Bridging the Gap Between Data Lakes and Warehouses
Data lakehouses combine the flexibility of data lakes with the reliability, performance, and governance features of data warehouses.
Join the DZone community and get the full member experience.
Join For FreeIn the current analytics landscape, companies rely heavily on data lakes and data warehouses as their primary sources for data storage and analysis. On the one hand, data lakes allow easy storage of a variety of raw and non-processed data, and on the other hand, data warehouses support formatting, storage, and processing of data in a manner that suits reporting and analytics.
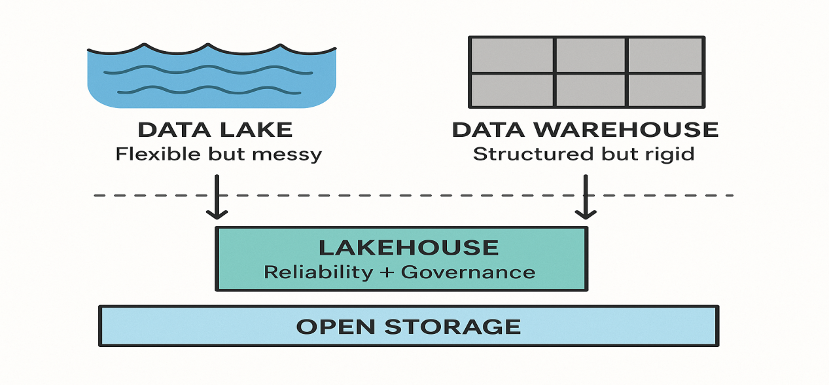
Figure 1: Evolution from data lakes and warehouses to the lakehouse model
Still, the management of these systems is fraught with significant problems. Organizations generally encounter issues such as data scattering, overlapping ETL (extract, transform, load) processes, and varying data quality and formats across platforms. All these difficulties can lead to slower analytics, higher costs, and more complex governance.
The lakehouse architecture has emerged as a solution to these problems. By combining the adaptability of data lakes with the performance and management of data warehouses, lakehouses provide unified storage, governance, and compute. The adoption of lakehouse platforms is skyrocketing across the industry, signaling a move towards more efficient and flexible analytics environments.
We will examine how lakehouse architectures address these issues and provide a recommendation for unifying contemporary data storage and analytics.
Background: Why Traditional Approaches Fall Short
Even though data warehouses and data lakes are significant components of data analytics, their separate use does not put companies in the best position.
Data Warehouses
The conventional warehouses have a big plus in terms of structured data and analytics; nevertheless, they are incredibly costly, not being able to scale, plus having a significant downside of an inflexible schema, which makes it really hard to ingest different or rapidly changing data.
Data Lakes
Conversely, data lakes offer highly adaptable storage for unstructured and semi-structured data, but they suffer from poor governance, inconsistent performance, and data quality issues that may render the data untrustworthy for critical analytics or machine learning operations.
Operational Challenges of Coexisting Systems
The cohabitation of both lakes and warehouses in a company means higher operational costs. To move and transform data between different systems, highly complex ETL pipelines must be constructed, which eventually results in more latency and increased maintenance efforts. Furthermore, data drift and duplication are among the problems that occur, leading to inconsistencies detrimental to analytical accuracy.
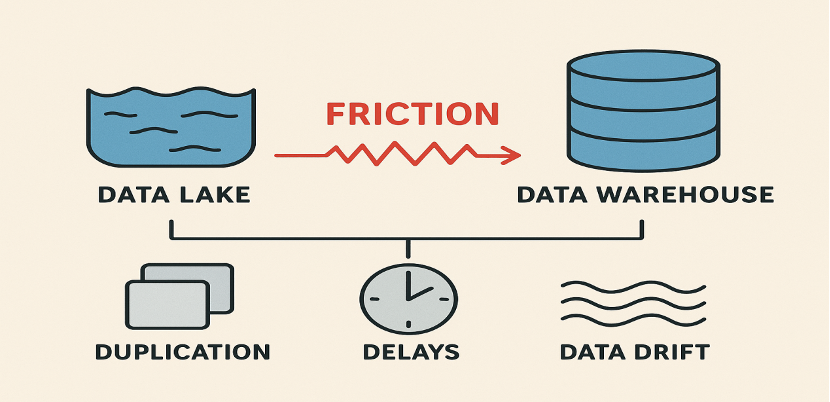
Figure 2: Fragmentation challenges when lakes and warehouses operate separately
These limitations highlight the need for a unified approach that combines the strengths of both systems while mitigating their weaknesses.
What Is a Data Lakehouse?
A data lakehouse is an innovative data architecture that integrates the attributes of data lakes and data warehouses into one platform. Its primary aim is to provide a scalable, flexible storage solution that supports structured queries, transactional reliability, and strong governance, thereby crossing the boundary between raw data storage and high-performance analytics.
The lakehouse is a combination of both systems' capabilities, thus enabling businesses to do the following:
- At the data lake scale, keep all types of data: structured, semi-structured, and unstructured.
- Data warehouse like ACID transactions, schema enforcement, and high-performance querying.
Key characteristics and design principles include:
- Openness: This is characterized by open formats (e.g., Parquet, Delta Lake, and Apache Iceberg), which enable the use of various tools and engines interchangeably.
- Reliability: ACID-compliant transactions ensure data is always consistent and reliable.
- Governance: Manual handling of compliance and auditing is made easier by integrated lineage, metadata management, and access controls.
- Performance: The large datasets are optimized not only for storage but also for compute, ensuring fast query execution and analytics.
Overall, the lakehouse paradigm promises to be a single, unified platform where all data operations are performed easily, no duplication is introduced, and analytics are performed quickly. Besides, the platform can give an organization the flexibility to manage modern data workloads.
Architectural Components of a Lakehouse
Lakehouses of today are established on merged features comprising the following components:
1. Single Unified Storage Layer
Modern-day lakehouses treat all types of data, including structured, semi-structured, and unstructured, as one and thus put it all in one object storage system (for example, S3, ADLS, GCS). This whole process has eliminated the divide between lakes and warehouses, thereby reducing data management burden by eliminating data copying and reducing the number of places to manage.
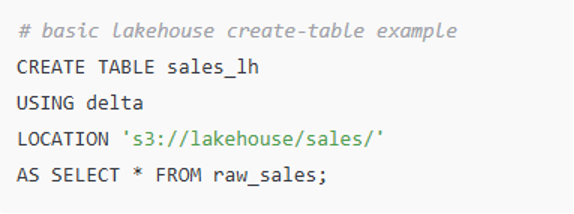
Code: Creating a simple lakehouse table using Delta Lake
2. Metadata and Table Formats
The proper management of reliable metadata plays a significant role in ensuring ACID compliance and query performance, among other things. Some of the widely used table formats are as follows:
- Delta Lake: It provides object storage support and schema enforcement by extending ACID to object storage.
- Apache Iceberg: This is a table provisioned with a multi-layered partitioning method, which leads to a faster query process. Also offers large-scale table versioning, partition evolution, and high-performance queries
- Apache Hudi: It allows you to perform upserts and work with incremental processing on both streaming and batch data. Provides upserts, incremental ingestion, and streaming support over data lakes
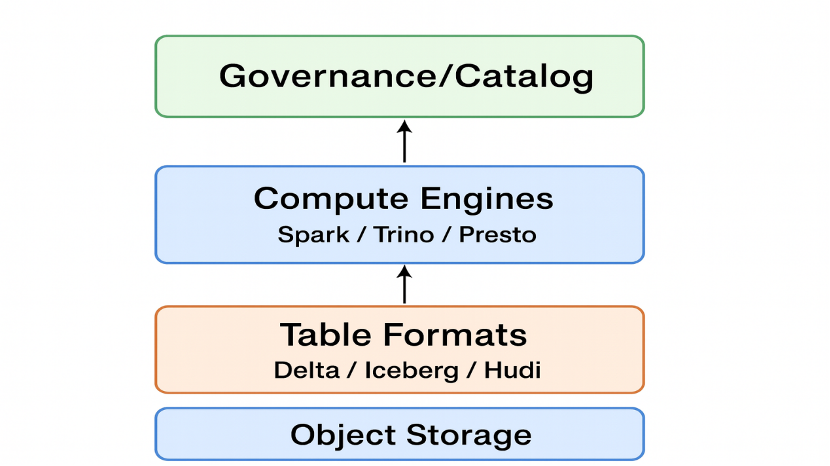
Figure 3: Core architectural layers of a modern data lakehouse
3. Compute Engines and Query Processing
Lakehouses separate storage from compute, thus allowing different engines to extract the same data efficiently:
- Spark: Distributed processing for both batch and streaming demand.
- Trino: Fast SQL queries on huge data sets.
- DuckDB: Small and efficient analytics engine for local or embedded queries.
- Photon: Enhanced and fast query engine for a large number of users and high performance.
4. Governance and Catalog Services
Integrated governance secures, regulates, and audits the data usage in a way that is very efficient and easy to monitor:
- Unity Catalog: A single point of control for metadata and access.
- AWS Glue: Data catalog for ETL orchestration and discovery, along with lineage tracking for data that can now be easily located.
5. Data Ingestion and Transformation Pipelines
Lakehouses provide the capability for batch and streaming ingestion, hence supporting reliable ETL/ELT processes. Apache Spark, Flink, or dbt are examples of frameworks that make sure data is transformed, validated, and stored as analytics-ready data without incurring any additional storage cost.
These elements together create one ecosystem with the characteristics of being flexible, reliable, and high-performing, which enables data management of large-scale organizations very efficiently while supporting various analytics workloads.
6. Platforms
A variety of platforms based on cloud and hybrid technologies are applying the lakehouse architecture:
- Databricks: It is the ultimate managed platform, featuring seamless Delta Lake integration and the support of multiple engines.
- Snowflake Unistore: Merges the transactional and analytical workloads in one engine.
- Amazon Athena/EMR: Serverless and managed analytics over S3 storage with Iceberg or Hudi integration.
- Google BigLake: Unifying storage engine bridging lakes and warehouses on GCP.
How Lakehouses Bridge the Gap
Lakehouses or hybrid systems that merge data lakes and warehouses deal with the classic complaints of separation between these systems by presenting functions that unite the best characteristics of both:
1. Open Storage with ACID Transactions
Lakehouses, unlike data lakes, support ACID transactions, which ensure data consistency and reliability for concurrent read and write operations. The transactions mentioned above enable analytics on raw storage without losing precision.
2. Schema Enforcement and Evolution
Lakehouses can address insufficient data with schema enforcement and, at the same time, support data changes through schema evolution. This feature grants access to structured analytics as well as to a wide range of ever-changing datasets.
3. Performance Optimizations
To be able to deliver a performance level that equals that of a warehouse on a large storage system, lakehouses are implementing the following techniques:
- Caching: It reduces I/O for data that is accessed very frequently.
- Indexing: It makes the process of locating the relevant data files very speedy and hence the query execution is faster.
- File compaction: This technique merges small files to improve read efficiency and thus reduce overhead.
4. Consistency and Reliability on Par With Warehouses
The mix of transaction guarantees, metadata management, and performance optimizations enables lakehouses to offer a level of data reliability and consistency that can compete with that of traditional warehouses; however, without the inflexibility and disconnected storage that is usually associated with it.
5. Interoperability With ML and AI Workloads
The lakehouses become the sole data reservoir for the machine learning and AI pipelines, thus making it possible to perform feature engineering, model training, and scoring directly.

Code: Example of an ACID MERGE operation in a lakehouse table
Through these mechanisms, lakehouses eliminate the operational friction of managing separate lakes and warehouses while delivering flexible, reliable, and high-performance analytics for modern data workloads.
Common Lakehouse Design Patterns
Modern lakehouse designs employ various architectural patterns that provide organizations with a solid data management and workload support foundation:
1. Batch and Streaming Unification
With the storing of data in one layer, lakehouses have removed the division between batch and streaming data processing. This means that data can be continuously fed into the system while simultaneously batch processing, thus the analytics are always running on data that is both up-to-date and consistent with no additional cost for storage or pipelines for duplication.
2. Medallion Architecture
Bronze/silver/gold is the most popular way of categorizing data, known to be:
- Bronze – Data is untouched and unprocessed; it is the raw data from the sources.
- Silver – Data is cleansed and standardized; now it is enriched and ready for the analytics.
- Gold – Data is perfectly curated and ready for reporting, BI, and ML usage.
The tier system not only maintains data quality and traceability but also improves performance and simplifies downstream data consumption.
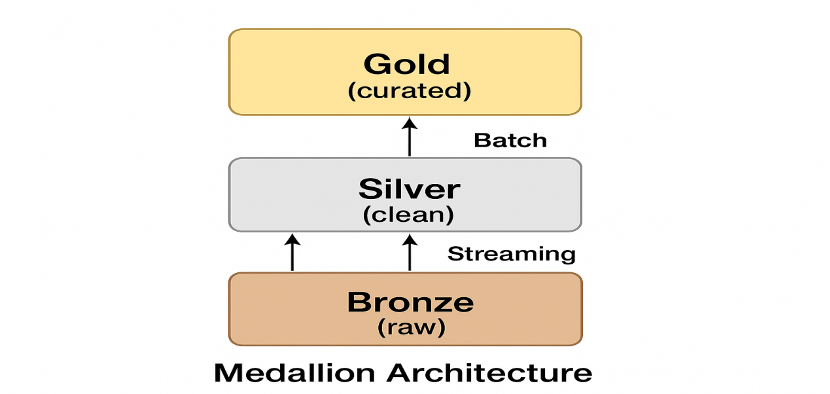 Figure 4: Medallion architecture (Bronze → Silver → Gold)
Figure 4: Medallion architecture (Bronze → Silver → Gold)
3. Multi-Engine Query Access
Lakehouse architectures allow implementing different compute engines that work with the same data; thus, engines like Spark, Trino, and DuckDB to query based on demand. This model provides flexibility, supports different types of analytics workloads, and offers the largest benefit from a single source of truth.
4. Governance Layer With Fine-Grained Access Control
The governance layer imposes strict restrictions on data access and imposes heavy controls on data usage, compliance, and auditing. Features such as role-based access control, row- and column-level permissions, lineage tracking, and centralized metadata management are integral components of the architecture.
These design patterns collectively empower organizations to build scalable, reliable, and flexible data platforms that support both operational and analytical workloads while maintaining high data quality and governance standards.

Figure 5: Technology landscape for lakehouse ecosystems
Together, these technologies form a robust ecosystem that enables organizations to build scalable, governed, and performant lakehouse platforms capable of supporting diverse analytics, reporting, and ML/AI workloads.
Implementation Considerations
A lakehouse structure can ultimately recoup the investment with performance, reliability, and scalability that align with the planners' expectations throughout the process, taking storage, schema, governance, and costs as the main dimensions along the way.
1. Storage Format Selection
Choosing the right table format (e.g., Delta Lake, Iceberg, Hudi) is still a hard decision that can be made on the following grounds:
- Any transaction must be reliable, so it must support ACID.
- The capabilities of schema evolution should align with ever-changing data structures.
- Query performance optimizations, such as partition pruning and indexing, should be implemented.
- There should be a combination of cloud object storage and cost-effective scalability.
2. Data Modeling and Schema Strategy
The performance and maintenance of a system can be made easy by a well-defined schema and modeling strategy:
- The layers of bronze/silver/gold, corresponding to skill levels, are for refining staged data.
- Parquet, a columnar storage format, is used to improve analytics processing efficiency.
- Consistent naming conventions and metadata management ensure discoverability.
3. Handling Small Files and Compaction
Small files are the main sources of both less efficient query processing and more storage.
The following best practices should be applied:
- Automatic file compaction will be applied to merge small files into a single, optimized large file.
- Partitioning strategies will be implemented to coordinate granularity with performance.
- Management of streaming ingestion will help to minimize the creation of excessively small files.
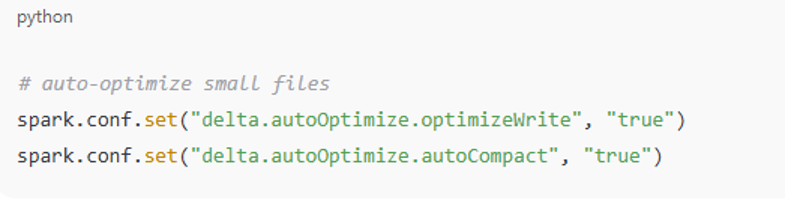 Code: Auto-optimization settings for managing small files
Code: Auto-optimization settings for managing small files
4. Governance, Lineage, and Catalog Management
Strong governance allows data to be trusted and to be in compliance with:
- Centralized catalog services (Unity Catalog, AWS Glue) for metadata management and access control.
- Lineage tracking for the auditing and facilitating of data pipelines.
- Fine-grained access control for the securing of sensitive datasets and the enforcing of policies.
5. Cost Optimization Together With Compute and Storage
The backbone of the Lakehouse concept is the decoupled infrastructure that supports a variety of scaling methods, including: the ability to dynamically scale compute clusters up and down according to the workload, the use of multiple tiers of storage to find the sweet spot between performance and cost (e.g., hot vs. cold storage), and the implementation on the computing side of query optimization methods that reduce cost, such as caching, pruning, and materialized views.
Careful attention to these considerations ensures that lakehouse implementations remain scalable, performant, and cost-efficient, supporting both analytical and operational workloads without sacrificing reliability or governance.
Use Cases
Lakehouse architectures can handle a range of modern data workloads by combining the strengths of data lakes and warehouses. Some of the main use cases are:
1. Real-Time Analytics
Lakehouses enable ingestion of streaming data and querying it almost in real time. Thus, the organizations can monitor their operations, identify problems, and ultimately take data-oriented decisions with very low latency.
2. Machine Learning and Feature Stores
The lakehouses act as one reliable data source, and it is the main reason why ML pipelines become easier to handle. One can create feature stores on the lakehouse, and through that, consistent feature engineering, model training, and scoring may take place even at a large scale.
3. BI Workloads With High Concurrency
Lakehouses offer very good performance for analytics and reporting; thus, multiple users and tools can query very large datasets simultaneously without performance or accuracy being affected.
4. Enterprise Data Governance and Compliance
The data that is being used is made sure that it complies with the requirements posed by the regulators, internal policies, and auditing standards, through integrated governance, lineage tracking, and fine-grained access control, and at the same time enables collaboration across teams to be carried out securely.
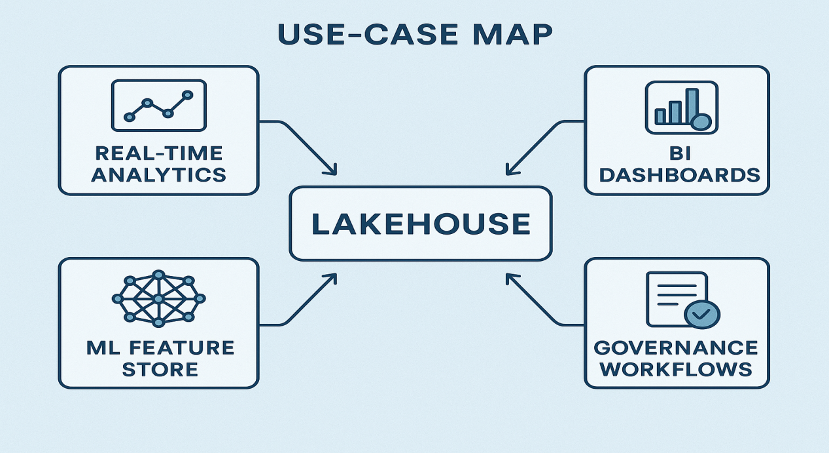
Figure 6: Key analytics and ML use cases enabled by lakehouse architectures
These use cases illustrate how lakehouses provide a versatile, unified platform capable of supporting both operational and analytical workloads, while reducing complexity and maintaining high data quality.
Conclusion
Lakehouse architectures are considered a major advancement in contemporary data management, combining the flexibility of data lakes with the reliability and performance of data warehouses. The elimination of operational friction, reduction of duplication, and simplification of complex ETL pipelines are the outcomes of the integration of storage, compute, and governance into one platform.
The adoption of a lakehouse brings along the long-term benefits of data reliability, high performance for analytics and ML workload, and operational cost savings that allow the teams to work on bringing insights out rather than managing infrastructure.
The adoption of modern lakehouse patterns would give organizations the confidence to scale their data initiatives, and at the same time, the governance would be robust, the cost would not be high, and the organization would be able to support real-time analytics, machine learning, and enterprise reporting.
Opinions expressed by DZone contributors are their own.
Comments