Automating Data Pipelines With Snowflake: Leveraging DBT and Airflow Orchestration Frameworks for ETL/ELT Processes
This article explores the automation of data pipelines using Snowflake, dbt, and Airflow, detailing best practices for efficient data processing and orchestration.
Join the DZone community and get the full member experience.
Join For FreeIn the era of digitization and data landscape, automating data pipelines is crucial for enhanced efficiency, consistency, and scalability of the lake house. Snowflake is a leading cloud data platform that integrates seamlessly with various tools to facilitate the automation of ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes.
This article delves into automating data pipelines with Snowflake by leveraging dbt (data build tool) and orchestration frameworks and the best practices for streamlining data workflows to ensure reliable data processing.
What Is dbt?
The tool, dbt stands for "data build tool." It's a command-line tool used in data engineering to build and manage data transformation workflows.
It can turn raw data into a more structured, organized form of data by defining, running, and documenting SQL-based transformations.
dbt facilitates in:
- Write SQL: Create models (SQL files) that define how raw data should be transformed.
- Test: Implement tests to ensure data quality and integrity.
- Document: Document your data models and transformations, which makes it easier for teams to collaborate easily.
- Schedule: Automate and schedule data transformations using schedulers like Airflow.
It's often used with data warehouses like Snowflake, Big Query, or Redshift. You can create a more organized and maintainable data pipeline using dbt.
What Is Airflow?
