An Implementation of Change Data Capture
CDC can be used as a tool to reduce data processing in legacy applications and share the data changes with target systems in real-time.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Most enterprise applications generally have relational databases as their persistent data store. Operations on these applications lead to the creation, updating, and deletion of data from tables within relational databases. Downstream applications look at change logs to find out the changes happening in the source systems. The incremental data is essential in processing very specific changes to business data, thereby avoiding the full processing of entire data within operational databases.
A new era of applications provides subscription-based services for publishing the changes of the relevant business data. Initial data loads must be performed prior to sending the captured changes from source systems. However, on some legacy application databases, replication tools cannot be used without needing substantial changes to legacy applications. Downstream systems are then forced to load entire content from the operational database to process and generate incremental meaningful information as part of overnight batch jobs. This approach increases overall batch execution time and increases strain on infrastructure due to additional load processed on a period (daily/weekly/monthly) basis.
Problem Statement
A custom Change Data Capture solution is needed to capture the data via a change log pointing to specific change events generated by the source system on z/OS using IMS as a database and transform the data into near real-time to the downstream consumers. Latency has been reduced from days to near real-time with the proposed solution.
Purpose
The purpose of this white paper is to provide a solution for a custom Change Data Capture (CDC) application for identifying daily incremental changes on legacy/mainframe systems. The main objective of this implementation is to provide a real-time data replication solution to make IMS data on z/OS available to modernized applications running on web or mobile-based platforms. Currently, COBOL programs on z/OS are used to extract IMS data and transferred it to databases running on remote servers.
CDC tool does capture database changes to the z/OS IMS database segments, and that data can be published and landed on target database tables. The CDC data is very application-centric and low-level. The implementation created a foundation to migrate from batch data processing to near real-time data pipelines (PostgreSQL) and/or APIs, which is one of the key characteristics of modern data architecture.
Solution Overview
A solution has been proposed to get the near real-time data from Mainframe z/OS using IMS relational database. Configuration needs to be completed via Classic Data Architect (CDA) and Management Console for the initial data load from source systems to target systems using the “refresh” method with the CDC tool. Then capture the data for the changes on the source systems by using “continuous mirroring” and publish the data to downstream consumers on a continuous basis.
The following diagram gives a solution overview of a real-world implementation of Change Data Capture from z/OS to PostgreSQL Database. The same design approach can be used for any other database application; however, the drivers may need to be installed as per target and source systems. Below are the solution components.
- IBM Infosphere Classic CDC for IMS
- IBM Infosphere CDC for FlexRep
- IBM Infosphere Classic Data Architect
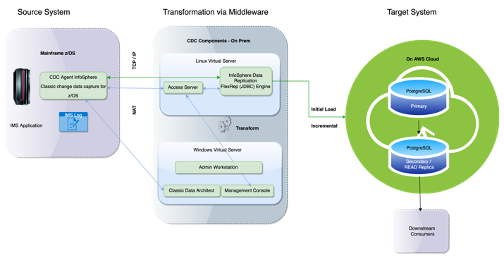
Source System
Source Operational System provides business data to downstream systems. The operating system has a relational database referred to as the source systems in above diagram. The application on source system is on mainframes with multi technologies like IMS, COBOL, MQ, etc., The data on the mainframe (z/OS) is predominantly on IMS parent-child relationship.
Target System
The consumers of mainframe data would be published to the PostgreSQL database, which is on the AWS cloud environment.
Initial Load
Initial data from the mainframe would be loaded using change data capture subscriptions for the respective IMS data segments to primary PostgreSQL using a method called “refresh.”
Incremental Load
Once the initial load is completed onto PostgreSQL, then the incremental changes will be captured through CDC and published to respective tables on the primary PostgreSQL database.
Detailed Design and Dataflow
The following flow diagram gives a rough view of the flow of activities that are conducted as part of the execution of the Custom CDC Application. Data related to ADDS, INSERTS, UPDATES, and DELETES have been captured, Custom CDC Application commits all changes to Change Database.
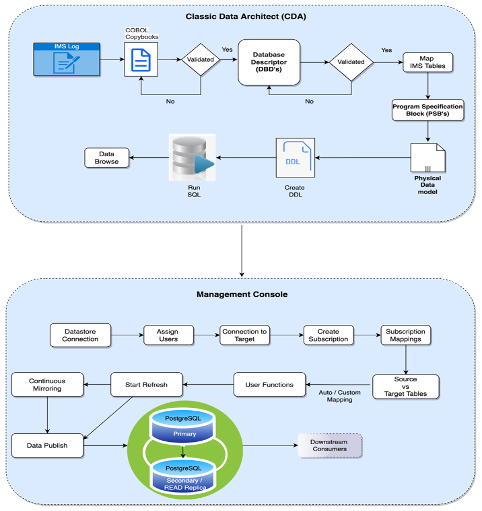
Data Flow
The above picture represents the flow of the data from source systems on z/OS Following to target system PostgreSQL on the AWS cloud environment.
CDC Techniques
There are several methods/techniques available for handling the Change Data Capture process depending on the source system’s data.
Most of the database systems have a transaction log file that records all the changes and modifications for each transaction at the source systems. The operational, transactional database will not get the effect when CDC uses a transactional log. The “refresh” method would be used to get the initial load from Mainframe IMS applications to downstream systems via built-in transformation. This process is called “initial load.” The subsequent changes for the transactions would be loaded as an incremental load to the downstream consumers. This process is called “mirroring.”
PostgreSQL
PostgreSQL Primary
Initial load and subsequent/incremental changes are loaded to PostgreSQL on AWS Cloud. PostgreSQL is the primary database to be used to send the data to various downstream consumers. This database will be appended with a new copy of the source database as soon as the change data capture application completes its processing on mainframe/mid-range systems.
PostgreSQL Secondary/Read Replica
PostgreSQL database (N+1) gets the sync copy of the source system as a read replica. This read replica database will be served as a secondary database and would be used to verify the checks and balances of the database in terms of record counts.
Subscriptions
Table mapping will be completed using subscriptions. IMS table mappings are completed using custom or ordinal positions with respective target table and column mappings. User exists are added as some of the data loaded as it is in EBCDIC (Extended Binary Coded Decimal Interchange Code) format. Data type conversion must be done before publishing the data to target PostgreSQL tables.
Monitoring and Error Handling
Monitoring Subscriptions
Subscription and data monitoring can be done through the monitoring tab in Management Console. Management Console is an administration application that allows you to configure and monitor replication. Management Console allows you to manage replication on various servers, specify replication parameters, and initiate refresh and mirroring operations from a client workstation. After defining the data that will be replicated and starting replication, you can close Management Console on the client workstation without affecting data replication activities between source and target servers.
Custom CDC Solution will abort its processing and will not commit any changes to the change database if any error is encountered either during the comparison of the latest and prior copies of the source system (operational database) or during the recording of changes in the respective change databases.
Error Handling
Subscription and event failures are notified using an event handling mechanism. Custom notifications can be set up in the event of subscription failures or data store failures. An automation email would be generated when the notifications are configured.
Conclusion
CDC can be used as a tool to reduce data processing in legacy applications and share the data changes with target systems in real-time. This can be used to create a data pipeline in streaming services.
References
IBM’s InfoSphere Data Replication is the reference for this implementation.
Acknowledgments
I would like to thank the following great reviewers who helped me in reviewing the content of the document and for their valuable suggestions:
Prajyot Dhaygude, Associate Delivery Partner, IBM Consulting
Sandeep Sahu, Technical Manager, IBM Consulting
About the Author
Hemadri Lekkala currently has worked as a Program Manager at IBM Consulting since 2004. He is an accomplished and integrity-driven technology professional offering 20 years of successful IT experience. He worked in Program and Project Portfolio Management for ten-plus years. He is experienced in lead digital integration and emerging technology practice areas and building Test CoE. He has developed and refined program management processes by working with clients' PMO offices. He has experience defining KPIs, business metrics, and SLAs and worked with IT and Business for IT road maps and product evaluation. He has managed large portfolios for American geographies for Cloud Services, Enterprise Integration Development, Resourcing, Delivery Support, and Client Relationships.
Opinions expressed by DZone contributors are their own.
Comments