Creating a Simple API Stub With API Gateway and S3
This post shows a nice way of using Mapping Templates in API Gateway to transform the path and create a simple stub.
Join the DZone community and get the full member experience.
Join For FreeA while ago my team was looking to create a stub for an internal JSON HTTP-based API. The to-be stubbed service was quite simple. The service exposed a REST API endpoint for listing resources of a specific type. The API supported paging and some specific request/query parameters.
GET requests to the service looked something like this:
/items?type=sometype&page=2
We wanted to create a simple stub for the service within our AWS account which we could use for testing. One of the tests we wanted to perform was to test if the service was down. If so, our application would follow a specific code path. We could of course not easily test this with the real services of the remote API, so we tried to keep things as simple as possible.
Creating the API With API Gateway, Lambda, and S3
As most of the services within our domain are based on Amazon API Gateway and AWS Lambda, we started looking into that direction at first. As our stub was read-only and we didn’t have to modify the items, we chose to create an initial export of the dataset from the remote API into JSON files, which we could store in S3. To store the files, we chose to use a file name pattern that resembled our type and page parameter.
{TYPE}_{PAGE_NUMER}(.json)
This resulted in a bucket like this:

The simplified design of the API stub was going to be as follows:
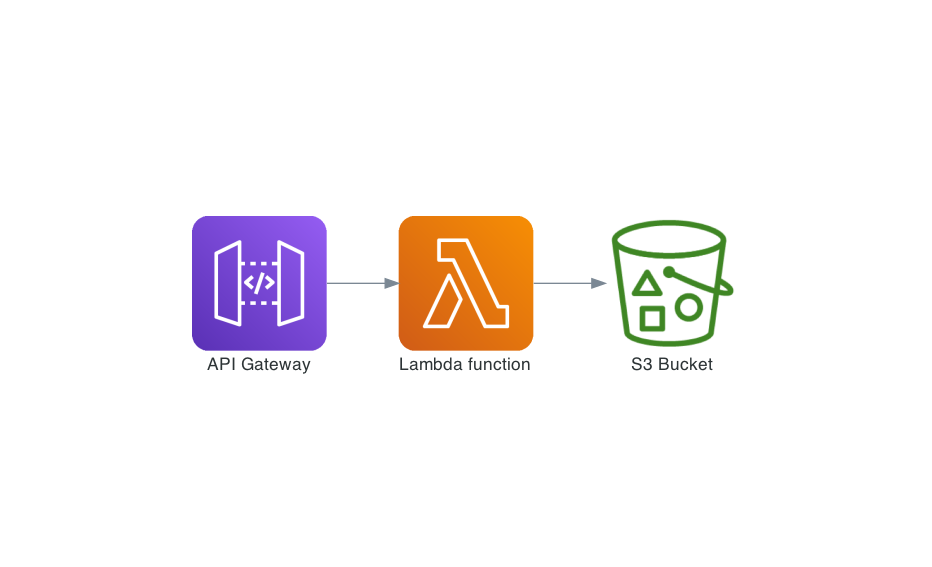
An example version of what our code looked like was something similar to this:
public static final String TYPE_QUERY_PARAM = "type";
public static final String JSON_FILE_EXTENSION = ".json";
public static final String PAGE_PREFIX = "_p";
private S3Client s3Client = S3Client.builder()
.region(Region.EU_WEST_1)
.httpClient(UrlConnectionHttpClient.builder().build())
.credentialsProvider(EnvironmentVariableCredentialsProvider.create())
.build();
@Override
public APIGatewayProxyResponseEvent handleRequest(APIGatewayProxyRequestEvent input, Context context) {
Map<String, String> queryStringParameters = input.getQueryStringParameters();
String page = queryStringParameters.getOrDefault("page", "1");
String type;
if(!queryStringParameters.containsKey(TYPE_QUERY_PARAM)){
throw new MissingTypeException("Parameter Type cannot be null");
} else {
type = queryStringParameters.get(TYPE_QUERY_PARAM);
}
String key = type + PAGE_PREFIX + page + JSON_FILE_EXTENSION;
ResponseInputStream<GetObjectResponse> s3ClientObject = s3Client
.getObject(GetObjectRequest
.builder()
.bucket("apigatelambdas3integrationdemo")
.key(key)
.build());
return new APIGatewayProxyResponseEvent()
.withStatusCode(200)
.withHeaders(
Map.of("Content-Type", s3ClientObject.response().contentType(),
"Content-Length", s3ClientObject.response().contentLength().toString()))
.withBody(getFileContentAsString(context, s3ClientObject));
}
private String getFileContentAsString(Context context, ResponseInputStream<GetObjectResponse> s3ClientObject) {
String fileAsString = "";
try (BufferedReader reader = new BufferedReader(new InputStreamReader(s3ClientObject))) {
fileAsString = reader.lines().collect(Collectors.joining(System.lineSeparator()));
} catch (IOException e) {
context.getLogger().log("Oops! Something went wrong while converting the file from S3 to a String");
e.printStackTrace();
}
return fileAsString;
}As you can see in the above snippet, we’re essentially calculating the path to the object in S3 based on some request parameters. When the path is resolved we just fetch the file from S3 and convert it to a string for the reply to API Gateway, which in turn returns the file to the consumer. Our lambda function was just acting as a simple proxy and we were wondering if we could get rid of the lambda function at all. Maintaining code, dependencies, etc. is a burden so if we don’t need it we would like to get rid of it.
