Unlocking the Potential of Apache Iceberg: A Comprehensive Analysis
Organization adoption perspective and key considerations of Apache Iceberg, a high-performance open-source format for large analytic tables.
Join the DZone community and get the full member experience.
Join For FreeApache Iceberg has emerged as a pioneering open table format, revolutionising data management by addressing big challenges. In this article, we'll delve into Iceberg's capabilities, discuss its limitations, and explore the implications for data architects.
A Brief History Lesson: Hadoop's Legacy
Hadoop, once hailed as a groundbreaking solution, ultimately failed to live up to its expectations due to its inherent complexity. Many organizations struggled to navigate distributed clusters, fine-tune configurations, and mitigate issues like data fragmentation. Iceberg aims to learn from Hadoop's mistakes and provide a more streamlined and efficient solution.
Iceberg's Key Features: A Modern Paradigm
Iceberg introduces several innovative features that address Hadoop's shortcomings:
Dynamic Schema Adaptation
Iceberg's flexible schema enables seamless adaptations to changing data structures without requiring costly rewrites.
Temporal Data Management
Query data as it existed at a specific point in time, enabling efficient auditing, versioning, and compliance.
Atomic Transactions
Ensure data consistency and reliability with atomic, consistent, isolated, and durable transactions, guaranteeing data integrity.
Adaptive Partitioning
Modify data partitioning without disrupting existing queries, reducing maintenance overhead, and enhancing agility.
The Ecosystem: Beyond the Table Format
While Iceberg itself is a significant improvement, its success relies on a robust and integrated ecosystem. This includes:
1. Optimized Compute Engines
Selecting the right query engine is crucial for optimizing performance, cost, and scalability. Popular options like Trino, Spark, and Snowflake offer varying levels of support for Iceberg.
2. Automated Maintenance
Automating tasks like data compaction, metadata cleanup, and data ingestion is essential for minimizing operational overhead and ensuring data quality.
3. Unified Catalog Management
Effective management of metadata is crucial for Iceberg's performance. However, the current catalog landscape is fragmented, with various providers offering different solutions.
4. Seamless Integration
Ensuring seamless integration with existing tools, systems, and workflows is critical for widespread adoption and minimizing disruption.
5. Robust Security and Governance
Implementing robust security measures and data governance policies is essential for protecting sensitive data in Iceberg-based systems and ensuring compliance.
Key Considerations for Iceberg Adoption
When evaluating Iceberg for your organization, consider the following key factors:
1. Clear Use Case Definition
Clearly articulate your specific needs, priorities, and pain points. Are you focused on performance, cost, or both? What are your data governance and security requirements?
2. Compatibility Assessment
Ensure your existing infrastructure, tools, and workflows are compatible with Iceberg and your chosen catalog.
3. Cloud Vendor Lock-in Mitigation
Be mindful of potential lock-in, especially with catalogs. While Iceberg is an open format, cloud providers' implementations may introduce vendor lock-in.
4. Build vs. Buy Decision
Decide whether you have the resources to build and maintain your Iceberg infrastructure or if a managed service is better.
5. Talent and Expertise Evaluation
Do you have the in-house expertise to manage Spark clusters (for compaction), configure query engines, and manage metadata? If not, consider partnering with consultants or investing in training.
6. Data Governance Framework Establishment
Don't wait until the last minute to build the data governance framework. Create the framework and processes before jumping into adoption.
Cloud Vendor Lock-In Mitigation
Understanding the Risks and Strategies for Overcoming Them
Cloud vendor lock-in refers to the dependence on a specific cloud provider's services, making it difficult to switch to another provider without significant costs, time, and effort. When adopting Apache Iceberg, organizations must be aware of the potential risks of cloud vendor lock-in and develop strategies to mitigate them.
Risks of Cloud Vendor Lock-In
Limited Flexibility
Cloud vendor lock-in restricts an organization's ability to choose the best services for their needs, forcing them to adapt to the provider's offerings.
Increased Costs
Switching cloud providers can result in significant costs, including data migration, re-architecting applications, and re-training personnel.
Data Portability Issues
Cloud providers often use proprietary formats, making it challenging to move data between providers.
Dependence on Proprietary Services
Organizations may become reliant on proprietary services, such as cloud-specific machine learning algorithms or data processing tools.
Strategies for Overcoming Cloud Vendor Lock-In
Choose Open-Source Solutions
Opt for open-source technologies like Apache Iceberg, which provide flexibility and avoid vendor lock-in.
Use Cloud-Agnostic Services
Select services that are cloud-agnostic, allowing for easier migration between providers.
Implement Data Portability
Ensure data is stored in open, portable formats, making it easier to move between providers.
Develop a Multi-Cloud Strategy
Adopt a multi-cloud approach, using services from multiple providers to avoid dependence on a single vendor.
Monitor and Adjust
Continuously monitor your cloud usage and adjust your strategy as needed to avoid lock-in.
Negotiate With Cloud Providers
When signing contracts with cloud providers, negotiate terms that allow for flexibility and avoid lock-in.
Invest in Cloud-Agnostic Skills
Develop skills in cloud-agnostic technologies and methodologies to ensure your team can adapt to changing cloud landscapes.
Architecture for Multi-Cloud Strategy
Here is a text-based representation of a possible architecture for Apache Iceberg in a multi-cloud strategy:
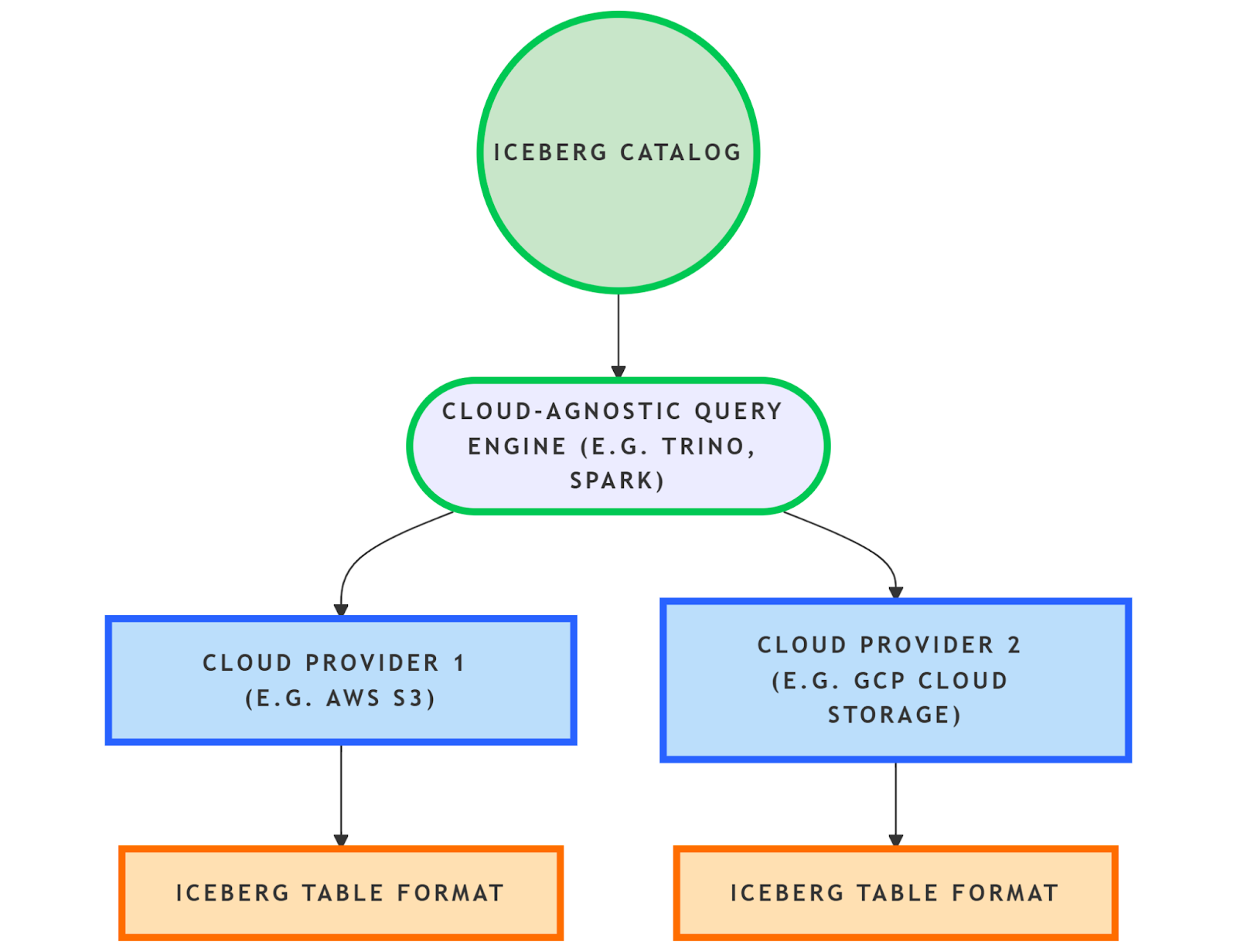
This architecture shows:
- A centralized Iceberg catalog that manages metadata across multiple clouds.
- A cloud-agnostic query engine (e.g., Trino, Spark) that can query data across multiple clouds.
- Multiple cloud providers (e.g., AWS S3, GCP Cloud Storage) that store data in the Iceberg table format.
Best Suitable Use Cases for Apache Iceberg
Apache Iceberg is particularly well-suited for the following use cases:
Data Warehousing
Iceberg's support for ACID transactions, schema evolution, and time travel makes it an ideal choice for data warehousing workloads.
Real-Time Analytics
Iceberg's ability to handle high-volume, high-velocity data streams makes it well-suited for real-time analytics applications.
Machine Learning
Iceberg's support for data versioning and auditing makes it an attractive choice for machine learning workloads that require data reproducibility.
Data Integration
Iceberg's ability to handle diverse data sources and formats makes it an ideal choice for data integration workloads.
Cloud Data Lakes
Iceberg's support for cloud-agnostic data storage and management makes it an attractive choice for cloud data lakes.
Conclusion
Apache Iceberg is a powerful tool for data management, offering a range of features and benefits that make it an attractive choice for organizations looking to improve their data management capabilities. By understanding the key considerations for Iceberg adoption, organizations can unlock the full potential of this technology and achieve their data management goals.
Some popular problems that Apache Iceberg can help solve include:
- Slow query performance
- Data inconsistencies
- Data silos
- Data governance
- Cloud vendor lock-in
By addressing these issues, Apache Iceberg can help organizations achieve faster query performance, improved data quality, and enhanced data governance, ultimately leading to better decision-making and business outcomes.
Opinions expressed by DZone contributors are their own.
Comments