What Is a Data Pipeline?
In this post, we examine data pipelines, explore their benefits, compare them to other data processes, and discuss various implementation methods.
Join the DZone community and get the full member experience.
Join For FreeThe efficient flow of data from one location to another — from a SaaS application to a data warehouse, for example — is one of the most critical operations in today's data-driven enterprise. After all, useful analysis cannot begin until the data becomes available. Data flow can be precarious because so many things can go wrong during transportation from one system to another: data can become corrupted, it can hit bottlenecks (causing latency), or data sources may conflict and/or generate duplicates. As the complexity of the requirements grows and the number of data sources multiplies, these problems increase in scale and impact. To address these challenges, organizations are turning to data pipelines as essential solutions for managing and optimizing data flow, ensuring that insights can be derived efficiently and effectively.
How Do Data Pipelines Work?
A data pipeline is software that eliminates many manual steps from the process and enables a smooth, automated flow of data from one station to the next. It starts by defining what, where, and how data is collected. It automates the processes involved in extracting, transforming, combining, validating, and loading data for further analysis and visualization. It provides end-to-end velocity by eliminating errors and combating bottlenecks or latency. It can process multiple data streams at once. In short, it is an absolute necessity for today's data-driven enterprise.
Want to Become a Data Guru? Take Free Course: "Introduction to Data Engineering"
*Affiliate link. See Terms of Use.
A data pipeline views all data as streaming data, and it allows for flexible schemas. Regardless of whether it comes from static sources (like a flat-file database) or real-time sources (such as online retail transactions), the data pipeline divides each data stream into smaller chunks that it processes in parallel, conferring extra computing power. The data is then fed into processing engines that handle tasks like filtering, sorting, and aggregating the data. During this stage, transformations are applied to clean, normalize, and format the data, making it suitable for further use. Once the data has been processed and transformed, it is loaded into a destination, such as a data warehouse, database, data lake, or another application, such as a visualization tool. Think of it as the ultimate assembly line.
Who Needs a Data Pipeline?
While a data pipeline is not a necessity for every business, this technology is especially helpful for those that:
- Generate, rely on, or store large amounts of multiple sources of data.
- Maintain siloed data sources.
- Require real-time or highly sophisticated data analysis.
- Store data in the cloud.
Here are a few examples of who might need a data pipeline:
- E-commerce companies: To process customer transaction data, track user behavior, and deliver personalized recommendations in real time.
- Financial institutions: For real-time fraud detection, risk assessment, and aggregating data for regulatory reporting.
- Healthcare organizations: To streamline patient data management, process medical records, and support data-driven clinical decision-making.
- Media and entertainment platforms: For streaming real-time user interactions and content consumption data to optimize recommendations and advertisements.
- Telecommunications providers: To monitor network traffic, detect outages, and ensure optimal service delivery.
All of these industries rely on data pipelines to efficiently manage and extract value from large volumes of data. In fact, most of the companies you interface with on a daily basis — and probably your own — would benefit from a data pipeline.
5 Components of A Data Pipeline
A data pipeline is a series of processes that move data from its source to its destination, ensuring it is cleaned, transformed, and ready for analysis or storage. Each component plays a vital role in orchestrating the flow of data, from initial extraction to final output, ensuring data integrity and efficiency throughout the process. A data pipeline is made up of 5 components:
1. Data Sources
These are the origins of raw data, which can include databases, APIs, file systems, IoT devices, social media, and logs. They provide the input that fuels the data pipeline.
2. Processing Engines
These are systems or frameworks (e.g., Apache Spark, Flink, or Hadoop) responsible for ingesting, processing, and managing the data. They perform operations like filtering, aggregation, and computation at scale.
3. Transformations
This is where the raw data is cleaned, normalized, enriched, or reshaped to fit a desired format or structure. Transformations help make the data usable for analysis or storage.
4. Dependencies
These are the interconnections between various stages of the pipeline, such as task scheduling and workflow management (e.g., using tools like Apache Airflow or Luigi). Dependencies ensure that each stage runs in the correct sequence, based on the successful completion of prior tasks, enabling smooth, automated data flow.
5. Destinations
These are the systems where the processed data is stored, such as data warehouses (e.g., Amazon Redshift, Snowflake), databases, or data lakes. The data here is ready for use in reporting, analytics, or machine learning models.

Data Pipeline Architecture
Data pipeline architecture is the blueprint that defines how data flows from its origins to its final destination, guiding every step in the process. It outlines how raw data is collected, processed, and transformed before being stored or analyzed, ensuring that the data moves efficiently and reliably through each stage. This architecture connects various components, like data sources, processing engines, and storage systems, working in harmony to handle data at scale. A well-designed data pipeline architecture ensures smooth, automated data flow, allowing businesses to transform raw information into valuable insights in a timely and scalable way.
