions of events per second into Druid. For instance, Confluent, the pioneers of Kafka, constructed their observability platform using Druid and successfully ingests over 5 million events per second from Kafka. This exemplifies the exceptional scalability and efficiency of Druid in handling high-volume event streams.
However, real-time analytics requires more than just real-time data. To derive meaningful insights from real-time patterns and behaviors, it is essential to correlate them with historical data. One of Druid's key strengths, as depicted in the diagram above, lies in its ability to seamlessly provide both real-time and historical insights through a single SQL query. With efficient data management capabilities, Druid can handle data volumes of up to petabytes in the background, enabling comprehensive analysis and understanding of the data landscape.
When all these elements are combined, you achieve an exceptionally scalable data architecture for real-time analytics. This architecture is the go-to choice for thousands of data architects when they require high scalability, low latency, and the ability to perform complex aggregations on real-time data. It offers a robust solution that can meet the demands of processing vast amounts of data in real time while maintaining optimal performance and enabling advanced analytics.
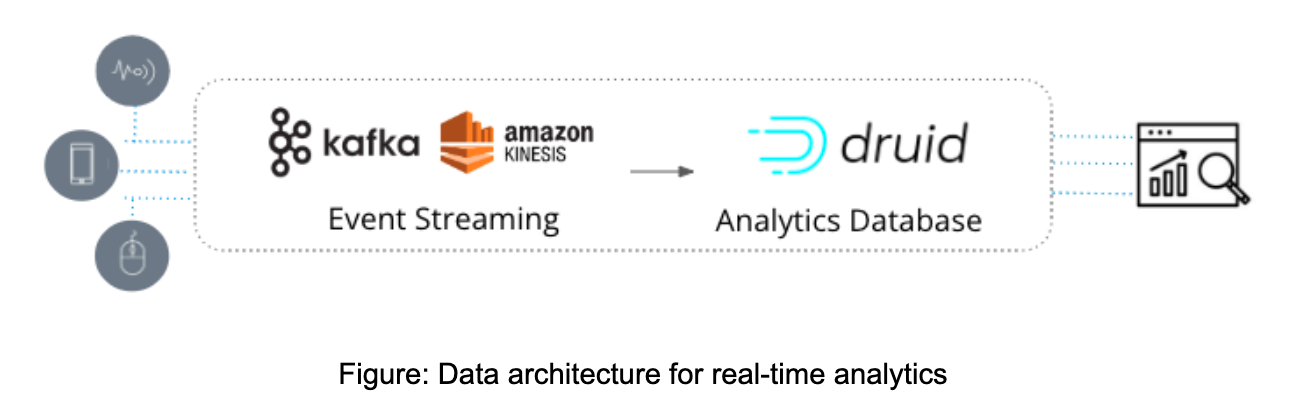
Illustration: How Netflix Ensures an Exceptional User Experience
Real-time analytics is a critical factor in enabling Netflix to provide a consistently excellent experience to its vast user base of over 200 million, who collectively consume 250 million hours of content each day. To achieve this, Netflix developed an observability application that allows for real-time monitoring of more than 300 million devices.
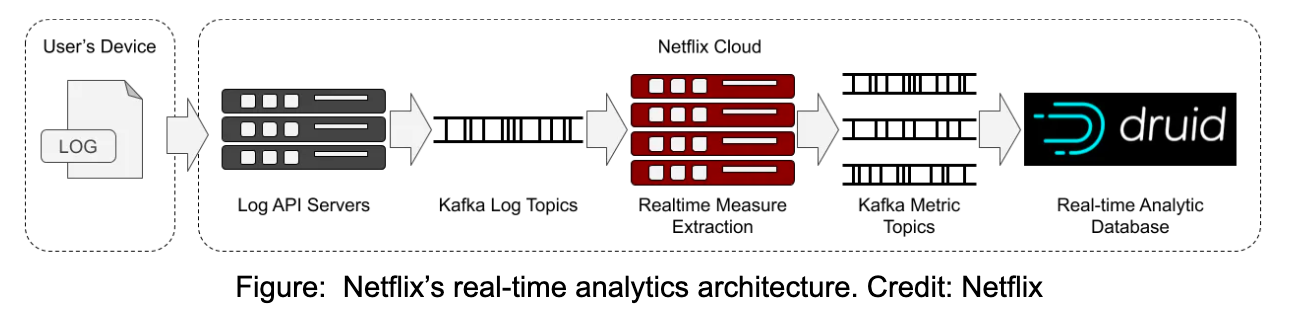 By leveraging real-time logs obtained from playback devices and streaming them through Apache Kafka, Netflix can capture and ingest these logs into Apache Druid on an event-by-event basis. This data pipeline enables Netflix to extract valuable insights and measurements that facilitate a comprehensive understanding of how user devices are performing during browsing and playback activities.
By leveraging real-time logs obtained from playback devices and streaming them through Apache Kafka, Netflix can capture and ingest these logs into Apache Druid on an event-by-event basis. This data pipeline enables Netflix to extract valuable insights and measurements that facilitate a comprehensive understanding of how user devices are performing during browsing and playback activities.
Netflix's infrastructure generates an astounding volume of over 2 million events per second, which is seamlessly processed by their data systems. Through subsecond queries performed across a staggering 1.5 trillion rows of data, Netflix engineers possess the capability to precisely identify anomalies within their infrastructure, endpoint activity, and content flow. This empowers them to proactively address issues and optimize their operations for an enhanced user experience.
Parth Brahmbhatt, senior software engineer, Netflix summarizes it best:
“Druid is our choice for anything where you need subsecond latency, any user interactive dashboarding, any reporting where you expect somebody on the other end to actually be waiting for a response. If you want super fast, low latency, less than a second, that’s when we recommend Druid.”
Opinions expressed by DZone contributors are their own.
Comments