Creating the API With Just API Gateway and S3
API Gateway has great support for direct integration with other AWS services, so we started exploring our options. The solution we hoped for was something similar to the image below.
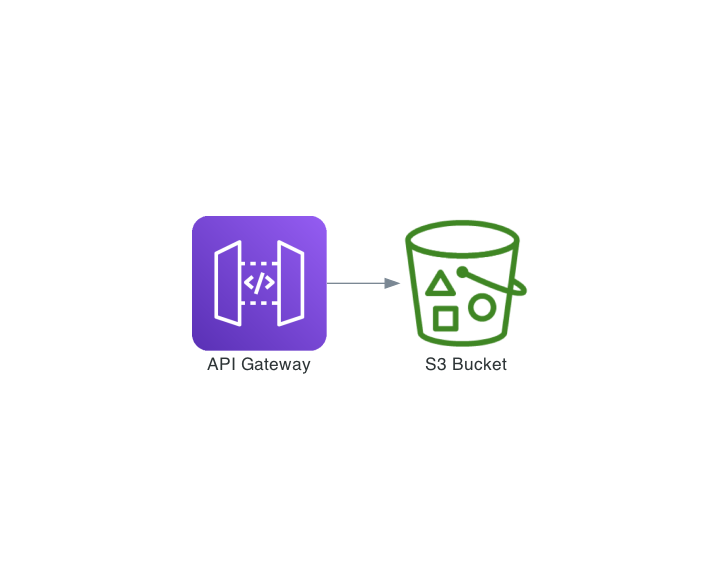
While going through the documentation for API Gateway we found a pretty good example of how to use API Gateway as a proxy for S3. The provided solution lets API Gateway mirror the folder and file structure(s) in S3: useful, but it did not cover our use case.
One of the other options that looked promising was configuring mapping templates. We had used that before to transform an incoming request body to a different format for the remote backend. In case you’re unfamiliar with mapping templates in API Gateway, a mapping template is a script expressed in Velocity Template Language (VTL) and applied to the payload using JSONPath expressions.
After digging through the API Gateway documentation we also discovered that mapping templates can be used to alter the query string, headers, and path.
| Request body mapping template | Response body mapping template |
|---|---|
| $context.requestOverride.header.header_name | $context.responseOverride.header.header_name |
| $context.requestOverride.path.path_name | $context.responseOverride.status |
| $context.requestOverride.querystring.querystring_name |
Modifying the path was exactly what we wanted, so we tried that and it worked like a charm. Let’s take a look at the resulting setup for our API Gateway GET request.
