Hadoop Ecosystem: Hadoop Tools for Crunching Big Data
Join the DZone community and get the full member experience.
Join For Free
Hadoop Ecosystem
In this blog, let's understand the Hadoop Ecosystem. It is an essential topic to understand before you start working with Hadoop. This Hadoop ecosystem blog will familiarize you with industry-wide used Big Data frameworks, required for a Hadoop certification.
The Hadoop Ecosystem is neither a programming language nor a service; it is a platform or framework which solves big data problems. You can consider it as a suite that encompasses a number of services (ingesting, storing, analyzing, and maintaining) inside it. Let us discuss and get a brief idea about how the services work individually and in collaboration.
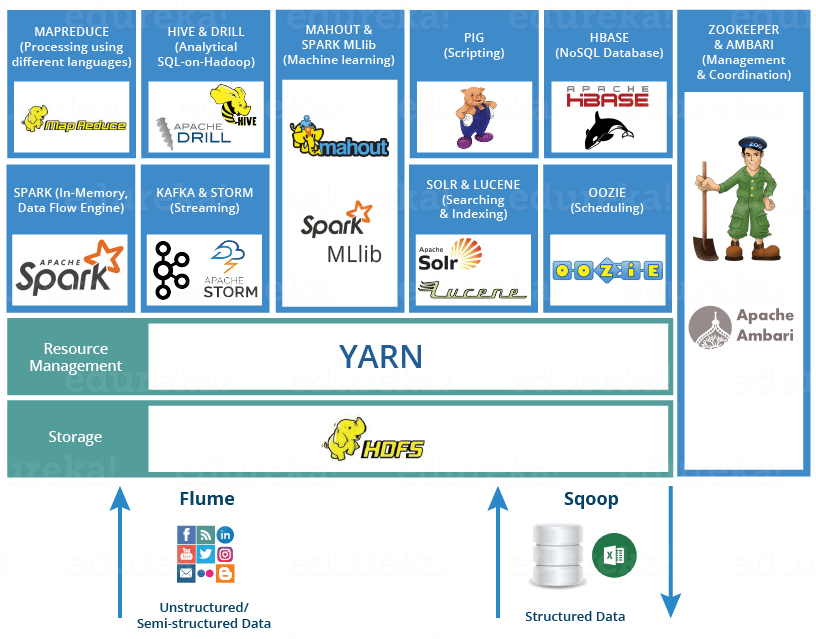
Below are the Hadoop components that, together, form the Hadoop ecosystem. I will be covering each of them in this blog:
- HDFS — Hadoop Distributed File System.
- YARN — Yet Another Resource Negotiator.
- MapReduce — Data processing using programming.
- Spark — In-memory Data Processing.
- PIG, HIVE — Data Processing Services using Query (SQL-like).
- HBase — NoSQL Database.
- Mahout, Spark MLlib — Machine Learning.
- Apache Drill — SQL on Hadoop.
- Zookeeper — Managing Cluster.
- Oozie — Job Scheduling.
- Flume, Sqoop — Data Ingesting Services.
- Solr and Lucene — Searching & Indexing.
- Ambari — Provision, Monitor and Maintain cluster.
You may also like: The Complete Apache Spark Collection [Tutorials and Articles].
Hadoop Distributed File System
- The Hadoop Distributed File System is the core component, or, the backbone of the Hadoop Ecosystem.
- HDFS makes it possible to store different types of large data sets (i.e. structured, unstructured, and semi-structured data).
- HDFS creates a level of abstraction over resources, where we can see the whole HDFS as a single unit.
- It helps us in storing our data across various nodes and maintaining the log file about the stored data (metadata).
- HDFS has two core components (
NameNodeandDataNode).- The
NameNodeis the main node, and it doesn’t store the actual data. It contains metadata, just like a log file or you can say as a table of content. Therefore, it requires less storage and high computational resources. - On the other hand, all your data is stored on the
DataNodesand hence it requires more storage resources. These DataNodes are commodity hardware (like your laptops and desktops) in the distributed environment. That’s the reason why Hadoop solutions are very cost-effective. - You always communicate to the
NameNodewhile writing the data. Then, it internally sends a request to the client to store and replicate data on variousDataNodes.
- The

YARN
Consider YARN as the brain of your Hadoop Ecosystem. It performs all your processing activities by allocating resources and scheduling tasks.
- It has two major components (
ResourceManagerandNodeManager).-
ResourceManageris again a main node in the processing department. - It receives processing requests and then passes the parts of requests to the corresponding
NodeManagers, where the actual processing takes place. -
NodeManagersare installed on everyDataNode. It is responsible for the execution of tasks on every single DataNode.
-
- Schedulers:Based on your application resource requirements, Schedulers perform scheduling algorithms and allocate the resources.
