Designing High-Volume Systems Using Event-Driven Architectures
Building cloud natively
Join the DZone community and get the full member experience.
Join For FreePrelude
Microservices style application architecture is taking root and rapidly growing in population that are possibly scattered in different parts of the enterprise ecosystem. Organizing and efficiently operating them on a multi-cloud environment organizing data around microservices, making the data as real-time as possible are emerging to be some of the key challenges.
Thanks to the latest development in Event-Driven Architecture (EDA) platforms such as Kafka and data management techniques such as Data Meshes and Data Fabrics, designing microservices-based applications is now much easier.
However, to ensure these microservices-based applications perform at requisite levels, it is important to ensure critical Non-Functional Requirements (NFRs) are taken into consideration during the design time itself.
In a series of blog articles, my colleagues Tanmay Ambre, Harish Bharti along with myself are attempting to describe a cohesive approach on Design for NFR. We take a use-case-based approach.
In the first installment, we describe designing for “performance” as the first critical NFR. This article focuses on architectural and design decisions that are the basis of high-volume, low-latency processing.
To make these decisions clear and easy to understand, we describe their application to a high-level use case of funds transfer. We have simplified the use case to focus mainly on performance.
Use Case
Electronic Fund Transfer (ETF) is a very important way of sending and receiving money these days by consuming through digital channels. We consider this use case as a good candidate for explaining performance-related decisions as it involves a high volume of requests, coordinating with many distributed systems, and has no margin for error (i.e. the system needs to be reliable and fault-tolerant).
In the past, fund transfers would take days. It would involve a visit to a branch or writing a cheque. However, with the emergence of digital, new payment mechanisms, payment gateways. and regulations, fund transfer has become instantaneous. For example, in September 2021, 3.6 billion transactions worth 6.5 trillion INR were executed on the UPI network in real-time. Customers are expecting real-time payments across a wide variety of channels. Regulations such as PSD2, Open Banking, and country-specific regulations have made it mandatory to expose their payment mechanisms to trusted third-party application developers.
Typically, a customer of a bank would place the request for fund transfer using one of the channels available (e.g., mobile app, online portal, or by visiting the institution). Once the request is received, the following needs to be performed:
- Check entitlements – i.e., check the eligibility of the customer to raise the request
- Perform checks for operational limits (depending on channel and mode of transfer)
- Perform balance checks and lock the amount of the transfer
- Perform sanctions checks – if the transaction conforms to regulations and sanctions checks
- Perform fraud checks – check if the transaction seems fraudulent
- Creating a request for payments in the payment gateway
The below figure gives an overview of this:
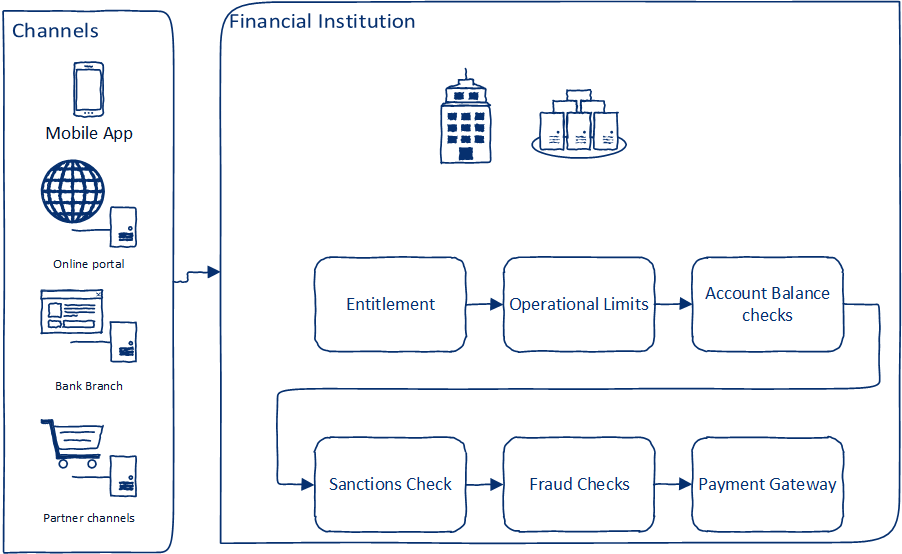
Note: For the sake of this article, this use case comprises operations done within the financial institution where the request originates. It relies upon already established payment gateways that execute the actual fund transfer. Operations of the payment gateway are outside the scope of this use case.
Critical Non-Functional Requirements
Here are the most critical NFRs that we must address:
- Performance
- Low-latency processing of events
- High throughput
- Resiliency
- Recoverability – ability to recover from failures. Restart from the point of failure and possess the ability to replay events. Minimize RTO (recovery time objective)
- Zero data loss
- Ability to always produce reliable and consistent outcomes.
- Availability & Scalability
- Highly available & Fault-tolerant – ability to withstand failures (including datacentre/availability zone outages)
- Ensure horizontal scaling to scale as load increases
- Ability to withstand occasional volume surge (elastic scalability)
- Ability to hold large volumes of data for regulatory compliance
- Security
- Instrumenting security in the core application – Shifting Left
- Authentication and authorization
- Auditing
- Transport layer security
- Secure data in transit and at rest
Architecture
The implementation model of this use case will be through a cloud-native style – Microservices, API, Containers, Event Streams, and Distributed Data Management with eventual consistency style data persistence for integrity. Please note that this architecture is based on the architectural best practices that are outlined in Architectural Considerations for Event-Driven Microservices-Based Systems.
Following is the set of key architectural patterns considered to implement this user story:
- Staged Event-Driven Architecture (SEDA)
- Event Stream Processing
- Event Sourcing
- SAGA
- CQRS
The following diagram provides an overview of the solution architecture:

Application and Data Flow
The application architecture is organized through a set of independently operable microservices. In addition, an orchestrator service (another microservice) coordinates the full transaction ensuring the end-to-end process execution is in place.
The different services of fund transfer are wired together as a set of producers, processors, and consumers of events. They are 4 main processors:
- Fund Transfer Orchestrator – responsible for processing fund transfer events and modifying and maintaining the state of Fund Transfer requests.
- Fund Transfer Request Router – Based on state transition generate an event and determine where to route the event to. It can multicast the event to multiple other systems or a single system. This is an optional component. It is required if the downstream consumers can’t consume from a single topic (e.g., they are legacy or already implemented services and can’t change to consume from a single topic).
- Fund Transfer Statistics Aggregator – responsible for aggregating and maintaining fund transfer statistics based on multiple dimensions that are required to manage KPIs.
- Fund Transfer Exception Management– responsible for triggering user actions on in-flight Fund Transfer requests. This could include canceling a fund Transfer request or replaying them. Basically, provides the ability for users to manage exceptions.
- Fund Transfer API – provides functionality for the channels to (a) request fund transfer, (b) check the status of the transfer, (c) perform interventions (cancel, replay, etc).
The API publishes an event to the input topic of Fund Transfer Orchestrator, which is the primary coordinator for Fund Transfer requests. Events are first-class citizens and are persistent. The events accumulate in an event store (enabling the event sourcing architectural pattern). Based on the event context and the payload, the orchestrator will transform the event and publish the state of fund transfer to another topic. The fund transfer state transitions are also recorded in a state store which can be used to regenerate the state in case of system-level failures.
This state is consumed by the Fund Transfer Request Router which will then make routing decisions and route it to other systems (either single or multiple systems simultaneously). Other systems will do their processing and publish the outcome as an event to the input topic. Which are then correlated and processed by the Fund Transfer Orchestrator resulting in a state change of the Fund Transfer request. Functional exceptions are processed by the Fund Transfer Orchestrator and the Fund Transfer Request state is updated accordingly.
Fund Transfer state changes are also consumed by the real-time Fund Transfer Statistics Service which aggregates the statistics of fund transfer across multiple different dimensions – so that the operations team can have a nearly real-time view of the Fund Transfer statistics.
Technology Building Block and Stack
To implement the above application architecture, we decided on key technical building blocks:
- Event backbone – used to send messages between services. It will also ensure the ordering and sequencing of events. It also provides the single source of truth of data. In case of failures – the system can restart from the point of failure. It provides the mechanism to build event and state stores. In case of major outages, the event and state stores can be utilized to reinstate the state.
- In-memory data-grid – It is a distributed cache that is used to improve performance. It provides the ability to store and look up data from the services. Each service can have its own set of caches. These caches can be persistent (optional). The cache can also be enabled as a “write-through” cache. It is resilient and can withstand outages. Also, in case of cluster-level failure (i.e., the entire cache cluster going down), the cache can be rehydrated from the event and state stores of the event backbone (however, this would require some downtime of the processors).
- Service Mesh – provides the ability to monitor, secure, and discover services.
Following is an indicative technology stack that can be used to build this system. Most of them are open-source. It is possible to use other technologies. For e.g., Quarkus.
Capability |
Implementation Choices |
DevOps Capability |
DevOps tool choices |
Programming Language |
Java Spring-boot, Quarkus, Golang |
CI /CD |
Jenkins / Tekton, Maven/ Gradle, Nexus / Quay |
Event Backbone |
Event Backbone – Apache Kafka, rabbit mq |
Deployment Automation |
Ansible, Chef |
Event / Message Format |
Avro, JSON |
Monitoring & Visualization |
Prometheus, Grafana, Micrometer, spring-boot actuator |
In-Memory Cache |
Apache Ignite, Redis, Hazelcast |
Service Mesh (Auto heal, autoscale, Canary++) |
Istio |
NoSQL Database |
Mongo, Cassandra, CouchDB |
Log Streams and Analytics |
EFK (Elastic Search, Filebeat, Kibana) |
Relational DB |
Postgres, Maria, MySQL |
Continuous Code Quality management |
Sonarqube, Cast |
New SQL (Distributed RDBMS) |
Yugabyte, CockroachDB |
Config & Source Code Management |
Git & Spring Cloud Config |
Design Decisions to Address Non-Functional Requirements
Following are the top three critical Design Decisions addressing the highly dynamic and complex NFRs.
- Event Backbone – The fundamental decision to implement the use case and architectural requirements is to establish an event backbone. The main reason for this decision is that the different processes in fund transfer can be triggered in parallel to reduce processing time. Additionally, using an industry-grade event backbone would provide/support certain architectural qualities (such as fault tolerance, recoverability, scalability, and ordering of events) out of the box.
- Data Streaming – usage of in-memory data-grid can significantly reduce database round trips. Additionally, the data and events are partitioned which makes it easier for the system to scale. Also using the same availability zone for the deployment of all components – the network latency is reduced to a large extent.
- Shifting Security aspects to the Left – Security must be enforced at each individual component level. Appropriate access control and authentication mechanisms need to be implemented for each component (esp. the event backbone, in-memory data grid). It is essential to have a deep understanding of the security standards and regulations which need to be met (in this case, PCI-DSS, GDPR, etc). Transport layer security is vital for ensuring data is encrypted during transit. Additionally, controls related to data (esp. sensitive private information) must be enforced. Avoid putting sensitive information in cache (though this may impact performance). During testing for NFRs – security needs to be tested. Static code quality analysis should check for security vulnerabilities in code. Images of the components need to be scanned for security vulnerabilities. Firewalls, DMZ, and VPC need to be set up with the appropriate IAM solutions. Another key aspect of security in cloud-native architecture is secret, key, and certificate management.
The above three design decisions will help address NFRs in the following categories:
- Auto-scaling – each component of the system (including the event backbone, in-memory data-grid) can be scaled automatically when containerized and deployed on a platform like Kubernetes and OpenShift.
- Fault-Tolerance – each component of the processing pipeline can be restarted from the point of failure. There is no special implementation required for this. This comes out of the box when using an event backbone such as Apache Kafka. Additionally, Kafka Topics double up as event and state stores. Therefore, the processing state can be reinstated easily. Also, the replication and rebalancing capability of Kafka and Ignite provides the ability to continue operations even when a few nodes of the cluster are lost.
- High Observability – each component of the system is instrumented, and real-time performance and resource utilization metrics are streamed into Prometheus. Grafana is used for visualization and notifications
- Resiliency – There are multiple levels of deployment decisions to take care of resiliency. Each component has multiple instances running in the same availability zone (including for Kafka). A DR location is maintained in a different availability zone which is stand-by. Cluster level replication is enabled for Kafka between the active and dr cluster of Kafka.
In the following section, we deep dive into some key design considerations around the top NFR – Performance. We will publish articles on design considerations around the other NFRs as follow on to this article.
Design Considerations to Address Performance Requirements
To address performance requirements, the following have been considered during design and implementation:
Performance modeling – It is important to have a clear understanding of performance targets. This impacts many architectural, technology, infrastructure, and design decisions. With increased adoption of hybrid and multi-cloud solutions, performance modeling has become even more important. There are many architectural trade-offs that rely on performance modeling. Performance modeling should cover – transaction/event inventory, workload modeling (concurrency, peak volumes, expected response time for different transactions/events), and infrastructure modeling. Building a performance model helps create the deployment model (especially those related to scalability), making architectural and design optimizations to reduce latency, and helps in designing performance tests to validate performance and throughput.
Avoid Monolithic monsters – Monolithic architecture centralizes processing. This means it won’t be possible to scale different components independently. In fact, even the service implementation should be broken down into loosely coupled components using SEDA to provide the ability to scale each component separately and to make the service more resilient. Each deployed component should be independently scalable and deployed as a cluster to increase concurrency and resiliency.
Choice of event backbone – Choice of event backbone impacts performance. Primarily these 5 characteristics of the backbone are important to consider from a performance perspective:
- Performance of message ingestion (esp. along with making the messages persistent. i.e., writing messages to the disk). Additionally, the performance needs to be consistent all the time.
- Performance of message consumption by consumers
- Ability to scale (i.e., the addition of new nodes/brokers in the cluster)
- Time taken to re-balance when a node/broker fails
- Time taken to re-balance when a consumer instance leaves or joins a consumer group
Apache Kafka is a good choice because of its proven performance, fault-tolerance, scalability, and availability track record in numerous engagements. It takes care of the first three points above. For the last 2 points (rebalance time), Kafka’s performance is dependent on the amount of data on the topics. Apache Pulsar tries to solve this. However, we are using Kafka given its proven track record, but we are closely monitoring the evolution of Apache Pulsar.
Leverage Caching – Database queries are expensive. To avoid them, it is recommended to leverage caching. For e.g., Redis, Apache Ignite, etc. By using caching, a fast data layer can be created that will help in data lookup. All read-only calls are redirected to the cache instead of fetching the data from the database or some other remote service. The stream data processing pipelines populate (or update) the cache in near real-time. Event processors then reference the data in the cache, instead of querying databases or making service calls to systems of record. Event processors write to Ignite and then persistence processors asynchronously write the data to the database. This gives a major boost to performance.
In our case, we chose Apache Ignite because:
- It provides distributed caching (supports data partitioning)
- Horizontally scalable
- ANSI SQL compliant
- Ease of use
- Supports replication – providing some degree of fault-tolerance
- Cloud-ready
Caching can be made persistent. I.e., the cached data is written to disk. But it impacts performance. The performance penalty is very significant when not using SSD. If caches are non-persistent then the architecture needs to cater for rehydrating the cache from data/event stores. Recovery performance is critical to reducing mean time to recovery. In our architecture – Kafka topics are leveraged to rehydrate the cache. They are our event/state stores. There is a multi-instance recovery component that reads data from Kafka topics and rehydrates the cache.
Collocated processing – Performance is at its best when the event producers, consumers, and the event backbone are collocated. However, this would mean if the datacenter goes down – it would bring down the entire platform. This can be avoided if replication/mirroring is set up for the event backbone. For e.g., Kafka MirrorMaker 2 (MM2) can be used to set up replication across datacenters/availability zones.
Choosing the correct message format – The speed of serialization and de-serialization of messages has some impact on performance. There are multiple choices for message format. For e.g., XML, JSON, Avro, Protobuf, Thrift. For this application, we chose Avro due to its compactness, (de) serialization performance, and schema evolution support.
Concurrency related decisions – In this architecture the key deciding parameters in terms of concurrency are:
- Number of partitions on Kafka topics
- Number of instances in each consumer group
- Number of threads in each instance of a consumer/producer
These have a direct impact on the throughput. In Kafka, each partition can be consumed by a single thread of the same consumer group. Having multiple partitions and multiple drives on Kafka brokers helps in spreading the events without having to worry about sequencing. Having a multi-threaded consumer can help to a certain extent till the resource utilization limits are reached (CPU, Memory, and Network). Having multiple instances in the same consumer group splits the load across multiple nodes/servers providing horizontal scalability.
When using partitions – the higher the number of partitions, the higher the concurrency. However, there are certain considerations when determining the number of partitions. It is important to choose the partition key is such a way that it evenly spreads events across partitions without breaking the ordering requirements. Also, over-partitioning has some implications in terms of open file handles, higher unavailability of Kafka topics in case of broker failures, higher end-to-end latency, and higher memory requirements for the consumer.
Performing performance tests to benchmark performance and then extrapolating them to the desired throughput and performance helps in finalizing these 3 parameters.
I/O matters – I/O contributes significantly to latency. It impacts all components of the architecture. It impacts the event backbone, caching, databases, and application components.
For distributed caching components that have persistence enabled, I/O is one of the key factors that impact performance. For e.g., for Apache Ignite – it is strongly recommended to use SSDs for good performance along with enabling direct I/O. Non-persistent caches are the fastest – however, the downside is if the cache cluster goes down, cached data is lost. This can be solved by having a recovery process – which rehydrates the cache. However, it should be noted that the longer the recovery time – the larger the lag being built in the streaming pipeline. Therefore, the recovery process must be extremely fast. This can be done by having multiple instances of the recovery process running and avoiding any transformation/business logic in the recovery processors.
Kafka doesn’t necessarily require high-performance disks (such as SSD). For Kafka, it is recommended to have multiple drives (and multiple log dirs) to get good throughput. And sharing of drives with application and operating system is not recommended. Additionally, mount options such as “noatime” provide performance gain. Other mount options that are dependent on the type of filesystem are discussed here: https://kafka.apache.org/documentation.html#diskandfs
From an Application point of view – keep logging to a minimum. Instead of logging everything, log outliers. Even though most of the logging frameworks are capable of asynchronous logging, there is still an impact on latency.
Memory tuning – Our event streaming architecture relies heavily on in-memory processing. This is especially true for Kafka brokers and Apache Ignite server nodes. It is important to allocate adequate memory to processors, consumers, Kafka brokers and in-memory data-grid nodes.
Tuning the operating system’s memory settings can also help boost performance to an extent. One of the key parameters is “vm.swappiness”. This controls the swapping out of process memory. It takes a value between 0 and 100. Higher the number, swapping is done more aggressively. It is recommended to keep this number low to reduce swapping.
In the case of Kafka, since it relies heavily on the page cache, therefore the “vm dirty ratio” options can be also tweaked to control the flushing of data to disks.
Network Usage Optimization – to utilize the network efficiently it is recommended to apply compression to very large messages. This will reduce network utilization. However, that comes at a cost of higher CPU utilization for the producer, consumer, and broker. For e.g., Kafka supports 4 different compression types (gzip, lz4, snappy, zstd). Snappy fits in the middle, giving a good balance of CPU usage, compression ratio, speed, and network utilization.
Reasons for choosing snappy are provided in the article Message Compression in Kafka.
Only Deserialize relevant messages – In a publish-subscribe mechanism, a consumer can get messages which they are not interested in. Adding a filter will eliminate the need for processing non-relevant messages. However, it will still require de-serializing the event payloads. This can be avoided by adding event metadata in the header of the events. This gives a choice to the consumers to look at the event headers and decide whether to parse the payload or not. This significantly improves the throughput of the consumers and reduces resource utilization.
Parse what is required (esp. XMLs) – In the financial services industry – XMLs are heavily used. It is quite possible that the input to the event streaming applications is XML. Parsing XML is CPU and memory-intensive. The choice of XML parser is a key decision related to performance and resource utilization. If the XML document is very large, it is recommended to use SAX parsers. If the event streaming application does not require fully parsing the XML document, then having pre-configured xpaths to lookup the required data and constructing the event payload from it may be a faster option. However, in case the entire XML data is required – it would be wise to parse the entire document once and convert it into the event streaming application’s message format once, and having multiple instances of this processor instead of having each processor in the event streaming pipeline parsing the XML document.
Detailed instrumentation for monitoring and identifying performance bottlenecks – It should be easy to identify performance bottlenecks. This can be achieved by having using a lightweight instrumentation framework (based on AOP). In our example, we combine AOP with Spring-Boot Actuator and Micrometer to expose a Prometheus endpoint. For Apache Kafka, we use the JMX exporter for Prometheus to gather Kafka performance metrics. We then use Grafana to build a rich dashboard displaying performance metrics for the producers, consumers, Kafka, and Ignite (basically all components of our architecture).
This gives the ability to pinpoint bottlenecks very quickly rather than relying on log analysis and correlation.
Please refer to our open-source framework for more.
Fine-tuning Kafka configuration – Kafka has a huge set of configuration parameters for brokers, producers, consumers, and Kafka streams. These are the parameters we have used to tune Kafka for Latency and Throughput.
- Broker
- log.dirs – set multiple directories on different drives to speed up I/O
- num.network.threads
- num.io.threads
- num.replica.fetchers
- socket.send.buffer.bytes
- socket.receive.buffer.bytes
- socket.request.max.bytes
- group.initial.rebalance.delay.ms
- Producer
- linger.ms
- batch.size
- buffer.memory
- compression.type
- Consumer
- fetch.min.bytes – if set to default value of 1 it will improve latency but throughput wont be good. So, it must be balanced
- max.poll.records
- Streams
- num.stream.threads
- buffered.records.per.partition
- cache.max.bytes.buffering
Please refer to the references provided for additional information on tuning Kafka brokers, producers, and consumers.
Tuning GC – Garbage collection tuning is important to avoid long pauses and excessive GC overhead. As of JDK 8, Garbage-First Garbage Collector (G1GC) is recommended for most of the applications (multi-processor machines with large memory). It attempts to meet collection pause time goals as well as tries to achieve high throughput. Additionally, not much configuration is required to get started.
We ensure that sufficient memory is made available to the JVM. In the case of Ignite, we use the off-heap memory to store data.
The -Xms and -Xmx are kept at the same value with the “-XX:+AlwaysPreTouch” to ensure all memory allocation from the OS happens during startup.
There are additional parameters in G1GC such as the following can be used to tune throughput further (since in EDA throughput matters):
- -XX:MaxGCPauseMillis (increase its value to improve throughput)
- -XX:G1NewSizePercent, -XX:G1MaxNewSizePercent
- -XX:ConcGCThreads
For more details, please refer to the tuning G1GC.
Tuning Apache Ignite – Apache Ignite tuning is well documented on its official site. Here are the few things that we have followed for improving its performance:
- 80:20 principle while allocating memory to Ignite server node (80% to the Ignite process. 20% reserved for OS)
- Used zookeeper for cluster discovery
- Used off-heap memory for storing data
- Allocated at least 16GB to the JVM heap
- Dividing the off-heap into different data regions depending on the requirements (reference data region, input data region, output data region, etc)
- Reference data is held in “replicated” caches
- Input/Output (i.e., transactional data) is held in “partitioned” caches.
- Ensured each cache has an affinity key defined which is always used in queries for collocated processing
- JVM GC tuned using the guidance in the above section
- Usage of cache groups for logically related data
- Enabling “lazy” loading in JDBC drivers
- Correctly sizing different thread pools to improve performance
- Usage of JCache API instead of SQL queries
- Ensuring cursors are closed
- Using “NearCache” configuration for reference data – so looking it up doesn’t require the client nodes to fetch from remote server nodes
- Increasing inline size of indexes
- Reducing vm.swappiness to 1
- Using direct-IO
- Reference data caches have native persistence enabled. However, transactional caches don’t. Transactional caches are backed up on Kafka. In case of cluster outage, the transactional data is rehydrated into Ignite from Kafka using a separate recovery processor
Conclusion
In this article, we focused on key architectural decisions related to performance. It is extremely critical to maintain desired performance levels of each individual component of the architecture as issues in any one of them can cause the stream processing to choke. Therefore every component of the architecture needs to be tuned for performance without compromising on other NFRs. It is essential to have a deep technical understanding of the component so that it can be tuned effectively.
References
- NPCI - https://www.npci.org.in/what-we-do/upi/product-statistics
- EDA best practices – https://developer.ibm.com/articles/eda-and-microservices-architecture-best-practices/
- Role of in-memory data-grids in EDA – https://shahirdaya.medium.com/the-role-of-in-memory-data-grids-in-event-driven-streaming-data-architectures-b32f976afc16
- Message Compression in Kafka – https://developer.ibm.com/articles/benefits-compression-kafka-messaging/
- Kafka H/W and OS requirements – https://kafka.apache.org/documentation/#hwandos
- Kafka Performance Tuning – https://docs.cloudera.com/runtime/7.2.7/kafka-performance-tuning/kafka-performance-tuning.pdf
- Optimizing Your Apache Kafka Deployment [Yeva Byzek 2020 Confluent Inc.]
- Choosing the number of Kafka Partition – https://www.confluent.io/blog/how-choose-number-topics-partitions-kafka-cluster/
- G1GC Tuning – https://docs.oracle.com/en/java/javase/11/gctuning/garbage-first-garbage-collector-tuning.html#GUID-43ADE54E-2054-465C-8376-81CE92B6C1A4
- Monitor Spring Boot Microservices – https://developer.ibm.com/tutorials/monitor-spring-boot-microservices/
- Ignite performance tuning - https://ignite.apache.org/docs/latest/perf-and-troubleshooting/general-perf-tips
Opinions expressed by DZone contributors are their own.
Comments