For example, a real-time streaming data pipeline might be used in financial markets, where data from stock prices, trading volumes, and news feeds is ingested in real time, processed using a system like Apache Kafka, transformed to detect anomalies or patterns, and then delivered to an analytics dashboard for real-time decision-making. In contrast, a batch data pipeline might involve an e-commerce company extracting customer order data from a database, transforming it to aggregate sales by region, and loading it into a data warehouse like Amazon Redshift for daily reporting and analysis.
Both architectures serve different use cases but follow the same underlying principles of moving and transforming data efficiently.
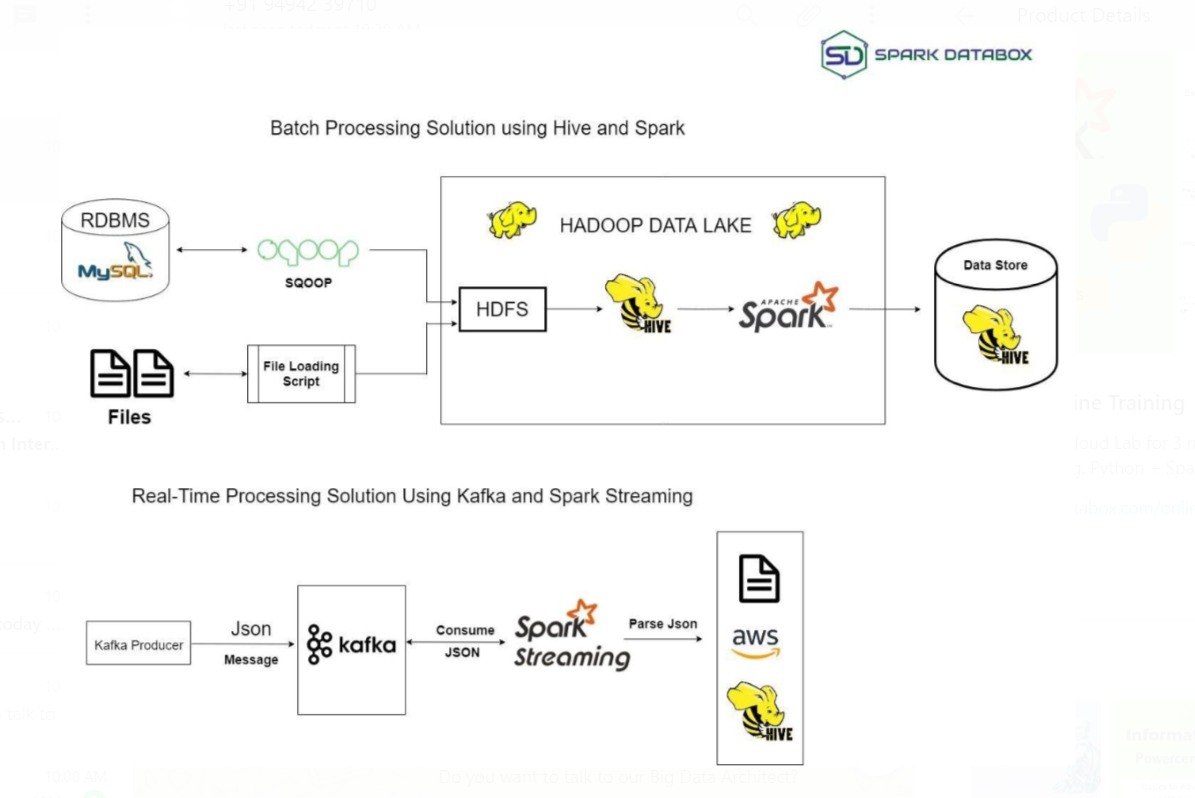 SparkDatabox, CC BY-SA 4.0, via Wikimedia Commons
SparkDatabox, CC BY-SA 4.0, via Wikimedia Commons
Data Pipeline vs. ETL Pipeline
You may commonly hear the terms ETL and data pipeline used interchangeably. ETL stands for Extract, Transform, and Load. ETL systems extract data from one system, transform the data, and load the data into a database or data warehouse. Legacy ETL pipelines typically run in batches, meaning that the data is moved in one large chunk at a specific time to the target system. Typically, this occurs in regularly scheduled intervals; for example, you might configure the batches to run at 12:30 a.m. every day when the system traffic is low.
By contrast, "data pipeline" is a broader term that encompasses ETL as a subset. It refers to a system for moving data from one system to another. The data may or may not be transformed, and it may be processed in real-time (or streaming) instead of batches. When the data is streamed, it is processed in a continuous flow, which is useful for data that needs constant updating, such as data from a sensor monitoring traffic. In addition, the data may not be loaded into a database or data warehouse. It might be loaded to any number of targets, such as an AWS bucket or a data lake, or it might even trigger a webhook on another system to kick off a specific business process.