- ApplicationsManager:While
ApplicationsManageraccepts the job submission, it negotiates to containers (i.e. the Data node environment where process executes) for executing the application specificApplicationMasterand monitoring the progress.ApplicationMastersare the daemons that reside on aDataNodeand communicates to containers for the execution of tasks on eachDataNode.ResourceManagerhas two components (SchedulersandApplicationsManager).
MapReduce
It is the core component of processing in a Hadoop Ecosystem, as it provides the logic of processing. In other words, MapReduce is a software framework that helps in writing applications that process large data sets using distributed and parallel algorithms inside the Hadoop environment.
- In a MapReduce program,
Map()andReduce()are two functions.- The
Mapfunction performs actions like filtering, grouping, and sorting. - The
Reducefunction aggregates and summarizes the result produced by themapfunction. - The result generated by the Map function are a key-value pair (K, V), which acts as the input for the
Reducefunction.
- The
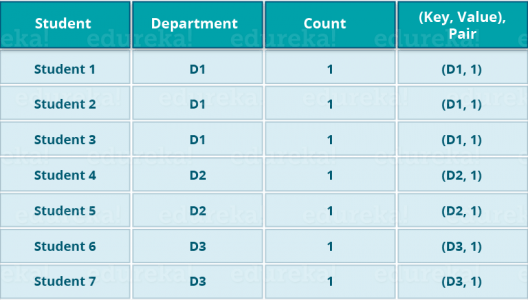
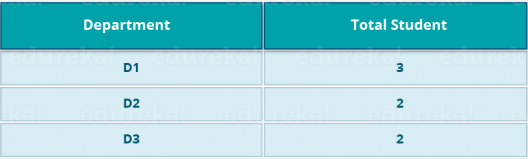
Let's take the above example to have a better understanding of a MapReduce program.
We have a sample case of students and their respective departments. We want to calculate the number of students in each department. Initially, the Map program will execute and calculate the students appearing in each department, producing the key-value pair, as mentioned above. This key-value pair is the input to the Reduce function. The Reduce function will then aggregate each department and calculate the total number of students in each department and produce the given result.
Apache Pig
PIG has two parts: Pig Latin, the language, and the pig runtime, the execution environment. You can better understand it as Java and JVM.
It supports pig latin language, which has an SQL-like command structure.
Apache PIG relieves those who do not come from a programming background. You might be curious to know how? Well, I will tell you an interesting fact: 10 lines of pig latin = approx. 200 lines of Map-Reduce Java code
But, don’t be shocked when I say that at the back end of Pig job, a map-reduce job executes.
- The compiler internally converts pig latin to MapReduce. It produces a sequential set of MapReduce jobs.
- PIG was initially developed by Yahoo.
- It gives you a platform for building a data flow for ETL (Extract, Transform, and Load), processing, and analyzing huge data sets.
How Does Pig Work?
In PIG, first, the load command loads the data. Then, we perform various functions on it like grouping, filtering, joining, sorting, etc. At last, either you can dump the data on the screen, or you can store the result back in HDFS.
Apache Hive
Facebook created HIVE for people who are fluent with SQL. Thus, HIVE makes them feel at home while working in a Hadoop Ecosystem.
Basically, HIVE is a data warehousing component that performs reading, writing, and managing large data sets in a distributed environment using a SQL-like interface.
HIVE + SQL = HQL
- The query language of Hive is called Hive Query Language (HQL).
- It has two basic components: Hive Command-Line and JDBC/ODBC driver.
- The Hive Command-line interface is used to execute HQL commands.
- Java Database Connectivity (JDBC) and Object Database Connectivity (ODBC) are used to establish a connection from data storage.
- Hive is highly scalable. It can perform operations for large data set processing (i.e. batch query processing) and real-time processing (i.e. interactive query processing).
- It supports all primitive data types of SQL.
- You can use predefined functions or write tailored user-defined functions (UDF) to accomplish your specific needs.
Apache Mahout
![]()
Now, let us talk about Mahout, which is renowned for machine learning. Mahout provides an environment for creating machine learning applications that are scalable.
What Mahout does?
It performs collaborative filtering, clustering, and classification. Some people also consider frequent item set missing as Mahout’s function. Let us understand them individually:
- Collaborative filtering: Mahout mines user behaviors, their patterns, and their characteristics and predicts and makes recommendations to users. The typical use case is an E-commerce website.
- Clustering: It organizes similar groups of data together, like articles that can contain blogs, news, research papers, etc.
- Classification: It means classifying and categorizing data into various sub-departments (i.e. articles can be categorized into blogs, news, essay, research papers, etc.).
