AI-Driven RAG Systems: Practical Implementation With LangChain
This guide explores the fundamentals of RAG and provides a step-by-step LangChain implementation for building scalable, context-aware AI systems.
Join the DZone community and get the full member experience.
Join For FreeRetrieval-augmented generation (RAG) is revolutionizing artificial intelligence by combining powerful generative AI models with sophisticated information retrieval systems. This comprehensive guide explores foundational concepts essential for understanding RAG, including information retrieval, generative AI models, embeddings, and vector databases, followed by a detailed, practical step-by-step implementation using LangChain.
Understanding these fundamentals and their practical application through LangChain allows developers and businesses to deploy effective, scalable, and context-aware AI solutions.
Fundamentals of RAG
Information Retrieval (IR)
Information retrieval is integral to RAG, enabling systems to search, extract, and deliver relevant information from extensive data repositories. Effective IR involves indexing, querying, and ranking documents.
Components
- Indexing: Creating indices for efficient data access.
- Query processing: Interpreting queries accurately.
- Ranking algorithms: Ordering results by relevance.
Generative AI Models
Generative AI models such as GPT-4, GPT-3.5, and Llama generate coherent, human-like text. They rely on extensive training and fine-tuning processes.
Key Processes
- Pre-training: Learning language patterns from vast datasets.
- Fine-tuning: Specializing the model for specific tasks.
- Generation: Producing relevant textual responses based on input.
Embeddings
Embeddings transform textual data into numerical vectors that represent semantic meaning and relationships, facilitating effective retrieval.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
texts = ['What is AI?', 'Define machine learning.', 'Explain neural networks.']
embeddings = model.encode(texts)Vector Databases
Vector databases efficiently manage embeddings, optimizing similarity searches and retrieval speeds.
Examples: Pinecone, FAISS, Weaviate.
import pinecone
pinecone.init(api_key='YOUR_API_KEY')
index = pinecone.Index('rag-index')
index.upsert([(f'id_{i}', embeddings[i]) for i in range(len(embeddings))])Integrating IR and Generative AI in RAG
RAG seamlessly combines IR and generative AI:
User Query → IR System → Relevant Context Retrieval → Generative AI Model → Generated Response
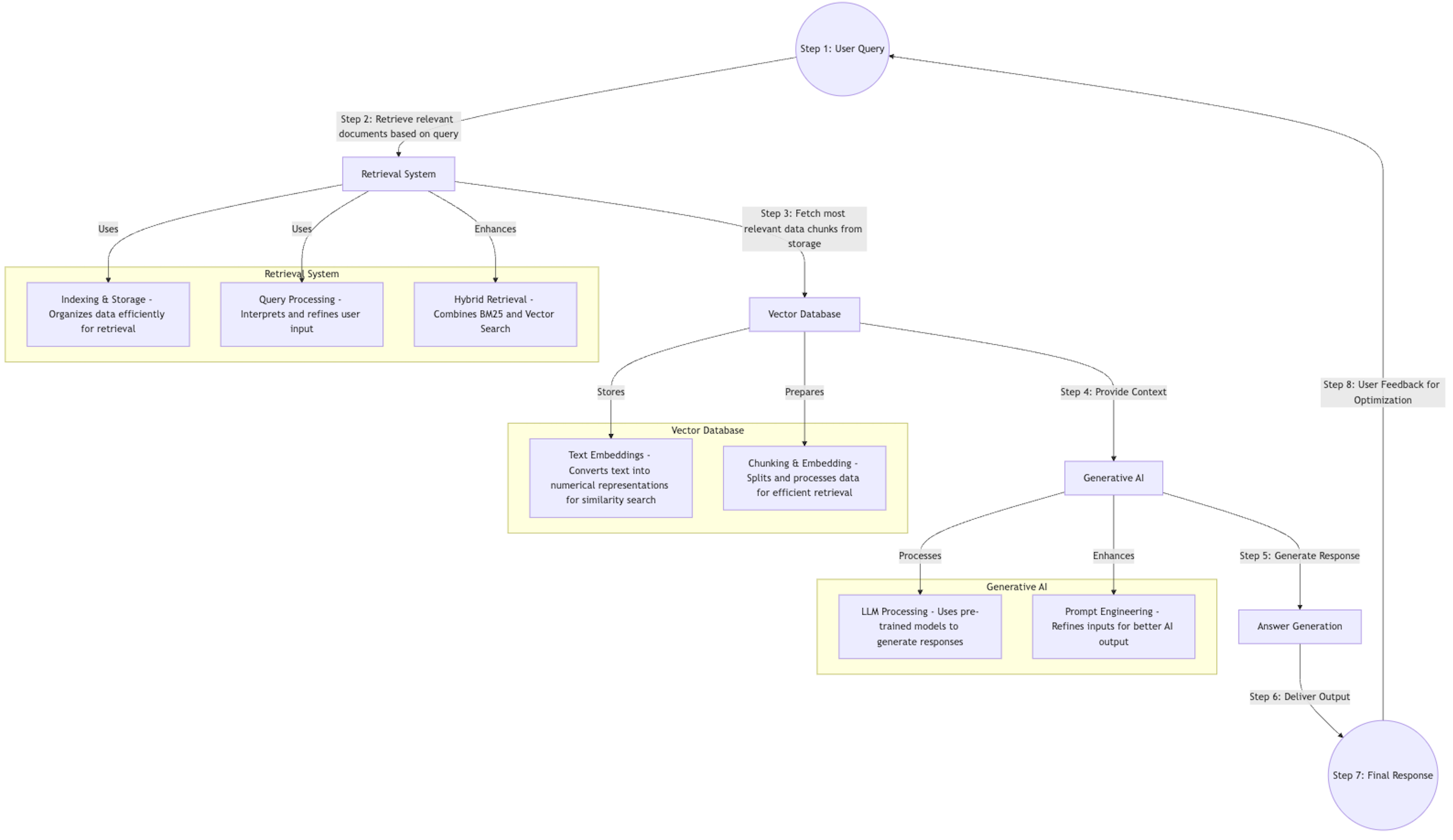
Practical RAG Implementation Using LangChain
LangChain simplifies the creation of robust RAG systems. Below is a detailed, step-by-step implementation guide.
Step 1: Data Acquisition and Preparation
Reliable data is crucial:
import pandas as pd
# Load and clean data
data = pd.read_csv('knowledge_base.csv')
data = data.dropna().reset_index(drop=True)Step 2: Data Chunking and Embedding With LangChain
Use LangChain to chunk data and generate embeddings:
from langchain.document_loaders import DataFrameLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
# Load documents
loader = DataFrameLoader(data, page_content_column='text')
documents = loader.load()
# Chunk texts
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# Create embeddings
embedding_model = HuggingFaceEmbeddings(model_name='all-MiniLM-L6-v2')Step 3: Setting Up Retrieval with Vector Store
Set up a retrieval system with LangChain and Pinecone:
from langchain.vectorstores import Pinecone
import pinecone
pinecone.init(api_key='YOUR_API_KEY')
index_name = 'rag_index'
vectorstore = Pinecone.from_documents(texts, embedding_model, index_name=index_name)Step 4: Integration With Generative AI using LangChain
Integrate retrieval with generative AI:
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
llm = OpenAI(api_key='YOUR_OPENAI_API_KEY')
rag_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 5})
)
query = "What is RAG?"
response = rag_chain.run(query)
print(response)Step 5: Continuous Optimization
Regularly refine embeddings and retrieval accuracy:
def update_embeddings(new_data):
new_loader = DataFrameLoader(new_data, page_content_column='text')
new_docs = new_loader.load()
new_texts = text_splitter.split_documents(new_docs)
vectorstore.add_documents(new_texts)Advanced Implementation Techniques
Hybrid Retrieval
Combine semantic and keyword-based retrieval methods:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25_retriever = BM25Retriever.from_documents(texts)
bm25_retriever.k = 10
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5]
)
rag_chain = RetrievalQA.from_chain_type(llm, retriever=ensemble_retriever)Prompt Engineering
Refine prompts to enhance generative model performance:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
template="""
Context:
{context}
Question: {question}
Answer:
""",
input_variables=["context", "question"]
)
rag_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type="stuff",
chain_type_kwargs={"prompt": prompt}
)
Applications and Use Cases
- Customer support: Improved chatbot accuracy.
- Healthcare: Reliable medical assistance.
- Legal advisory: Efficient legal research.
- Education: Enhanced personalized learning.
Challenges and Solutions
- Slow retrieval: Optimize indexing and use hybrid retrieval.
- Irrelevant context: Improve chunking and embedding.
- Hallucinations: Enhance context validation and prompt clarity.
Conclusion
Mastering AI-driven RAG systems with LangChain involves deeply understanding foundational concepts and leveraging powerful implementation techniques. With robust knowledge of IR, generative AI models, embeddings, and vector databases, organizations can effectively build context-aware, scalable, and reliable AI solutions.
Opinions expressed by DZone contributors are their own.
Comments