8 Data Pipeline Use Cases
Data pipelines are essential for a wide range of applications, enabling businesses to efficiently handle, process, and analyze data in various real-world scenarios. Here are just a few use cases for data pipelines:
1. Real-Time Analytics
Stream and process live data from sources like IoT devices, financial markets, or web applications to generate real-time insights and enable rapid decision-making.
2. Data Warehousing
Ingest and transform large volumes of raw data from various sources into a structured format, then load it into a data warehouse for business intelligence and reporting.
3. Machine Learning
Automate the extraction, transformation, and loading (ETL) of data to feed machine learning models, ensuring the models are trained on up-to-date and clean datasets.
4. Customer Personalization
Process customer behavior data from e-commerce or social platforms to deliver personalized recommendations or targeted marketing campaigns in real time.
5. Log Aggregation and Monitoring
Collect, process, and analyze system logs from multiple servers or applications to detect anomalies, monitor system health, or troubleshoot issues.
6. Data Migration
Transfer data between storage systems or cloud environments, transforming the data as necessary to meet the requirements of the new system.
7. Fraud Detection
Continuously ingest and analyze transaction data to detect suspicious activity or fraudulent patterns, enabling immediate responses.
8. Compliance and Auditing
Automatically gather and process data required for regulatory reporting, ensuring timely and accurate submissions to meet compliance standards.
The Benefits of Leveraging Data Pipelines
Data pipelines provide many benefits for organizations looking to derive meaningful insights from their data efficiently and reliably. These include:
- Automation: Data pipelines streamline the entire process of data ingestion, processing, and transformation, reducing manual tasks and minimizing the risk of errors.
- Scalability: They allow organizations to handle growing volumes of data efficiently, ensuring that processing remains fast and reliable even as data increases.
- Real-Time Processing: Data pipelines can be designed to handle real-time data streams, enabling immediate insights and faster decision-making for time-sensitive applications.
- Data Quality and Consistency: Automated transformations and validation steps in the pipeline help ensure that the data is clean, consistent, and ready for analysis.
- Improved Decision-Making: With faster and more reliable data processing, pipelines enable organizations to make informed decisions based on up-to-date information.
- Cost Efficiency: By automating data flows and leveraging scalable infrastructure, data pipelines reduce the resources and time needed to process and manage large datasets.
- Centralized Data Access: Pipelines consolidate data from various sources into a single, accessible destination like a data warehouse, making it easier to analyze and use across departments.
- Error Handling and Recovery: Many pipelines are designed with fault tolerance, meaning they can detect issues, retry failed tasks, and recover from errors without disrupting the entire process.
The Challenges of Employing Data Pipelines
While data pipelines provide powerful solutions for automating data flow and ensuring scalability, they come with their own set of challenges. Building and maintaining a robust data pipeline requires overcoming technical hurdles related to data integration, performance, and reliability. Organizations must carefully design pipelines to handle the growing complexity of modern data environments, ensuring that the pipeline remains scalable, resilient, and capable of delivering high-quality data. Understanding these challenges is crucial for effectively managing data pipelines and maximizing their potential. With that in mind, here are some common challenges of employing data pipelines:
- Data Integration Complexity: Integrating data from multiple, diverse sources can be challenging, as it often involves handling different formats, structures, and protocols.
- Scalability and Performance: As data volumes grow, pipelines must be designed to scale efficiently without compromising performance or speed, which can be difficult to achieve.
- Data Quality and Consistency: Ensuring clean, accurate, and consistent data throughout the pipeline requires rigorous validation, error handling, and monitoring.
- Maintenance and Updates: Data pipelines need regular maintenance to handle changes in data sources, formats, or business requirements, which can lead to operational overhead.
- Latency in Real-time Systems: Achieving low-latency data processing in real-time systems is technically demanding, especially when handling large volumes of fast-moving data.
Future Trends in Data Pipelines
As data pipelines continue to evolve, new trends are emerging that reflect both the growing complexity of data environments and the need for more agile, intelligent, and efficient systems. With the explosion of data volume and variety, organizations are looking to future-proof their pipelines by incorporating advanced technologies like AI, cloud-native architectures, and real-time processing. These innovations are set to reshape how data pipelines are built, managed, and optimized, ensuring they can handle the increasing demands of modern data-driven businesses while maintaining security and compliance:
- Increased Use of AI and Machine Learning: Data pipelines will increasingly leverage AI and ML for automation in data cleaning, anomaly detection, and predictive analytics, reducing manual intervention and improving data quality.
- Real-Time Streaming Pipelines: The demand for real-time analytics is driving the shift from batch processing to real-time streaming pipelines, enabling faster decision-making for time-sensitive applications like IoT, finance, and e-commerce.
- Serverless and Cloud-Native Architectures: Cloud providers are offering more serverless data pipeline services, reducing the need for managing infrastructure and allowing organizations to scale pipelines dynamically based on demand.
- DataOps Integration: The rise of DataOps, focusing on collaboration, automation, and monitoring, is improving the efficiency and reliability of data pipelines by applying DevOps-like practices to data management.
- Edge Computing Integration: As edge computing grows, data pipelines will increasingly process data closer to the source (at the edge), reducing latency and bandwidth usage, particularly for IoT and sensor-driven applications.
- Improved Data Privacy and Security: As regulations around data privacy grow (e.g., GDPR, CCPA), pipelines will increasingly incorporate stronger data encryption, anonymization, and auditing mechanisms to ensure compliance and protect sensitive information.
These trends reflect the growing sophistication and adaptability of data pipelines to meet evolving business and technological demands.
Types of Data Pipeline Solutions
There are a number of different data pipeline solutions available, and each is well-suited to different purposes. For example, you might want to use cloud-native tools if you are attempting to migrate your data to the cloud.
The following list shows the most popular types of pipelines available. Note that these systems are not mutually exclusive. You might have a data pipeline that is optimized for both cloud and real-time, for example:
Batch
Batch processing is most useful when you want to move large volumes of data at a regular interval and you do not need to move data in real time. For example, it might be useful for integrating your marketing data into a larger system for analysis.
Real-Time
These tools are optimized to process data in real time. Real-time is useful when you are processing data from a streaming source, such as data from financial markets or telemetry from connected devices.
Cloud Native
These tools are optimized to work with cloud-based data, such as data from AWS buckets. These tools are hosted in the cloud, allowing you to save money on infrastructure and expert resources because you can rely on the infrastructure and expertise of the vendor hosting your pipeline.
Open Source
These tools are most useful when you need a low-cost alternative to a commercial vendor and you have the expertise to develop or extend the tool for your purposes. Open source tools are often cheaper than their commercial counterparts, but require expertise to use the functionality because the underlying technology is publicly available and meant to be modified or extended by users.
Building vs. Buying: Choosing the Right Data Pipeline Solution
Okay, so you're convinced that your company needs a data pipeline. How do you get started?
Building a Data Pipeline
You could hire a team to build and maintain your data pipeline in-house. Here's what it entails:
- Developing a way to monitor incoming data (whether file-based, streaming, or something else).
- Connecting to and transforming data from each source to match the format and schema of its destination.
- Moving the data to the target database/data warehouse.
- Adding and deleting fields and altering the schema as company requirements change.
- Making an ongoing, permanent commitment to maintaining and improving the data pipeline.
Count on the process being costly both in terms of resources and time. You'll need experienced (and thus expensive) personnel, either hired or trained, and pulled away from other high-value projects and programs. It could take months to build, incurring significant opportunity costs. Lastly, it can be difficult to scale these types of solutions because you need to add hardware and people, which may be out of budget.
Buying a Data Pipeline Solution
A simpler, more cost-effective solution is to invest in a robust data pipeline. Here's why:
- You get immediate, out-of-the-box value, saving you the lead time involved in building an in-house solution.
- You don't have to pull resources from existing projects or products to build or maintain your data pipeline.
- If or when problems arise, you have someone you can trust to fix the issue, rather than having to pull resources off of other projects or failing to meet an SLA.
- It gives you an opportunity to cleanse and enrich your data on the fly.
- It enables real-time, secure analysis of data, even from multiple sources simultaneously, by storing the data in a cloud data warehouse.
- You can visualize data in motion.
- You get peace of mind from enterprise-grade security and a 100% SOC 2 Type II, HIPAA, and GDPR compliant solution.
- Schema changes and new data sources are easily incorporated.
- Built-in error handling means data won't be lost if loading fails.
Conclusion
Data pipelines have become essential tools for organizations seeking to maximize value from their data assets. These automated systems streamline data flow from source to destination, offering benefits such as scalability, real-time processing, and improved decision-making. While they present challenges like integration complexity and maintenance needs, the advantages far outweigh the drawbacks for data-driven businesses.
When considering a data pipeline solution, organizations must weigh the pros and cons of building in-house versus investing in pre-built solutions. While in-house development offers customization, pre-built solutions provide immediate value and scalability without the resource drain of ongoing maintenance.
As data continues to grow in importance, it's crucial that your organization takes the time to assess its data management needs. Explore the various data pipeline solutions available and consider how they align with your business goals. By implementing an effective data pipeline, you can transform raw data into a powerful driver of business insights and competitive advantage in our increasingly data-centric world.
Opinions expressed by DZone contributors are their own.
Comments