Creating Scalable, Compliant Cloud Data Pipelines in SaaS through AI Integration
Cloud-based AI data pipelines provide SaaS companies with scalable, cost-effective solutions for real-time insights and efficient data management.
Join the DZone community and get the full member experience.
Join For FreeData management is undergoing a rapid transformation and is emerging as a critical factor in distinguishing success within the Software as a Service (SaaS) industry. With the rise of AI, SaaS leaders are increasingly turning to AI-driven solutions to optimize data pipelines, improve operational efficiency, and maintain a competitive edge. However, effectively integrating AI into data systems goes beyond simply adopting the latest technologies. It requires a comprehensive strategy that tackles technical challenges, manages complex real-time data flows, and ensures compliance with regulatory standards.
This article will explore the journey of building a successful AI-powered data pipeline for a SaaS product. We will cover everything from initial conception to full-scale adoption, highlighting the key challenges, best practices, and real-world use cases that can guide SaaS leaders through this critical process.
1. The Beginning: Conceptualizing the Data Pipeline
Identifying Core Needs
The first step in adopting AI-powered data pipelines is understanding the core data needs of your SaaS product. This involves identifying the types of data the product will handle, the specific workflows involved, and the problems the product aims to solve. Whether offering predictive analytics, personalized recommendations, or automating operational tasks, each use case will influence the design of the data pipeline and the AI tools required for optimal performance.
Data Locality and Compliance
Navigating the complexities of data locality and regulatory compliance is one of the initial hurdles for SaaS companies implementing AI-driven data pipelines. Laws such as the GDPR in Europe impose strict guidelines on how companies handle, store, and transfer data. SaaS leaders must ensure that both the storage and processing locations of data comply with regulatory standards to avoid legal and operational risks.
Data Classification and Security
Managing data privacy and security involves classifying data based on sensitivity (e.g., personally identifiable information or PII vs. non-PII) and applying appropriate access controls and encryption. Here are some essential practices for compliance:

By addressing these challenges, SaaS companies can build AI-driven data pipelines that are secure, compliant, and resilient.
2. The Build: Integrating AI into Data Pipelines
Leveraging Cloud for Scalable and Cost-Effective AI-Powered Data Pipelines
To build scalable, efficient, and cost-effective AI-powered data pipelines, many SaaS companies turn to the cloud. Cloud platforms offer a wide range of tools and services that enable businesses to integrate AI into their data pipelines without the complexity of managing on-premises infrastructure. By leveraging cloud infrastructure, companies gain flexibility, scalability, and the ability to innovate rapidly, all while minimizing operational overhead and avoiding vendor lock-in.
Key Technologies in Cloud-Powered AI Pipelines
An AI-powered data pipeline in the cloud typically follows a series of core stages, each supported by a set of cloud services:
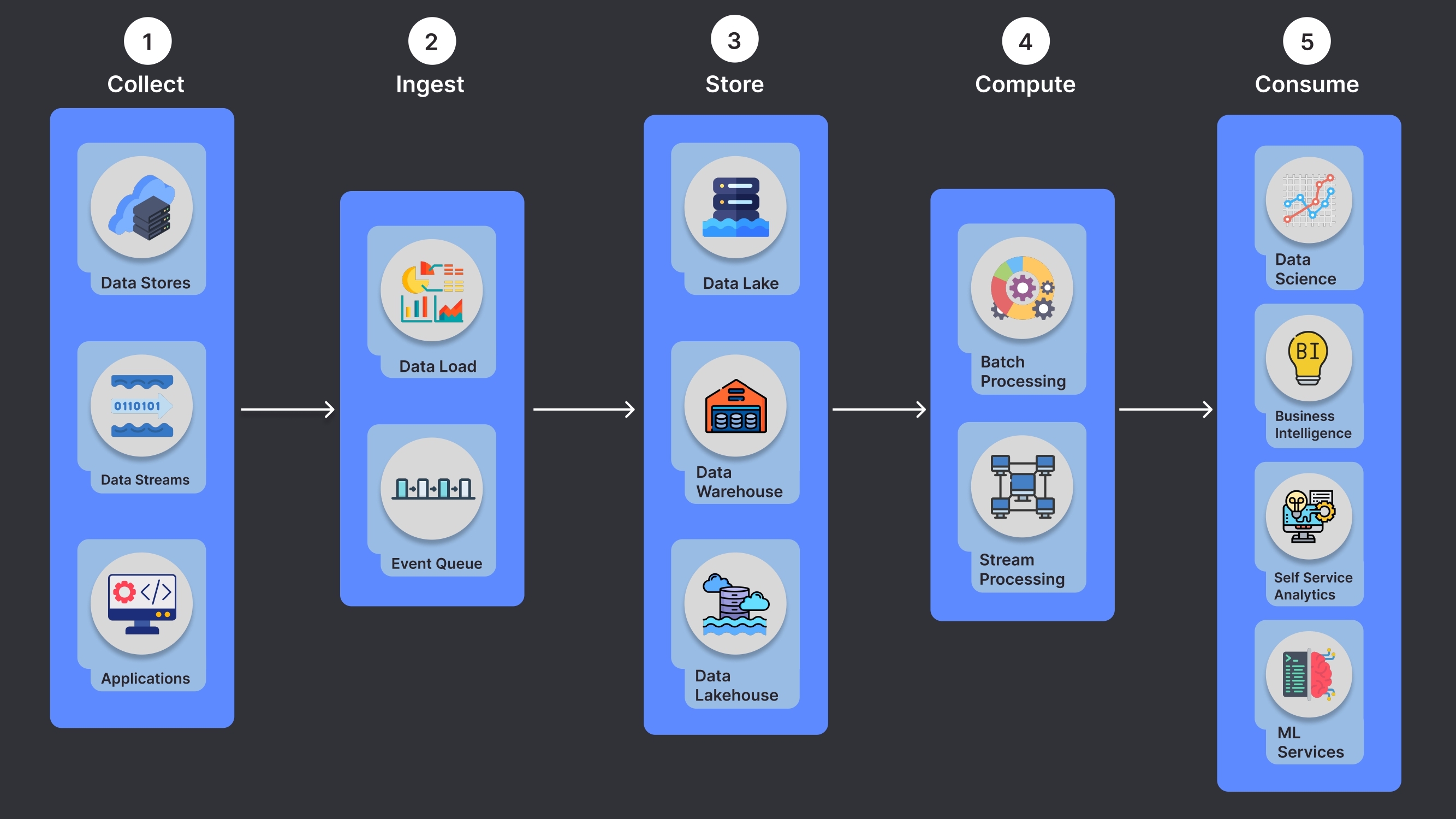
1. Data Ingestion
The first step in the pipeline is collecting raw data from various sources. Cloud services allow businesses to easily ingest data in real time from internal systems, customer interactions, IoT devices, and third-party APIs. These services can handle both structured and unstructured data, ensuring that no valuable data is left behind.
2. Data Storage
Once data is ingested, it needs to be stored in an optimized manner for processing and analysis. Cloud platforms provide flexible storage options, such as:
- Data Lakes: For storing large volumes of raw, unstructured data that can later be analyzed or processed.
- Data Warehouses: For storing structured data, performing complex queries, and reporting.
- Scalable Databases: For storing key-value or document data that needs fast and efficient access.
3. Data Processing
After data is stored, it needs to be processed. The cloud offers both batch and real-time data processing capabilities:
- Batch Processing: For historical data analysis, generating reports, and performing large-scale computations.
- Stream Processing: For real-time data processing, enabling quick decision-making and time-sensitive applications, such as customer support or marketing automation.
4. Data Consumption
The final stage of the data pipeline is delivering processed data to end users or business applications. Cloud platforms offer various ways to consume the data, including:
- Business Intelligence Tools: For creating dashboards, reports, and visualizations that help business users make informed decisions.
- Self-Service Analytics: Enabling teams to explore and analyze data independently.
- AI-Powered Services: Delivering real-time insights, recommendations, and predictions to users or applications.
Ensuring a Seamless Data Flow
A well-designed cloud-based data pipeline ensures smooth data flow from ingestion through to storage, processing, and final consumption. By leveraging cloud infrastructure, SaaS companies can scale their data pipelines as needed, ensuring they can handle increasing volumes of data while delivering real-time AI-driven insights and improving customer experiences.
Cloud platforms provide a unified environment for all aspects of the data pipeline — ingestion, storage, processing, machine learning, and consumption — allowing SaaS companies to focus on innovation rather than managing complex infrastructure. This flexibility, combined with the scalability and cost-efficiency of the cloud, makes it easier than ever to implement AI-driven solutions that can evolve alongside a business’s growth and needs.
3. Overcoming Challenges: Real-Time Data and AI Accuracy
Real-Time Data Access
For many SaaS applications, real-time data processing is crucial. AI-powered features need to respond to new inputs as they’re generated, providing immediate value to users. For instance, in customer support, AI must instantly interpret user queries and generate accurate, context-aware responses based on the latest data.
Building a real-time data pipeline requires robust infrastructure, such as Apache Kafka or AWS Kinesis, to stream data as it’s created, ensuring that the SaaS product remains responsive and agile.
Data Quality and Context
The effectiveness of AI models depends on the quality and context of the data they process. Poor data quality can result in inaccurate predictions, a phenomenon often referred to as "hallucinations" in machine learning models. To mitigate this:
- Implement data validation systems to ensure data accuracy and relevance.
- Train AI models on context-aware data to improve prediction accuracy and generate actionable insights.
4. Scaling for Long-Term Success
Building for Growth
As SaaS products scale, so does the volume of data, which places additional demands on the data pipeline. To ensure that the pipeline can handle future growth, SaaS leaders should design their AI systems with scalability in mind. Cloud platforms like AWS, Google Cloud, and Azure offer scalable infrastructure to manage large datasets without the overhead of maintaining on-premise servers.
Automation and Efficiency
AI can also be leveraged to automate various aspects of the data pipeline, such as data cleansing, enrichment, and predictive analytics. Automation improves efficiency and reduces manual intervention, enabling teams to focus on higher-level tasks.
Permissions & Security
As the product scales, managing data permissions becomes more complex. Role-based access control (RBAC) and attribute-based access control (ABAC) systems ensure that only authorized users can access specific data sets. Additionally, implementing strong encryption protocols for both data at rest and in transit is essential to protect sensitive customer information.
5. Best Practices for SaaS Product Leaders
Start Small, Scale Gradually
While the idea of designing a fully integrated AI pipeline from the start can be appealing, it’s often more effective to begin with a focused, incremental approach. Start by solving specific use cases and iterating based on real-world feedback. This reduces risks and allows for continuous refinement before expanding to more complex tasks.
Foster a Growth Mindset
AI adoption in SaaS requires ongoing learning, adaptation, and experimentation. Teams should embrace a culture of curiosity and flexibility, continuously refining existing processes and exploring new AI models to stay competitive.
Future-Proof Your Pipeline
To ensure long-term success, invest in building a flexible, scalable pipeline that can adapt to changing needs and ongoing regulatory requirements. This includes staying updated on technological advancements, improving data security, and regularly revisiting your compliance strategies.
6. Conclusion
Integrating AI into SaaS data pipelines is no longer optional — it’s a critical component of staying competitive in a data-driven world. From ensuring regulatory compliance to building scalable architectures, SaaS leaders must design AI systems that can handle real-time data flows, maintain high levels of accuracy, and scale as the product grows.
By leveraging open-source tools, embracing automation, and building flexible pipelines that meet both operational and regulatory needs, SaaS companies can unlock the full potential of their data. This will drive smarter decision-making, improve customer experiences, and ultimately fuel sustainable growth.
With the right strategy and mindset, SaaS leaders can turn AI-powered data pipelines into a significant competitive advantage, delivering greater value to customers while positioning themselves for future success.
Opinions expressed by DZone contributors are their own.
Comments