- Frequent item set missing: Here, Mahout checks which objects are likely to be appear together and makes suggestions if they are missing. For example, cell phones and cover are brought together in general. So, if you search for a cell phone, it will also recommend the cover and cases.
Mahout provides a command line to invoke various algorithms. It has a predefined set of the library that already contains different inbuilt algorithms for different use cases.
Apache Spark
Apache Spark is a framework for real-time data analytics in a distributed computing environment. Spark is written in Scala and was originally developed at the University of California, Berkeley. It executes in-memory computations to increase the speed of data processing over Map-Reduce.
It is 100x faster than Hadoop for large scale data processing by exploiting in-memory computations and other optimizations. Therefore, it requires higher processing power than Map-Reduce.

As you can see, Spark comes packed with high-level libraries, including support for R, SQL, Python, Scala, Java, etc. These standard libraries increase the seamless integrations in the complex workflow. Over this, it also allows various sets of services to integrate with it like MLlib, GraphX, SQL + Data Frames, Streaming services, etc. to increase its capabilities.
This is a very common question in everyone’s mind:
“Apache Spark: A Killer or Saviour of Apache Hadoop?” – O’Reily
The Answer to this – This is not an apple to apple comparison. Apache Spark best fits real-time processing, whereas Hadoop was designed to store unstructured data and execute batch processing over it. When we combine, Apache Spark’s ability, i.e. high processing speed, advanced analytics, and multiple integration support with Hadoop’s low-cost operation on commodity hardware, it gives the best results.
That is the reason why Spark and Hadoop are used together by many companies for processing and analyzing their Data stored in HDFS.
Apache HBase
![]()
HBase is an open source, non-relational, distributed database. In other words, it is a NoSQL database. It supports all types of data and that is why it’s capable of handling anything and everything inside a Hadoop ecosystem.
It is modeled after Google’s BigTable, which is a distributed storage system designed to cope up with large data sets. HBase was designed to run on top of HDFS and provides BigTable-like capabilities.
It gives us a fault-tolerant way of storing sparse data, which is common in most big data use cases. HBase is written in Java, whereas HBase applications can be written in REST, Avro, and Thrift APIs.
For better understanding, let us take an example. You have billions of customer emails, and you need to find out the number of customers who have used the word "complaint" in their emails. The request needs to be processed quickly (i.e. at real-time). So, here, we are handling a large data set while retrieving a small amount of data. HBase was designed for solving this kind of problem.
Apache Drill
![]()
As the name suggests, Apache Drill is used to drill into any kind of data. It’s an open source application that works with a distributed environment to analyze large data sets.
- It is a replica of Google Dremel.
- It supports different kinds of NoSQL databases and file systems, including Azure Blob Storage, Google Cloud Storage, HBase, MongoDB, MapR-DB HDFS, MapR-FS, Amazon S3, Swift, NAS, and local files.
Essentially, the main aim behind Apache Drill is to provide scalability so that we can process petabytes and exabytes of data efficiently (or you can say in minutes).
- The main power of Apache Drill lies in combining a variety of data stores just by using a single query.
- Apache Drill basically follows ANSI SQL.
- It has a powerful scalability factor in supporting millions of users and serve their query requests over large scale data.
Apache ZooKeeper
Apache ZooKeeper is the coordinator of any Hadoop job, which includes a combination of various services in a Hadoop Ecosystem. Apache ZooKeeper coordinates with various services in a distributed environment.
Before Zookeeper, it was very difficult and time-consuming to coordinate between different services in the Hadoop Ecosystem. The services earlier had many problems with interactions like common configuration while synchronizing data. Even if the services are configured, changes in the configurations of the services make it complex and difficult to handle. Grouping and naming was also a time-consuming factor.
Due to the above problems, ZooKeeper was introduced. It saves a lot of time by performing synchronization, configuration maintenance, grouping, and naming. Although it’s a simple service, it can be used to build powerful solutions.
Big names like Rackspace, Yahoo, and eBay use this service throughout their data workflow, so you have an idea about the importance of ZooKeeper.
![]()
Apache Oozie
Consider Apache Oozie as a clock and alarm service inside the Hadoop Ecosystem. For Apache jobs, Oozie has been just like a scheduler. It schedules Hadoop jobs and binds them together as one logical work.
There are two kinds of Oozie jobs:
- Oozie workflow: These are sequential sets of actions to be executed. You can think of it as a relay race, where each athlete waits for the last one to complete their part.
- Oozie Coordinator: These are the Oozie jobs that are triggered when data is made available to it. Think of this as the response-stimuli system in our body. Just as we respond to an external stimulus, an Oozie coordinator responds to the availability of data and it rests otherwise.

Apache Flume
Ingesting data is an important part of our Hadoop Ecosystem.
- Flume is a service that helps in ingesting unstructured and semi-structured data into HDFS.
- It gives us a solution that is reliable and distributed and helps us in collecting, aggregating, and moving a large number of data sets.
- It helps to ingest online streaming data from various sources, such as network traffic, social media, email messages, log files, etc. in the HDFS.
Now, let us understand the architecture of Flume from the below diagram:
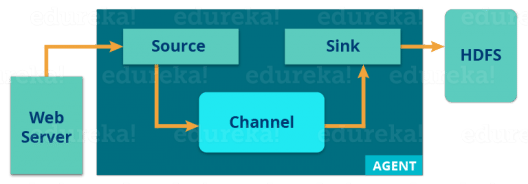
A Flume agent ingests streaming data from various data sources to HDFS. From the diagram, you can easily understand that the web server indicates the data source. Twitter is among one of the famous sources for streaming data.
The flume agent has three components: source, sink, and channel.
- Source: Accepts data from an incoming streamline and stores that data in the channel.
- Channel: Acts as the local storage or the primary storage. A Channel is temporary storage between the source of data and persistent data in the HDFS.
- Sink: Collects the data from the channel and commits or writes the data in the HDFS permanently.
Apache Sqoop
Now, let us talk about another data ingesting service i.e. Sqoop. The major difference between Flume and Sqoop is that:
- Flume only ingests unstructured data or semi-structured data into HDFS.
- While Sqoop can import as well as export structured data from an RDBMS or Enterprise data warehouses to HDFS or vice versa.
Let us understand how Sqoop works using the below diagram:
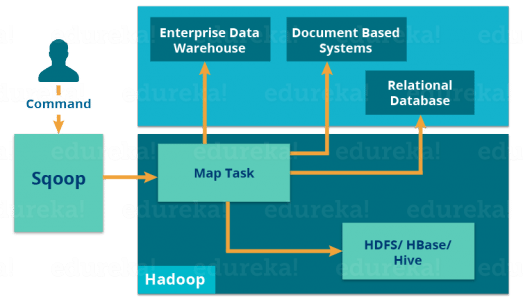
When we submit a Sqoop command, our main task gets divided into sub-tasks, which are then handled by an individual Map Task internally. Map Task is the sub-task, which imports part of the data to the Hadoop Ecosystem.
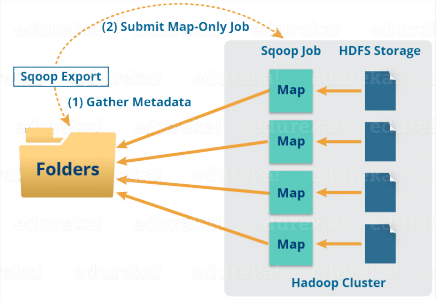
When we submit our Job, it is mapped into Map Tasks, which brings a chunk of data from HDFS. These chunks are exported to a structured data destination. Combining all these exported chunks of data, we receive the whole data at the destination, which in most cases is an RDBMS (MYSQL/Oracle/SQL Server).
Apache Solr and Lucerne
Apache Solr and Apache Lucene are used for searching and indexing in the Hadoop Ecosystem.
- Apache Lucene is based on Java, which also helps in spell checking.
- If Apache Lucene is the engine, Apache Solr is the car built around it. It uses the Lucene Java search library as a core for search and full indexing.
Apache Ambari
![]()
Ambari is an Apache Software Foundation Project, which aims at making the Hadoop ecosystem more manageable.
It includes software for provisioning, managing, and monitoring Apache Hadoop clusters.
The Ambari provides:
- Hadoop cluster provisioning:
- It gives us a step-by-step process for installing Hadoop services across a number of hosts.
- It also handles the configuration of Hadoop services over a cluster.
- Hadoop cluster management:
- It provides a central management service for starting, stopping, and reconfiguring Hadoop services across a cluster.
- Hadoop cluster monitoring:
- For monitoring health and status, Ambari provides a dashboard.
- The Amber Alert framework is an alerting service that notifies the user whenever attention is needed(e.g., if a node goes down or low disk space on a node, etc.).
At last, I would like to draw your attention to three important notes:
- The Hadoop Ecosystem owes its success to the whole developer community. Many large organizations, like Facebook, Google, Yahoo, University of California (Berkeley), etc. have contributed to increase Hadoop’s capabilities.
- Inside a Hadoop Ecosystem, knowledge about one or two tools (Hadoop components) would not help in building a solution. You need to learn a set of Hadoop components, which work together to build a solution.
- Based on the use cases, we can choose a set of services from the Hadoop Ecosystem and create a tailored solution for an organization.
I hope this blog is informative and added value to you.
Further Reading
Opinions expressed by DZone contributors are their own.
Comments