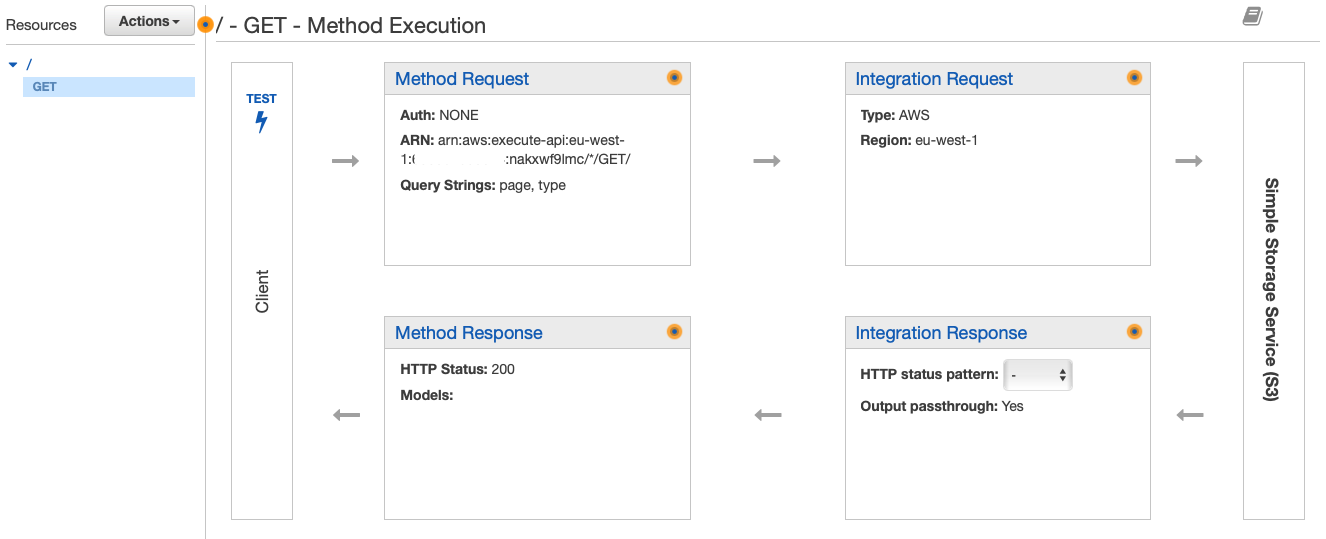
As you can see in the above section we’ve added a GET method to the root of our API. The GET method has a method request which defines both query parameters; page and type.
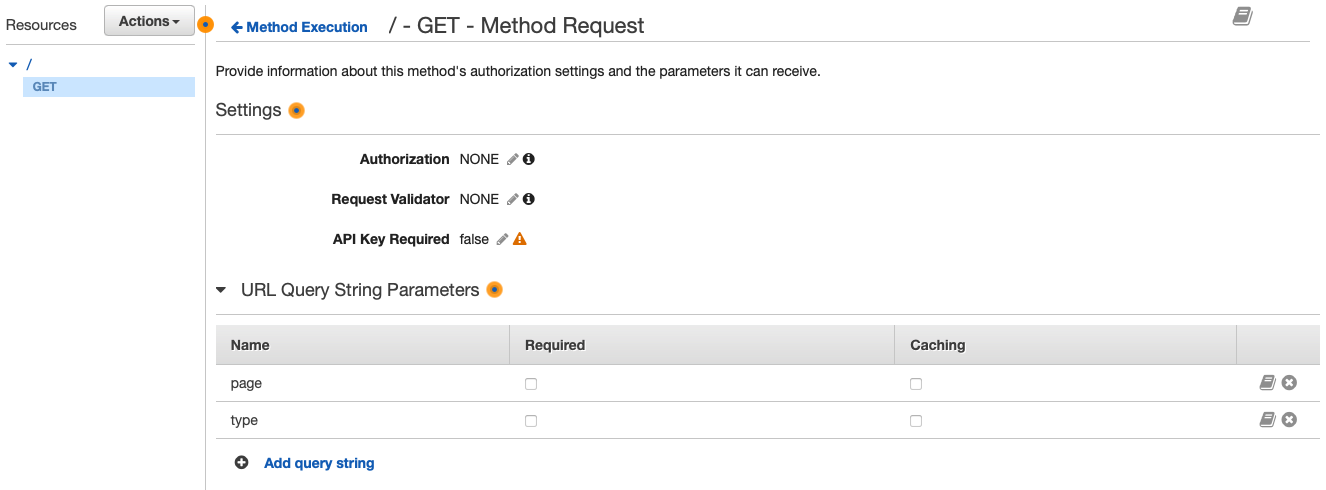
For the integration request, we define the remote service we want to integrate with and we specify the bucket and a dynamic fileName.
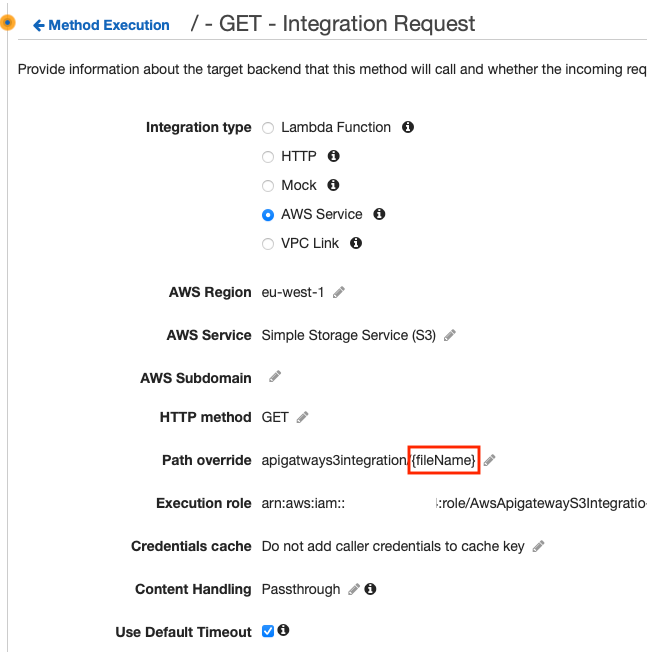
In the path override of the integration request there are two important things to notice:
- At the start of the Path override parameter, we provide the S3 bucket name.
- As the second argument, we provide a dynamic value named fileName.
The path override will therefor be {bucket-name}/{fileName}.
Now in our mapping template, we will fill the fileName parameter so that API Gateway knows which file to get from S3.
Let’s take a look at the mapping template.
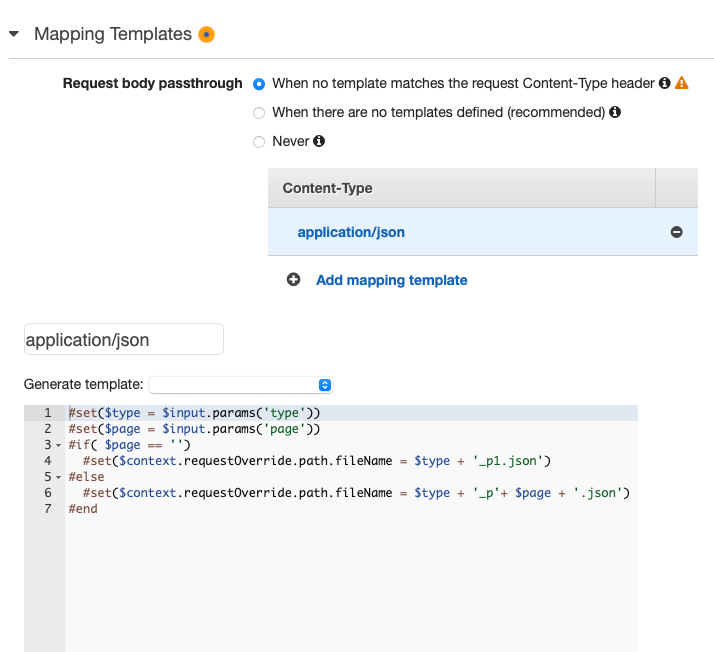
As you can see we’ve set up a template for requests for content-type application/json. Now when a GET request arrives with the type and page query parameters, it will assemble the resulting fileName variable in the path override.
#set($type = $input.params('type')
#set($page = $input.params('page'))
#if( $page == '')
#set($context.requestOverride.path.fileName = $type + '_p1.json')
#else
#set($context.requestOverride.path.fileName = $type + '_p'+ $page + '.json')
#endWhen the file in that specific bucket is found it will return the corresponding JSON. When the file is not found, it will throw a 404 response body. We can also map the response code with a mapping template to produce some nice-looking error messages.
Some Last Thoughts
While researching this solution I also came across a post by Tom Vincent. Tom wrote a nice post about what he calls Lambdaless. I like the term and it resonates well with what we also tried to achieve in this post.
I think this post shows a nice way of using Mapping Templates in API Gateway to transform the path and create a simple stub. Do keep in mind we use this for testing only and we don’t run production workloads with this setup. I also think that if the API would have been more complex we would not have taken this approach. Nevertheless, it was simple to set up and use for our stub.
Published at DZone with permission of Jeroen Reijn. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments