Create a Langchain Alternative From Scratch Using OceanBase
From integrating AI with OceanBase to training the model and creating a chatbot, we will explore the topic in an interesting journey.
Join the DZone community and get the full member experience.
Join For FreeRecently, I've been exploring the world of OceanBase, a distributed relational database management system. As I navigated through its extensive documentation, I realized the magnitude of the task at hand — the sheer volume of content made it challenging to find precise information quickly and efficiently.
This experience sparked an idea. What if there was a way to simplify this process? What if we could leverage the power of AI to navigate through this vast sea of information? Thus, the concept of a document chatbot for OceanBase was born.
But I wanted to take this idea a step further. To make the project more intriguing and to deepen my understanding of OceanBase, I decided to use OceanBase itself as the vector database for AI training. This approach would not only provide a practical solution to the information retrieval challenge but also offer a unique opportunity to explore the capabilities of OceanBase from a different perspective.
In this blog post, I will share the journey of bringing this idea to life. From integrating AI with OceanBase to training the model and creating a chatbot, we will explore the challenges, the solutions, and the insights gained along the way. Whether you're an AI enthusiast, a database professional, or simply interested in the intersection of these two fields, I invite you to join me on this exciting exploration.
TL:DR:
- The project integrates AI with OceanBase to create a document chatbot capable of answering user queries based on OceanBase's documentation and any other GitHub-hosted documentation.
- User questions and documentation articles are transformed into vector representations for comparison and answer generation.
- Due to OceanBase's lack of inherent support for vector data type, vectors are stored and retrieved as JSON.
- Dive into a step-by-step guide on setting up the project environment, training the model, and setting up the server.
- The project highlights the need for OceanBase to incorporate support for the vector data type to leverage the potential of AI and machine learning fully.
Some Reflections on the Project
Embarking on this project to integrate OceanBase with AI was a challenging yet rewarding endeavor. It was an opportunity to dive into the intricacies of AI and databases, which provided a rich learning experience.
Generally, a document chatbot that we want to make uses AI to answer user queries with information from a document database. It transforms user questions into vector representations and compares them with preprocessed document vectors. The most relevant document is identified based on vector similarity. The chatbot then uses this document to generate a contextually appropriate answer, providing precise and relevant responses.
Before a chatbot can answer questions based on given documentation, you need to “train” it with relevant knowledge. The training process, at its essence, is to transform articles in the documentation into embeddings - numerical representations (vectors) of text that capture the semantic meanings of words. The embeddings are then stored in a database in this project, OceanBase.
You may ask why I don’t use Langchain, which is already an established solution. While Langchain is a powerful platform for language model training and deployment, it wasn't the optimal choice for this project due to its expectations and our specific requirements.
Langchain assumes that the underlying database can handle vector storage and perform similarity searches. However, OceanBase, the database we used, doesn't directly support the vector data type.
Moreover, the project's key objective was to explore OceanBase's potential as a vector database for AI training. Using Langchain, which handles similarity search internally, would have bypassed the opportunity to delve into these aspects of OceanBase.
Since OceanBase doesn’t directly support vector stores, we have to find a workaround. But vectors are essentially an array of numbers. We can store it as a JSON string or a blob in the database. And when we need to compare the records with the question embeddings, we can just turn them back to embeddings in the next step.
Given that OceanBase does not inherently support the vector data type, each embedding needs to be converted into a data type that OceanBase does support, in this case, JSON. Consequently, when comparing the question with the articles, these records need to be reverted back to their original embedding form. This conversion process, unfortunately, results in a slower system that lacks scalability.
To fully leverage the potential of AI and machine learning, I would strongly recommend that the OceanBase team consider incorporating support for the vector data type. This would not only enhance the performance and scalability of the system but also position OceanBase as a forward-thinking database solution ready to embrace the AI era. I created an issue on their GitHub repo. If you are interested in exploring further, you are welcome to join the discussion there.
The Project
The system is built on a Node.js framework, using Express.js for handling HTTP requests. Sequelize, a promise-based Node.js ORM, is used for the task of database schema migrations, seeding, and querying.
The project is structured to handle two main requests: training the model with articles and asking questions. The '/train' endpoint fetches the articles, transforms them into vectors, and stores them in the database. The '/ask' endpoint takes a user's question, finds the most relevant article using the stored vectors, and generates an answer using OpenAI's API.
This project is available on GitHub for everyone to access and utilize. This means you can leverage the power of this AI-driven solution not only for OceanBase but also for any other document sets you might have. Feel free to clone the repository, explore the code, and use it as a base to train your own document chatbot. It's a great way to make your documents more interactive and accessible.
Getting Started
To set up the project environment from scratch, follow these steps:
Install Node.js: If not already installed, download and install Node.js from the official Node.js website.
Create a new project: Open your terminal, navigate to your desired directory, and create a new project using the command mkdir oceanbase-vector. Navigate into the new project directory with cd oceanbase-vector.
Initialize the Project: Initialize a new Node.js project by running npm init -y. This command creates a new package.json file with default values.
Install Dependencies: Install the necessary dependencies for the project. Use the following command to install all necessary packages:
npm install dotenv express lodash mysql2 openai sequelize --save
We will be using Sequelize as the ORM to interact with the OceanBase database. The lodash package is used to calculate cosine similarity in the similarity search process. And, of course, we need the openai package to interact with OpenAI’s API. We will use express as the server, which will expose the ask and train endpoints.
Next, use npm install sequelize-cli --save-dev to install the development dependencies.
Now, our project setup is complete, and we are ready to start building each module.
Setting up OceanBase
To set up the project, you first need a running OceanBase cluster. This article I wrote has detailed instructions on how to set up OceanBase.
Once you have a running OceanBase instance, the next step is to create a table for storing the articles and their corresponding embeddings. This table, named article_vectors, will have the following columns:
id: This is an integer type column that will serve as the primary key for the table. It is auto-incremented, meaning each new entry will automatically be assigned an ID that is one greater than the ID of the previous entry.content_vector: This is a JSON type column that will store the vector representation of the article. Each vector will be transformed into a JSON object for storage.content: This is a text type column that will store the actual content of the article.
To create the article_vectors table, you can use the following SQL command:
CREATE TABLE article_vectors (
id INT AUTO_INCREMENT,
content_vector JSON,
content TEXT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci,
PRIMARY KEY (id)
);
Now, we have a table ready in the OceanBase database to store the articles and their vector representations. In the next sections, we will populate this table with data from the OceanBase documentation and then use this data to train our AI model.
We also need to define the ArticleVector model in the Sequlize project. First, run sequelize init to initialize the sequelize environment. In the /models folder generated, create a new file called ArticleVector.js.
const { DataTypes, Model } = require('sequelize');
class ArticleVector extends Model {}
module.exports = (sequelize) => {
ArticleVector.init(
{
id: {
type: DataTypes.INTEGER,
autoIncrement: true,
primaryKey: true,
},
content_vector: {
type: DataTypes.JSON,
},
content: {
type: DataTypes.TEXT,
},
},
{
sequelize,
modelName: 'ArticleVector',
tableName: 'article_vectors',
timestamps: false,
},
{
sequelize,
modelName: 'ArticleVector',
tableName: 'content',
timestamps: false,
}
);
return ArticleVector;
};
The code defines a Sequelize model for the article_vectors table in our OceanBase database. Sequelize is a promise-based Node.js ORM that allows you to interact with your SQL database using high-level API calls.
Training on the Docs
The training process is the heart of our document chatbot. It involves fetching the OceanBase documentation from the GitHub repository, transforming the content into vector representations, and storing these vectors in the OceanBase database. This process is handled by two main scripts: trainDocs.js and embedding.js.
Fetching the Documentation
The trainDocs.js script fetches the contents of the OceanBase documentation from the GitHub repository. It uses the GitHub API to access the repository and retrieve all the .md files. The script is designed to recursively fetch the contents of directories, ensuring that all documentation files, regardless of their location in the repository, are retrieved.
The script also fetches the content of each documentation file. It sends a request to the file's download URL and stores the returned content for further processing.
async function fetchRepoContents(
repo,
path = '',
branch = 'main',
limit = 100
) {
const url = `https://api.github.com/repos/${repo}/contents/${path}?ref=${branch}`;
const accessToken = process.env.GITHUB_TOKEN;
const response = await fetch(url, {
headers: {
Authorization: `Bearer ${accessToken}`,
Accept: 'application/vnd.github+json',
'X-GitHub-Api-Version': '2022-11-28',
},
});
const data = await response.json();
// If the path is a directory, recursively fetch the contents
if (Array.isArray(data)) {
let count = 0;
const files = [];
for (const item of data) {
if (count >= limit) {
break;
}
if (item.type === 'dir') {
const dirFiles = await fetchRepoContents(
repo,
item.path,
branch,
limit - count
);
files.push(...dirFiles);
count += dirFiles.length;
} else if (item.type === 'file' && item.name.endsWith('.md')) {
files.push(item);
count++;
}
}
return files;
}
return [];
}
/**
* @param {RequestInfo | URL} url
*/
async function fetchFileContent(url) {
const response = await fetch(url);
const content = await response.text();
return content;
}
Now we can write the main function handling the embedding. The function will use the GitHub fetch functions we have defined to get all markdown files from a given repository. Notice that I have added a limit parameter to limit the number of files fetched. This is because the GitHub API has limits on how many requests you can make per hour. If the repo contains thousands of files, you may hit the limit.
async function articleEmbedding(repo, path = '', branch, limit) {
const contents = await fetchRepoContents(repo, path, branch, limit);
console.log(contents.length);
contents.forEach(async (item) => {
const content = await fetchFileContent(item.download_url);
await storeEmbedding(content);
});
}
Transforming and Storing the Vectors
The embedding.js script is responsible for transforming the fetched documentation into vector representations and storing these vectors in the OceanBase database. This is done using two main functions: embedArticle() and storeEmbedding().
To make sequelize and OpenAI work, we have to initialize them.
const { Sequelize } = require('sequelize');
const dotenv = require('dotenv');
dotenv.config();
const env = process.env.NODE_ENV || 'development';
const config = require(__dirname + '/../config/config.json')[env];
const { Configuration, OpenAIApi } = require('openai');
const configuration = new Configuration({
apiKey: process.env.OPENAI_KEY,
});
const openai = new OpenAIApi(configuration);
The embedArticle() function uses OpenAI's Embedding API to transform the content of an article into a vector. It sends a request to the API with the article content and retrieves the generated vector.
async function embedArticle(article) {
// Create article embeddings using OpenAI
try {
const result = await openai.createEmbedding({
model: 'text-embedding-ada-002',
input: article,
});
// get the embedding
const embedding = result.data.data[0].embedding;
return embedding;
} catch (error) {
if (error.response) {
console.log(error.response.status);
console.log(error.response.data);
} else {
console.log(error.message);
}
}
}
The storeEmbedding() function takes the generated vector and stores it in the OceanBase database. It connects to the database using Sequelize, creates a new record in the article_vectors table, and stores the vector and the original article content in the appropriate columns.
let sequelize;
if (config.use_env_variable) {
sequelize = new Sequelize(process.env[config.use_env_variable], config);
} else {
sequelize = new Sequelize(
config.database,
config.username,
config.password,
config
);
}
const ArticleVectorModel = require('../models/ArticleVector');
const ArticleVector = ArticleVectorModel(sequelize);
async function storeEmbedding(article) {
try {
await sequelize.authenticate();
console.log('Connection has been established successfully.');
const articleVector = await ArticleVector.create({
content_vector: await embedArticle(article),
content: article,
});
console.log('New article vector created:', articleVector.id);
} catch (err) {
console.error('Error:', err);
}
}
To initiate the training process, you just need to call the articleEmbedding() function in trainDocs.js with the appropriate parameters. This function fetches the documentation, transforms it into vectors, and stores these vectors in the database.
This training process ensures that the chatbot has a comprehensive understanding of the OceanBase documentation, allowing it to provide accurate and relevant answers to user queries.
In the next section, we will discuss how to use the trained model to answer user queries.
As you may have noticed, we are using a .env file to store sensitive information in the project. Here is an example .env file you can use:
GITHUB_TOKEN="Get your Github token from https://docs.github.com/en/rest/guides/getting-started-with-the-rest-api?apiVersion=2022-11-28"
OPENAI_KEY ="YOUR_OPENAI_KEY"
DOC_OWNER="OceanBase, you can change this to another product's name so that the chatbot knows which product it is dealing with"
MODEL="gpt-4 and gpt-3.5-turbo are supported"
Asking the Docs
Once the training process is complete, the chatbot is ready to answer user queries. This is handled by the /embeddings/askDocs.js file, which uses the stored vectors to find the most relevant documentation for a given question and then generates an answer using OpenAI's API.
The getSimilarDoc() function in askDocs.js is responsible for finding the most relevant documentation for a given question. It starts by transforming the question into a vector using the embedArticle() function from embedding.js.
Next, it retrieves all the stored vectors from the article_vectors table in the OceanBase database. It then calculates the cosine similarity between the question vector and each stored vector. The cosine similarity is a measure of how similar two vectors are, making it perfect for this task.
async function getSimilarDoc(question) {
let sequelize;
if (config.use_env_variable) {
sequelize = new Sequelize(process.env[config.use_env_variable], config);
} else {
sequelize = new Sequelize(
config.database,
config.username,
config.password,
config
);
}
const ArticleVector = ArticleVectorModel(sequelize);
// get all rows in article_vector table
const vectors = await ArticleVector.findAll();
sequelize.close();
// console.log(vectors[0]);
// Calculate cosine similarity for each vector
const embeddedQuestion = await embedArticle(question);
// Calculate cosine similarity for each vector
// Calculate cosine similarity for each vector
const similarities = vectors.map((vector) => {
const similarity = cosineSimilarity(
embeddedQuestion,
vector.content_vector
);
return {
id: vector.id,
content: vector.content,
similarity: similarity,
};
});
const mostSimilarDoc = _.orderBy(similarities, ['similarity'], ['desc'])[0];
// console.log(mostSimilarDoc);
return mostSimilarDoc;
}
The cosineSimilarity() function in askDocs.js is a crucial part of the document retrieval process. It calculates the cosine similarity between two vectors, which is a measure of how similar they are.
In the context of this project, it is used to determine the similarity between the vector representation of a user's question and the vector representations of the articles in the database. The article with the highest cosine similarity to the question is considered the most relevant.
The function takes two vectors as inputs. It calculates the dot product of the two vectors and the magnitude of each vector. The cosine similarity is then calculated as the dot product divided by the product of the two magnitudes.
function cosineSimilarity(vecA, vecB) {
const dotProduct = _.sum(_.zipWith(vecA, vecB, (a, b) => a * b));
const magnitudeA = Math.sqrt(_.sum(_.map(vecA, (a) => Math.pow(a, 2))));
const magnitudeB = Math.sqrt(_.sum(_.map(vecB, (b) => Math.pow(b, 2))));
if (magnitudeA === 0 || magnitudeB === 0) {
return 0;
}
return dotProduct / (magnitudeA * magnitudeB);
}
The function returns the documentation with the highest cosine similarity to the question. This is the most relevant documentation for the given question.
With the most relevant documentation identified, the askAI() function in askDocs.js generates an answer to the question. It uses OpenAI's API to generate a contextually appropriate answer based on the identified documentation.
The function sends a request to the API with the question and the relevant documentation. The API returns a generated answer, which the function then returns.
This process ensures that the chatbot provides accurate and relevant answers to user queries, making it a valuable tool for anyone seeking information from the OceanBase documentation.
async function askAI(question) {
const mostSimilarDoc = await getSimilarDoc(question);
const context = mostSimilarDoc.content;
try {
const result = await openai.createChatCompletion({
model: process.env.MODEL,
messages: [
{
role: 'system',
content: `You are ${
process.env.DOC_OWNER || 'a'
} documentation assistant. You will be provided a reference docs article and a question, please answer the question based on the article provided. Please don't make up anything.`,
},
{
role: 'user',
content: `Here is an article related to the question: \n ${context} \n Answer this question: \n ${question}`,
},
],
});
// get the answer
const answer = result.data.choices[0].message.content;
console.log(answer);
return {
answer: answer,
docId: mostSimilarDoc.id,
};
} catch (error) {
if (error.response) {
console.log(error.response.status);
console.log(error.response.data);
} else {
console.log(error.message);
}
}
}
Setting up the API Server
Now that we have set up the training and asking function, we can call them from an API endpoint. The Express.js server is the main entry point of our application. It exposes two endpoints, /train and /ask, which handle the training of the model and answering user queries, respectively. The code described here will be in the index.js file.
The server is initialized using Express.js, a fast, unopinionated, and minimalist web framework for Node.js. It is configured to parse incoming requests with JSON payloads using the express.json() middleware.
const express = require('express');
const app = express();
const db = require('./models');
app.use(express.json());
The server establishes a connection with the OceanBase database using Sequelize. The sync() function is called on the Sequelize instance to ensure that all defined models are synchronized with the database. This includes creating the necessary tables if they don't already exist.
db.sequelize.sync().then((req) => {
app.listen(3000, () => {
console.log('Server running at port 3000...');
});
});
Training Endpoint
The /train endpoint is a POST route that triggers the training process. It expects a request body containing the GitHub repository details (repo, path, branch, and limit). These details are passed to the articleEmbedding() function, which fetches the documentation, transforms it into vectors, and stores these vectors in the database.
app.post('/train', async (req, res, next) => {
try {
await articleEmbedding(
req.body.repo,
req.body.path,
req.body.branch,
req.body.limit
);
res.json({
status: 'Success',
message: 'Docs trained successfully.',
});
} catch (e) {
next(e); // Pass the error to the error handling middleware
}
});
If the training process is successful, the endpoint responds with a success message. If an error occurs during the process, it is passed to the error handling middleware.
A POST request to the endpoint will contain a request body like this:
{
"repo":"oceanbase/oceanbase-doc",
"path":"en-US",
"branch": "V4.1.0",
"limit": 1000
}
You can change the repository to other GitHub-hosted documentation you want. The path is the folder of the targeting content. In this case, I used “en-US” because I only want to train the English documentation of OceanBase. The branch parameter indicates the branch of the repo. In most cases, you can use the main branch or the branch of a certain version. The limit parameter is only used if a repository has too many files so that your GitHub API hits the limit.
This is how it looks like if the training is successful.

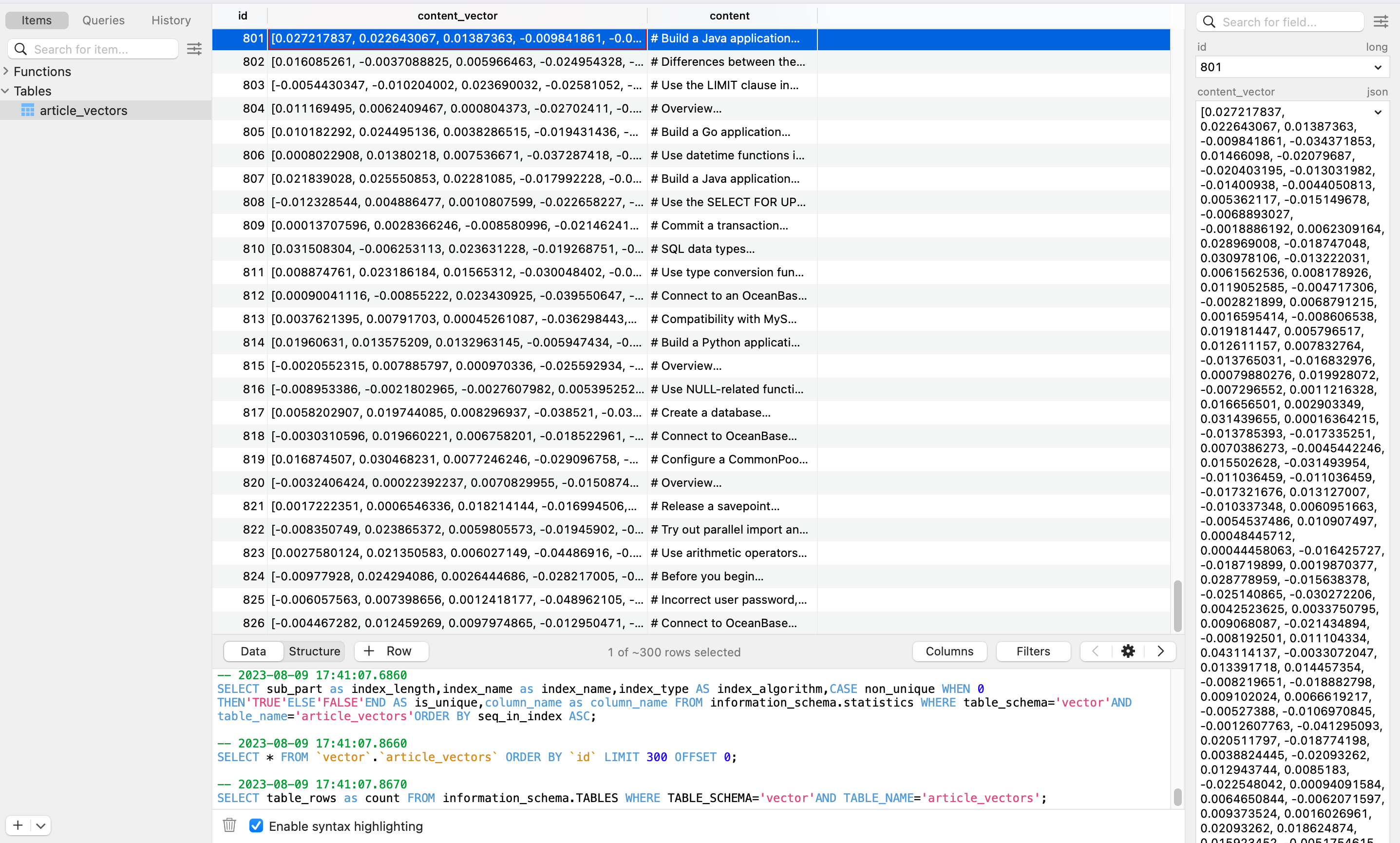
And in the OceanBase database, we can see all the records and their embeddings:
Asking Endpoint
The /ask endpoint is also a POST route. It expects a request body containing a user's question. This question is passed to the askAI() function, which finds the most relevant documentation and generates an answer using OpenAI's API.
app.post('/ask', async (req, res, next) => {
try {
const answer = await askAI(req.body.question);
res.json({
status: 'Success',
answer: answer.answer,
docId: answer.docId,
});
} catch (e) {
next(e); // Pass the error to the error handling middleware
}
});
The endpoint responds with the generated answer and the ID of the most relevant documentation. This is an example of a successful request.