Apache Airflow is an open-source platform used to programmatically author, schedule, and monitor workflows. It is designed to manage complex data pipelines and workflows, which makes it easier to orchestrate and automate tasks.
Key Components of Airflow
- Directed Acyclic Graphs (DAGs): Workflows in Airflow are defined as Directed Acyclic Graphs (DAGs), which are a series of tasks with dependencies. Each task represents a unit of work, and the DAG defines the sequence in which tasks should be executed.
- Task Scheduling: Airflow allows you to schedule tasks to run at specific time intervals, enabling you to automate repetitive processes.
- Task Monitoring: It provides a web-based interface where you can monitor the progress of your workflows, check logs, and view the status of each task.
- Extensibility: Airflow supports custom operators and hooks, allowing you to integrate various systems and services. It has a rich ecosystem of plugins and extensions to delve into different use cases.
- Scalability: It’s designed to scale with your needs. You can run Airflow on a single machine or deploy it across a cluster to handle larger workloads.
- Dynamic Pipeline Generation: Pipelines in Airflow can be generated dynamically, which is useful for creating complex workflows that can change based on input parameters or conditions.
Airflow is used in data engineering to manage ETL (Extract, Transform, Load) processes and its flexibility allows it to handle a wide range of workflow automation tasks beyond data processing.
Flow Diagram:
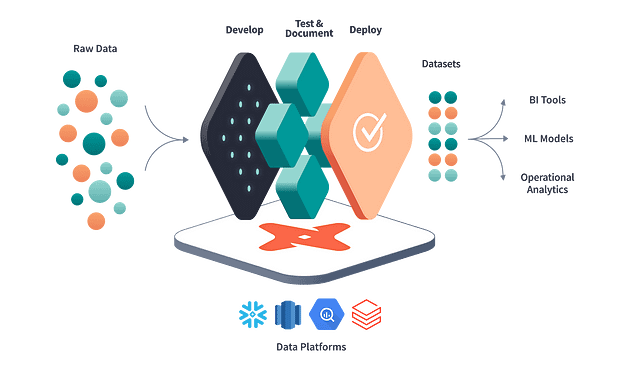
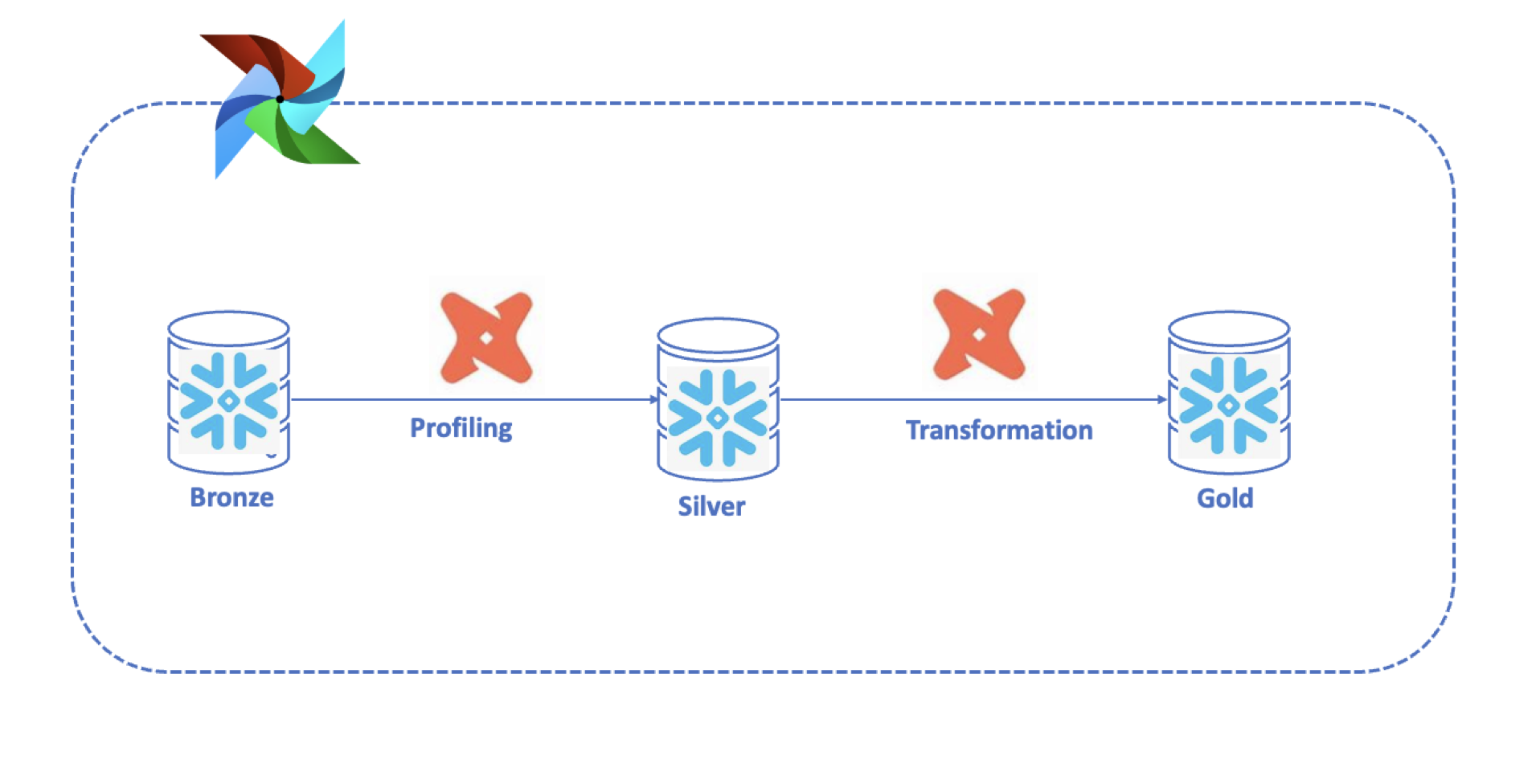
Figure-1: Data pipeline on Snowflake DB with dbt and Airflow Orchestrator
Data Ingestion
dbt can’t handle extraction activities and should be used with other tools to extract data from sources.
Below is a Python wrapper that extracts data from an S3 bucket and integrates with Snowflake.
Python Script for Data Extraction:
import pandas as pd
from snowflake.connector import connect
# Extract data from an external source (e.g., a CSV file on S3)
def extract_data():
import boto3
s3 = boto3.client('s3')
bucket_name = 'your_bucket'
file_key = 'data/transactions.csv'
response = s3.get_object(Bucket=bucket_name, Key=file_key)
df = pd.read_csv(response['Body'])
return df
# Load data into Snowflake
def load_data_into_snowflake(df):
conn = connect(
user='your_username',
password='your_password',
account='your_snowflake_account',
warehouse='your_warehouse',
database='your_database',
schema='your_schema'
)
cursor = conn.cursor()
# Create or replace a stage to load the data
cursor.execute("CREATE OR REPLACE STAGE my_stage")
# Write DataFrame to a temporary CSV file
df.to_csv('/tmp/transactions.csv', index=False)
# Upload the file to Snowflake stage
cursor.execute(f"PUT file:///tmp/transactions.csv @my_stage")
# Copy data into a Snowflake table
cursor.execute("""
COPY INTO my_table
FROM @my_stage/transactions.csv
FILE_FORMAT = (TYPE = 'CSV', FIELD_OPTIONALLY_ENCLOSED_BY = '"')
""")
conn.close()
df = extract_data()
load_data_into_snowflake(df)
Transform With dbt
Once the data is loaded into Snowflake, the dbt engine can be triggered to perform transformations.
Aggregating Sales Data
Create a dbt model to aggregate sales data by product category.
File: models/aggregate_sales.sql
WITH sales_data AS (
SELECT
product_category,
SUM(sales_amount) AS total_sales,
COUNT(*) AS total_orders
FROM {{ ref('raw_sales') }}
GROUP BY product_category
)
SELECT
product_category,
total_sales,
total_orders,
CASE
WHEN total_sales > 100000 THEN 'High'
WHEN total_sales BETWEEN 50000 AND 100000 THEN 'Medium'
ELSE 'Low'
END AS sales_category
FROM sales_data
Data Quality Testing
dbt has a framework to test the quality of the dataset that is processing and also ensures the data’s freshness.
File: tests/test_null_values.sql
SELECT *
FROM {{ ref('raw_sales') }}
WHERE sales_amount IS NULL
Calculating Metrics
You could model your dataset and calculate your monthly revenue trends using dbt.
File: models/monthly_revenue.sql
WITH revenue_data AS (
SELECT
EXTRACT(YEAR FROM order_date) AS year,
EXTRACT(MONTH FROM order_date) AS month,
SUM(sales_amount) AS total_revenue
FROM {{ ref('raw_sales') }}
GROUP BY year, month
)
SELECT
year,
month,
total_revenue,
LAG(total_revenue) OVER (PARTITION BY year ORDER BY month) AS previous_month_revenue
FROM revenue_data
Load Data to Snowflake
dbt does not handle the actual loading of raw data into Snowflake and can handle transforming and modeling the data once it is loaded into the warehouse. For a typical load activity, we have to use an orchestrator to load and integrate with your data model.
Loading Transformed Data
File: models/production_load.sql
-- Load transformed data into a production table
CREATE OR REPLACE TABLE production_sales_data AS
SELECT *
FROM {{ ref('monthly_revenue') }}
Orchestrate Pipeline Using Airflow
With Airflow to orchestrate your ETL pipeline, you can define a DAG to execute dbt models as part of the transformation:
from airflow import DAG
from airflow.operators.docker_operator import DockerOperator
from airflow.operators.python_operator import PythonOperator
from airflow.providers.snowflake.operators.snowflake import SnowflakeOperator
from datetime import datetime
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 1, 1),
'retries': 1,
}
dag = DAG(
'example_etl_with_dbt',
default_args=default_args,
description='ETL pipeline with dbt transformations',
schedule_interval='@daily',
)
def extract_data():
import boto3
import pandas as pd
s3 = boto3.client('s3')
bucket_name = 'your_bucket'
file_key = 'data/transactions.csv'
response = s3.get_object(Bucket=bucket_name, Key=file_key)
df = pd.read_csv(response['Body'])
df.to_csv('/tmp/transactions.csv', index=False)
def load_data_into_snowflake():
from snowflake.connector import connect
conn = connect(
user='your_username',
password='your_password',
account='your_snowflake_account',
warehouse='your_warehouse',
database='your_database',
schema='your_schema'
)
cursor = conn.cursor()
cursor.execute("CREATE OR REPLACE STAGE my_stage")
cursor.execute("PUT file:///tmp/transactions.csv @my_stage")
cursor.execute("""
COPY INTO raw_sales
FROM @my_stage/transactions.csv
FILE_FORMAT = (TYPE = 'CSV', FIELD_OPTIONALLY_ENCLOSED_BY = '"')
""")
conn.close()
def run_dbt_models():
import subprocess
subprocess.run(["dbt", "run"], check=True)
extract_task = PythonOperator(
task_id='extract',
python_callable=extract_data,
dag=dag,
)
load_task = PythonOperator(
task_id='load',
python_callable=load_data_into_snowflake,
dag=dag,
)
transform_task = PythonOperator(
task_id='transform',
python_callable=run_dbt_models,
dag=dag,
)
extract_task >> load_task >> transform_task
Deploy and Test the Data Pipeline
Deploying and testing the data pipelines with Snowflake (DWH), dbt (data transformer), and Airflow (Orchestrator) require the following steps:
Set Up Your Environment
- Snowflake Account: Create the account, databases, schemas, stages, tables, objects, etc. required for the transformation journey with the required permissions.
- dbt Installed: You should have dbt configured to connect to Snowflake.
- Orchestration Tool: Apache Airflow tool should be installed and configured.
Deploy the Data Pipeline
Step 1: Prepare Your dbt Project
Initialize dbt Project.
Bash:
dbt init my_project
cd my_projectUpdate the profiles.yaml file with Snowflake connection details.
my_project:
target: dev
outputs:
dev:
type: snowflake
account: your_snowflake_account
user: your_username
password: your_password
role: your_role
warehouse: your_warehouse
database: your_database
schema: your_schema
threads: 4Define your models in the model's directory,
e.g., models/aggregate_sales.sql , models/monthly_revenue.sql , etc.
Then, run dbt models locally to ensure it is working as expected before deploying:
Bash:
dbt run
dbt testStep 2: Configure Apache Airflow
Install Apache Airflow and initialize the database:
Bash:
pip install apache-airflow
airflow db initDefine an Airflow DAG to orchestrate the ETL pipeline. Deploy the earlier code dags/Snowflake_Transformation_etl_dag.py:
Step 3. Start Airflow Services
Start the Airflow web server and scheduler:
Bash:
airflow webserver --port 8080
airflow schedulerTest the Pipeline End to End
Testing is key to ensure your pipeline works correctly from extraction to loading.
Unit Tests: Test your extraction scripts independently. Verify that data is correctly extracted from the source and loaded into Snowflake.
# Test extraction function
def test_extract_data():
df = extract_data()
assert df is not None
assert len(df) > 0
Integration Tests: Run the complete pipeline from extraction through to the loading phase in a test environment to validate the entire workflow.
Testing Transformation
dbt Tests: Use dbt’s built-in testing features to ensure data quality and consistency.
dbt testValidate Models: Query the resulting tables in Snowflake to ensure transformations are applied correctly.
SELECT * FROM production_sales_data;Testing Loading
- Verify Data Load: Check the target tables in Snowflake to ensure data is loaded as expected.
- Data Quality Checks: Perform checks on the loaded data to validate that it matches the expected results.
SELECT COUNT(*) FROM raw_sales;Conclusion
By combining dbt’s powerful transformation capabilities with Snowflake’s scalable data platform and orchestration tools like Airflow, organizations can build robust and automated data pipelines.
Opinions expressed by DZone contributors are their own.
Comments