Data Lake, Warehouse, or Lakehouse? Rethinking the Future of Data Architecture
AI is driving data lakes, warehouses, and lakehouses to converge into open, real-time platforms powered by Iceberg, Trino, and DuckDB.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2025 Trend Report, Data Engineering: Scaling Intelligence With the Modern Data Stack.
In the age of AI and ubiquitous data, the lines between traditional data architectures are blurring. Data lakes, warehouses, and lakehouses are no longer isolated strategies but are increasingly converging into unified, intelligent platforms. This article explores how modern data architectures are evolving to meet new demands for real-time insights, agility, and a single source of truth.
Over the past five years, the shift from application-centric to data-centric thinking has transformed the technology landscape. Whether in SaaS, enterprises, or small businesses, data has become the central conversation among tech leaders. The longstanding divide between operational systems and analytical platforms is rapidly becoming obsolete.
While traditional architectures still have their place, the continued advancements in AI are accelerating the need for solutions that unify data access and interpretation. In today's world, any modern system must be a data-first system. Some industry voices even suggest that large language models (LLMs) could eventually replace many SaaS solutions. While that may be a stretch, it's clear that the next generation of technology must deeply integrate with — and be powered by — data.
Data Architectures Explained: Lake, Warehouse, and Lakehouse
Modern data architectures vary in purpose, flexibility, and technical depth. Understanding the differences between data warehouses, data lakes, and data lakehouses is key to choosing the right foundation for scalable and intelligent systems.
- Data warehouses are structured, reliable systems designed for analytics at scale. They provide strong performance and mature tooling and work best with structured data.
- Data lakes offer flexible, low-cost storage for raw data of all types. They are ideal for machine learning (ML), batch processing, and experimentation, but they often require significant engineering effort to become performant.
- Data lakehouses aim to unify the strengths of both, combining the cost efficiency of lakes with the performance and governance of warehouses. They represent the evolution toward a single, unified data platform.
Here's a quick comparison of the three:
| Aspect | Data warehouse | Data lake | Data Lakehouse |
|---|---|---|---|
|
Data types |
Structured data |
Structured, semi-structured, unstructured |
Structured, semi-structured, unstructured |
|
Storage |
Usually proprietary or abstracted |
Object storage (e.g., S3, ADLS) |
Object storage with table formats |
|
Engines |
Usually proprietary (e.g., Snowflake, BigQuery, Redshift, ClickHouse) |
||
|
Out-of-the-box features |
Clustering, caching, materialized views, time travel |
Depends on engine and format |
Depends on engine and format; some offer ACID, time travel, schema evolution, and caching |
|
Customization effort |
Low – managed experience |
High – requires significant engineering effort |
Medium – balance between control and out-of-the-box functionality |
|
Real-time and query latency |
Strong – built for fast, low-latency queries |
Weak – not suitable for interactive or real-time needs |
Improving but still a challenge depending on engine and freshness requirements |
|
Governance and ACID |
Strong |
Weak |
|
|
BI integration |
High |
Low |
Improving rapidly; depends on engine/tooling |
|
Best use cases |
Teams needing fast insights with minimal effort, in real time, and with low latency |
Data scientists and engineers working with diverse raw data |
Organizations looking for a single platform to serve multiple analytical needs |
Table 1. Data architecture overview
Modern Needs: Real-Time, AI-Driven, and Open Formats
To meet the needs of evolving data architecture, modern systems are moving toward a shared foundation: a single, synchronized layer of truth built on cloud object storage. Ingestion, both batch and real-time, is no longer a technical challenge. The next frontier lies in how we expose this data through flexible, efficient, and composable compute layers. That's where the real differentiation happens.
A powerful shift is underway: Instead of relying on centralized, monolithic data warehouses, modern architectures are embracing a multi-engine, multi-modal design, where each query engine plays a specific role — from heavy lifting in the cloud to lightweight analytics in the browser. Cloud object storage, combined with open table formats like Apache Iceberg, serves as the foundation that unifies these engines, offering transactional consistency, schema evolution, and performance optimizations.