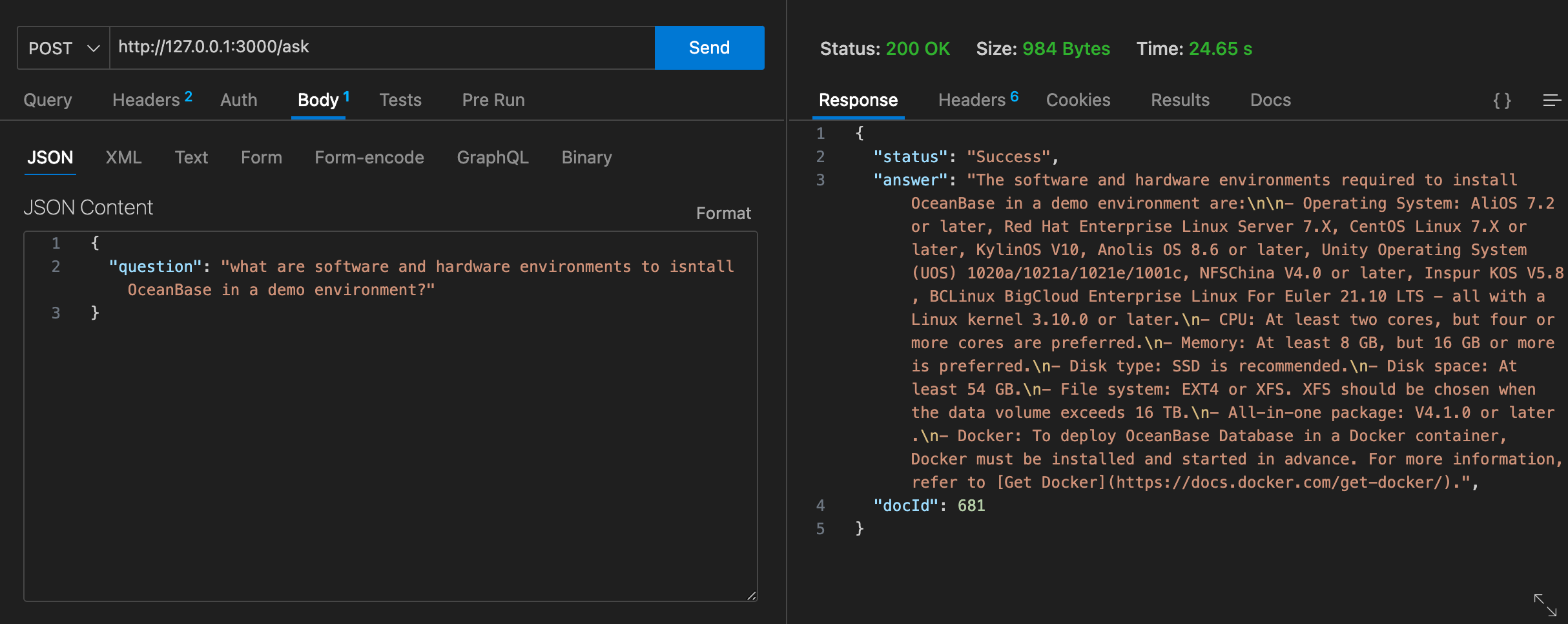
As we can see, when we ask the chatbot what are the software and hardware environments to install OceanBase in a demo environment, the chatbot provided an answer that is stated in this article.
Conclusion
This project represents an experiment in integrating AI with OceanBase to create a document chatbot. While it demonstrates the potential of AI in enhancing the usability of documentation, it's important to note that this is still an experimental setup and not yet ready for production use. The current implementation faces scalability issues due to the need to convert vectors into JSON for storage and back into vectors for comparison.
To fully leverage the potential of AI and machine learning, I would again recommend that the OceanBase team consider incorporating support for the vector data type. This would not only enhance the performance and scalability of the system but also position OceanBase as a forward-thinking database solution as AI becomes the next big thing. I have created an issue in the OceanBase GitHub repo to discuss this proposal, you are welcome to join the conversation.
The code for this project is available on GitHub for everyone to access and utilize. This means you can leverage the power of this AI-driven solution not only for OceanBase but also for any other document sets you might have. Feel free to clone the repository, explore the code, and use it as a base to train your own document chatbot using OceanBase. It's a great way to make your documents more interactive and accessible.
In conclusion, while there is still work to be done, this project represents a promising step toward using OceanBase as a vector database for AI training. With further development and refinement of the database, we can look forward to a time when finding answers in documentation is as simple as asking a question.
Published at DZone with permission of Wayne S. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments