Are Your ELT Tools Ready for Medallion Data Architecture?
To effectively execute ELT in Medallion Data Architecture, it is important to comprehend the data integration capabilities.
Join the DZone community and get the full member experience.
Join For FreeAs the world takes a multi-layered approach to data storage, there is a shift in how organizations transform data. It has driven businesses to integrate extract, load, and transform (ELT) tools with Medallion architecture. This trend reshapes how data is ingested and transformed across lines of business as well as by departmental users, data analysts, and C-level executives. Applying rigid data transformation rules and making data available for your teams through a data warehouse may not fully address your business's evolving and exploratory data integration needs.
Depending on the volume of data your organization produces and the rate at which it's generated, processing data without knowing the consumption patterns could prove to be costly. Case-based data transformation could be more economically viable as more ad-hoc queries and analyses pop up every day. That doesn't mean you store the data in raw form. Instead, it's necessary to add several layers of transformations, enrichments, and business rules to optimize cost and performance.
How Business Requirements Shape Database Technologies
Let's take a quick look at how data management has evolved. We started with cloud data warehouses. Traditional data warehouses, such as those based on relational database systems, have been the backbone of enterprise data management for years. They're optimized for structured data and typically used for business intelligence and reporting.
Then, we moved into the era of data lakes. Data lakes became popular for handling large volumes of structured and unstructured data. They offer flexibility in data storage and processing, allowing organizations to store raw and diverse data in its native format.
Now, we have data lakehouses. The concept of a data lakehouse emerged as a response to some of the challenges associated with data lakes, such as data quality, data governance, and the need for transactional capabilities. The data lakehouse architecture aims to combine the best features of data lakes and data warehouses, combining the scalability and flexibility of data lakes with the reliability and performance of data warehouses. Technologies like Delta Lake and Apache Iceberg have contributed to developing the data lakehouse concept by adding transactional capabilities and schema enforcement to data lakes.
To fully leverage the potential of this evolving architecture, we recommend implementing best practices, one of which is medallion architecture.
What Is Medallion Architecture?
Medallion architecture is gaining popularity in the data world. Unlike traditional data lake architectures, where raw or unstructured data is stored without any schema enforcement or strong consistency guarantees, medallion architecture introduces structure and organization to your data. It allows you to add schema evolution capabilities to your datasets stored in Delta Lake, making it easier to query and analyze your data effectively.
One of the reasons why medallion architecture is gaining popularity is its ability to handle large volumes of diverse data types in a scalable manner. By leveraging Delta Lake's transactional capabilities, you can ensure Atomic, Consistent, Independent, and Durable (ACID) compliance for your operations on massive datasets.
But how does it differ from traditional data lake architectures? While both approaches store raw or unstructured data, medallion architecture introduces a systematic method of defining bronze, silver, and gold layers within a data lake. This allows data engineers to curate the right data for the right audience. It also makes it easier for users to query and analyze their datasets without sacrificing performance or reliability.
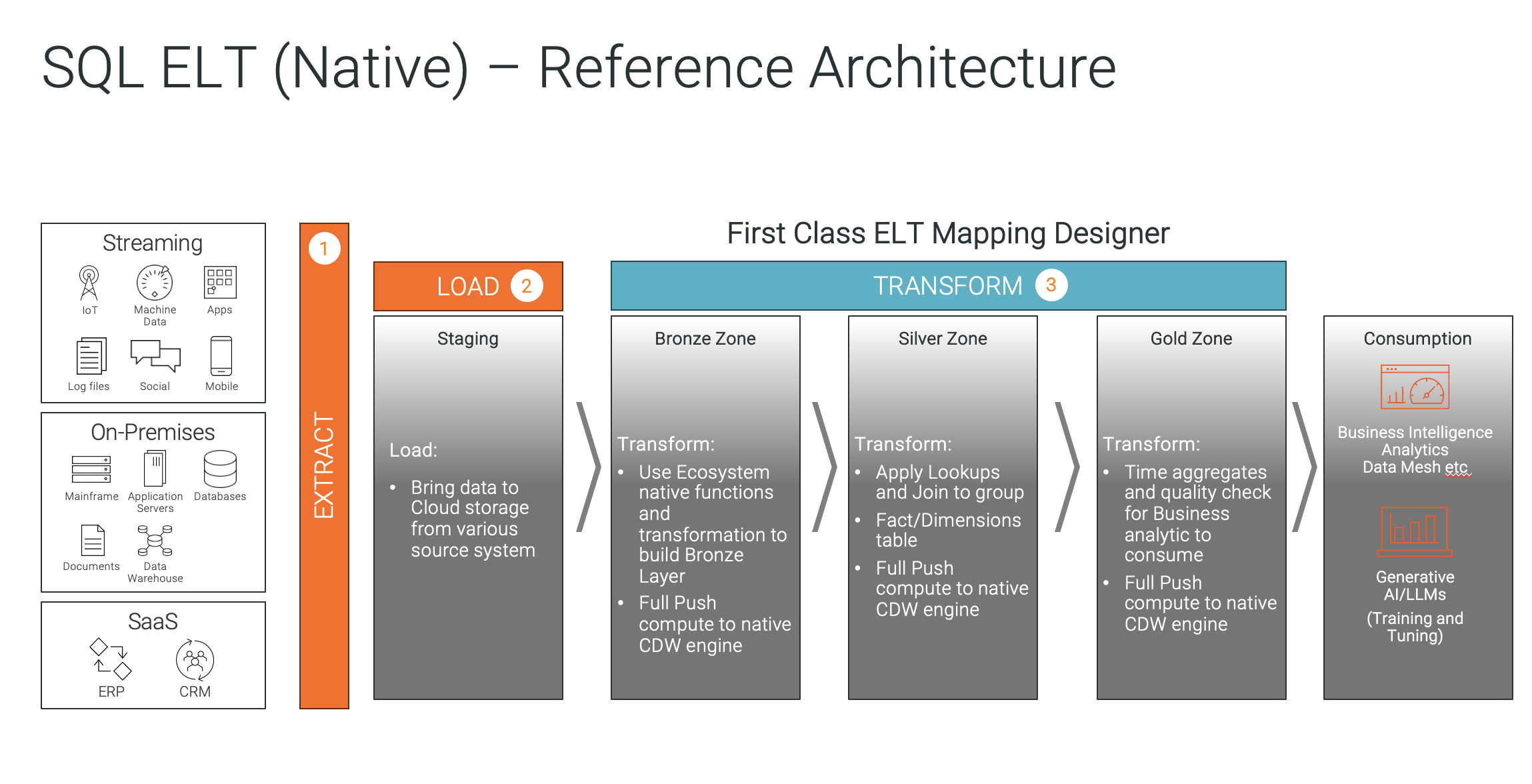
This shows an SQL ELT (native) reference architecture.
This is why medallion architecture is taking off in the realm of Delta Lake and cloud data warehousing. It offers a powerful combination of scalability, reliability, performance, and structured storage for your valuable datasets. Now, let's explore how data processing needs to change along with changes in architecture.
Why Is ELT the Right Data Transformation Process for Medallion Architecture?
As defined, there are several layers in Medallion data architecture. Data is progressively processed and refined as it moves through these layers. Using traditional extract, transform, load (ETL) can be inefficient, as it often requires moving data out of your data warehouse or lakehouse for every transformation, which is needed for the next processing level.
Instead, a more effective approach is to use pushdown technology, where you push the code into the target/source, allowing data processing to occur where it resides. In this case, only the data transformation code moves, not the data itself. ELT further streamlines this process by enabling you to transform the data as many times as you want, making your system more efficient. With ELT, you reduce the burden on the source system, as the data is ingested only once into the data lake/lakehouse.
The optimal design of ELT provides several competitive advantages. It enables you to process large volumes of data more rapidly, accelerating insights and decision-making. It also reduces operational costs by minimizing unnecessary data movement across networks and systems.
Necessary Data Integration Capabilities to Run ELT in Medallion Data Architecture
A few specific data integration capabilities will enable you to run ELT successfully in Medallion data architecture. These include:
- Parallel processing at scale: This is a must-have technology that runs your ELT code on multiple machines at the same time, which can improve the performance of your data jobs. A processing engine like Spark can handle massive datasets by scaling out to larger clusters and adding more nodes. The scheduler distributes tasks to worker nodes, balancing workload and maximizing resource utilization.
- Data loading patterns: Make sure the tool doesn't solely rely on batch load but also supports real-time streaming and full and incremental loads. Change data capture (CDC) and schema drift are the most frequently used features when transferring data from the sources to a data lakehouse.
- Optimized data processing at each stage: Medallion architecture is a system for logically organizing data within a data lakehouse. Each layer in a Medallion architecture serves a different purpose, and transformations are applied while considering the security boundaries, retention rules, user access policies, required latency, and business impact level. You should be able to process data at a granular level, optimizing it for the next step of logical data processing.
- Preview code during design time: This capability allows you to see the results of your ELT code before you run it, which can help you catch errors and ensure your code is doing what you want it to do.
- Multi-cloud support: Don't limit your integration capabilities to one particular ecosystem. Ensure you can run your data pipeline jobs in multiple cloud environments, such as Snowflake, Databricks, Amazon Web Services (AWS), Microsoft Azure, and Google Cloud.
- Auto tuning: This lets your ELT tool automatically adjust the settings of your jobs to improve their performance. The tool should be AI-enabled to collect runtime statistics and adjust execution strategies based on data characteristics.
- Flexible transformation: ELT tools must allow flexible transformation logic, as transformations can be performed using a wider range of tools and techniques, including SQL, Python, and Spark. This can be useful if you need to perform complex transformations not supported by SQL.
- Combine SQL code with proprietary code: This enables you to use both SQL code and proprietary code in a single ELT pipeline. This can be useful if you need to perform tasks not supported by SQL. For example, you might use SQL to query the database and retrieve the data, then write a Python function to implement a data quality check, applying custom logic to identify and address any data issues.
- End-to-end workflow: This capability provides a visual interface that allows you to design and execute your ELT jobs as part of a complete task flow. The tool should enable the scheduling and orchestration of a set of tasks, starting from extracting data to triggering downstream tasks, managing dependencies, and enabling data observability.
- Security, access control, and masking capabilities: This allows you to control who has access to your data and to mask sensitive data. This is important for protecting your data from unauthorized access.
- The ability to implement DataOps: This gives you the ability to integrate your ETL processes with your DevOps processes. This can help you to improve the quality and reliability of your data.
- Easy switching between ETL and ELT: This makes it easy for you to switch between ETL and ELT processing. This can be useful if you need to change your data processing strategy.
- Data transformation as a code: This makes it possible for you to store your ETL code in a repository, making it easier to manage and version your code.
- Advanced transformation: When ELT becomes your mainstream way of processing data, you need to ensure you don't have to run to different tools for complex transformations.
- Data quality: This gives you the ability to identify and address data quality issues early in your ELT process. This can help you to improve the quality of your data.
- Integration with data lineage and governance: This capability allows you to track the origins and transformations of your data. This can help you ensure your data complies with your data governance policies. The ELT tool should integrate seamlessly with your data lineage and governance frameworks to maintain data traceability, consistency, and security. It should provide visibility into data origins, transformations, and destinations, enabling effective data auditing and compliance with data governance policies.
Next Steps
It's crucial for your business to select an ELT tool that's high-performing and also compatible with Medallion data architecture. This will enhance data integration capabilities, allowing you to utilize the structured, layered approach of Medallion architecture fully. This alignment will give your business a competitive edge by efficiently handling large data volumes, improving scalability, streamlining workflow processes, and achieving cost efficiencies.
Opinions expressed by DZone contributors are their own.
Comments