In this section, we'll explore:
- How open table formats enable this unified foundation by decoupling data storage from compute logic
- How the emergence of distributed and embedded query engines (e.g., Trino, ClickHouse, DuckDB) is redefining where and how analytics happens — bringing data closer to the user than ever before
This model not only supports modern needs like AI and low-latency analytics but also encourages a new mindset: one where compute is no longer centralized but is composable, contextual, and optimized for the workload.
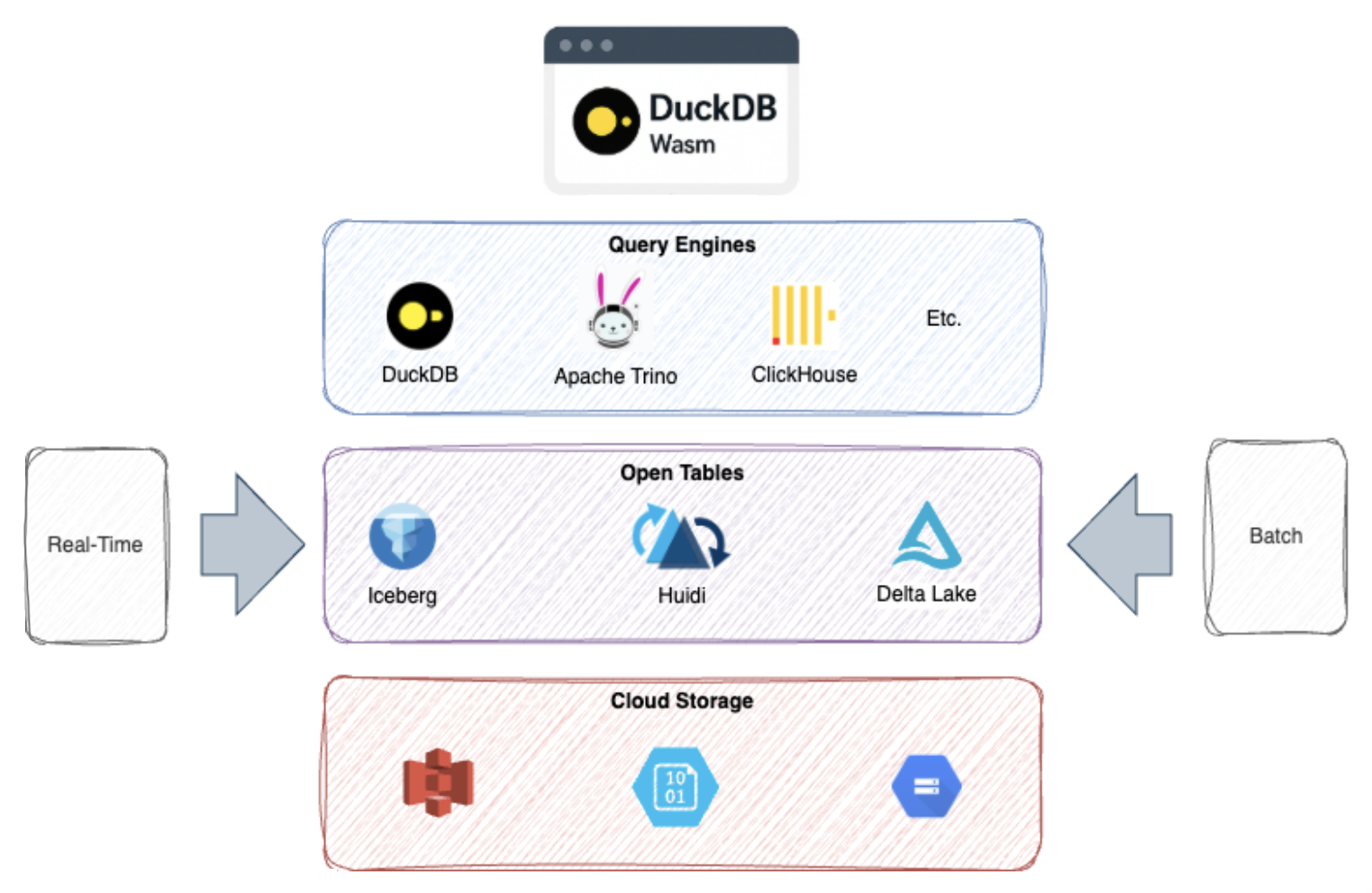
Open Table Formats as the Enabler
As data architectures evolve toward lakehouses and real-time analytics, open table formats have emerged as a critical component of scalable, maintainable system and multi-engine architecture. An open table format defines how to organize, manage, and track large datasets stored across files in cloud object storage. It adds a metadata layer on top of open files (Parquet, AVRO, or ORC), allowing query engines to treat a directory of files as a single, versioned, and transactional table. An open file format defines how the data is stored inside a file (structure, encoding, or compression), and an open table format defines how many files are organized and managed together as a logical, versioned, and queryable table.
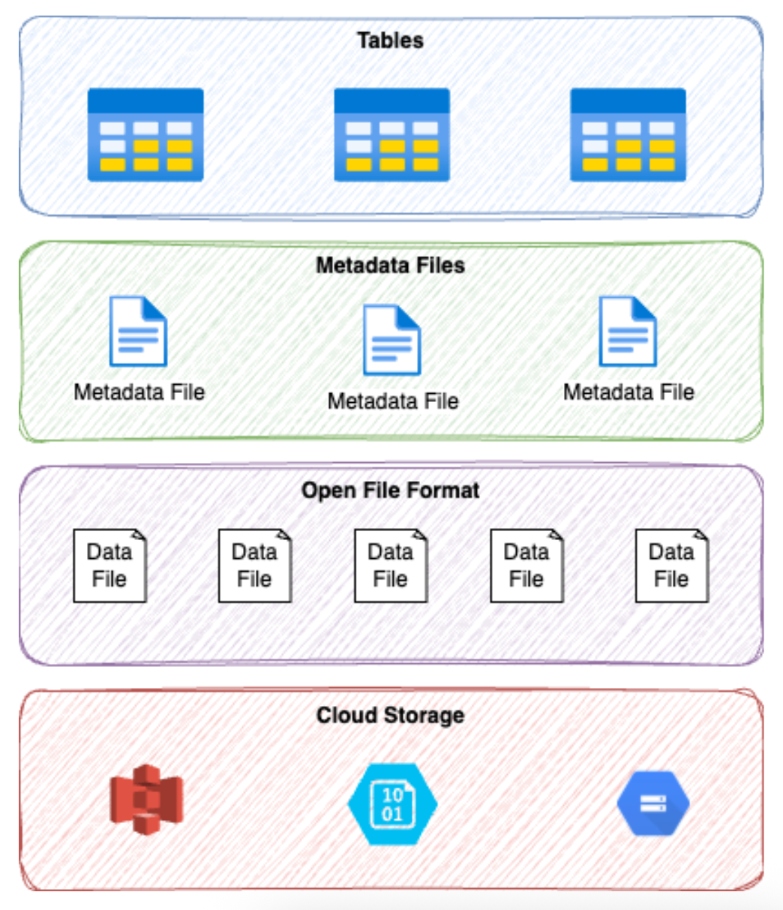
Open table formats support key features such as:
- ACID transactions – support insert/update/delete
- Schema evolution – change structure without rewriting everything
- Partitioning and pruning – enable faster queries
- Time travel – query past versions of your data
- Concurrent writes and reads – allows multiple engines to safely read/write in parallel
Rather than being tied to a specific vendor, open table formats allow data to be read and written by many engines — including Spark, Trino, Flink, Dremio, Snowflake, DuckDB, and Athena.
The most widely adopted open table formats today are Apache Iceberg, Delta Lake, and Apache Hudi. Apache Iceberg is quickly becoming the standard due to its:
- Engine neutrality – works seamlessly with Trino, Flink, Spark, Snowflake, and more
- Hidden partitioning – simplifies queries and avoids user-managed partitions
- Robust metadata management – scales to petabyte-level datasets efficiently with snapshot isolation and manifest pruning
- Better separation of metadata and data – enables high performance and fewer conflicts during concurrent writes
Unlike Delta Lake, Iceberg is not tied to a specific vendor, and unlike Hudi, it balances batch and streaming use cases more elegantly.
The Role of Query Engines and Single-Instance Architecture
With storage decoupled from the compute layer, organizations are no longer locked into a single analytics engine. Instead, modern architectures promote a multi-engine strategy where each tool plays a precise role: Trino for federation, ClickHouse for speed, and DuckDB for embedded insights. What ties them together is a common open table format — the Iceberg table — acting as the single, trusted interface for all compute layers.
Instead of centralizing all analytics in massive data warehouse clusters, modern architectures are leaning toward dynamic, on-demand compute layers. With formats like Iceberg, it's now feasible to load just a subset of the data (e.g., partition, snapshot) into a small, high-performance solution by plugging the data into different query engines depending on the use case — enabling greater flexibility, cost control, and performance tuning.
| Engine | Strength | IDeal Use Case |
|---|---|---|
|
DuckDB |
Embedded, local, ultra-fast |
In-browser analytics, notebooks, embedded dashboards |
|
Apache Trino |
Federated, distributed SQL over many sources |
Cross-source queries, enterprise data lake queries |
|
ClickHouse |
Real-time OLAP, high-concurrency analytics |
Product analytics, time series, operational dashboards |
|
Spark/Flink |
Batch and streaming compute at scale |
Data pipelines, heavy ETL, ML training |
Table 2. Query engine strengths and use cases
Each of these engines can read from Iceberg tables, allowing them to share a consistent and versioned view of the data, while offering different tradeoffs in latency, interactivity, and cost. This means:
- You don't have to move the entire dataset, just the slice that matters
- Query engines can be spun up instantly in containers or local environments
- Data engineers and analysts can perform high-speed analytics without needing massive infrastructure
Bringing Analytics to the Edge: Embedded Engines and In-Browser Compute
This evolution is driven by lightweight, high-performance engines that enable embedded databases at the edge using technologies like WebAssembly, making it possible to run SQL queries directly in the browser or on client devices. Engines like DuckDB bring OLAP-style analytics to the edge, while SQLite remains a widely used solution for OLTP workloads in mobile and embedded environments.
This shift is not just about conceptually bringing data closer to users — it's about running analytics physically in their environment. With embeddable engines, we're entering an era where queries are executed locally, unlocking powerful new patterns such as:
- Running analytics in the browser (WASM)
- Offline exploration of datasets
- Instant, local dashboards with zero back-end latency
- Embedding analytics into desktop apps or mobile tools
By minimizing infrastructure and maximizing locality, embedded analytics is redefining what's possible at the edge and bringing responsiveness, resilience, and autonomy to the forefront of modern data experiences.
Evolving Authorization: Data-Aware and Fine-Grained Access Control
As modern data architectures evolve into distributed and federated ecosystems — with multiple engines, domains, and access points — authorization becomes a critical, yet often overlooked, challenge. To truly democratize data, access control must evolve into something more context aware, fine-grained, and decoupled from infrastructure and traditional RBAC models.
While RBAC works in centralized environments, it quickly breaks down in data mesh or multi-engine lakehouse architectures, where access must be managed across domains, services, and tools.
To address this, a new class of tools is emerging, focused on fine-grained, distributed, and technology-agnostic authorization. Solutions like OpenFGA and Permit.io offer:
- Centralized policy management decoupled from application logic
- Attribute-based and relationship-based access control (ABAC/ReBAC)
- APIs to enforce consistent rules across services and platforms
- Native support for hierarchical and contextual rules (e.g., row-level access, data sensitivity levels)
These systems treat authorization as a first-class architectural concern, not just a checkbox. In the future, we may see access control policies become as modular and composable as the data stacks they govern — embedded across services, versioned alongside data definitions, and enforced consistently from the data lake to the browser.
Conclusion
As the boundaries between batch and real time blur, and as AI drives demand for both scale and interactivity, the future lies in architectures that are open, modular, and context aware. A lakehouse backed by Iceberg, powered by multiple engines, and extended all the way to the browser is no longer a future ideal but rather the blueprint for modern data platforms. The opportunity ahead is to embrace openness, modularity, and locality, putting data to work wherever it's needed, from the cloud to the edge.
This is an excerpt from DZone's 2025 Trend Report, Data Engineering: Scaling Intelligence With the Modern Data Stack.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments