Emerging Data Architectures: The Future of Data Management
This article explores the latest advancements in data architecture, focusing on frameworks and newer paradigms such as LakeDB and zero ETL architectures.
Join the DZone community and get the full member experience.
Join For FreeIn my last article about data architectures, you learned about emerging data architectures like data mesh, Generative AI, and Quantum-based, along with existing architectures like Data Fabric. In this article, you will continue to learn about emerging data architectures like LakeDB and Zero ETL, aligning with the future trends of Data Management and architecture.
The landscape of data architecture is evolving rapidly, driven by the increasing complexity of managing vast amounts of data and the growing adoption of advanced technologies such as generative AI, edge computing, and decentralized systems. As businesses strive to stay competitive in a data-centric world, emerging data architectures are reshaping how organizations store, process, and utilize their data.
This article explores the latest advancements in data architecture, focusing on frameworks like data mesh, data fabric, lakehouses, and newer paradigms such as LakeDB and Zero ETL architectures. These innovations promise to redefine scalability, accessibility, and efficiency in data operations.
Generative AI’s Influence on Data Architectures
Generative AI has become a transformative force in modern business operations. From automating content creation to enhancing customer interactions through chatbots and AI copilots, generative AI applications rely heavily on robust data architectures. These systems must accommodate the unique demands of generative AI models, which require large-scale data ingestion, real-time processing, and advanced governance.
Generative AI has introduced several key requirements for data architectures:
- Dynamic schema generation: The ability to adapt schemas automatically based on changing data requirements ensures flexibility.
- Real-time pipelines: Generative AI applications demand real-time or near-real-time processing to deliver instantaneous insights.
- Natural language interfaces: Simplified access to complex datasets through conversational queries enhances usability.
- Data quality assurance: High-quality datasets are essential for training generative models effectively.
- Feedback loops: Continuous improvement mechanisms allow generative AI systems to learn from user interactions.
These requirements have spurred the adoption of innovative architectures capable of supporting generative AI workloads while ensuring scalability and security.
Emerging Data Architecture Paradigms
Data Mesh: Decentralized Ownership
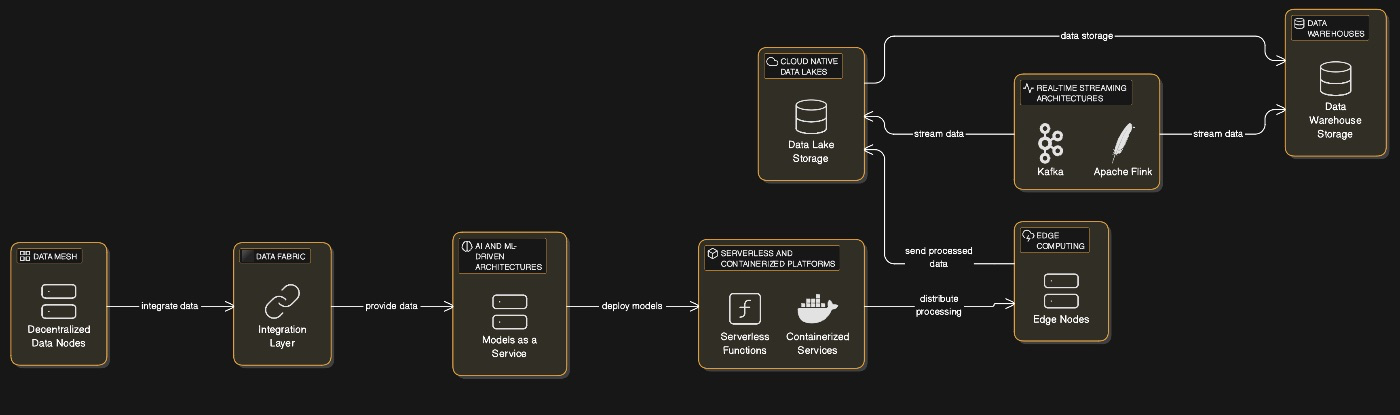
Data mesh is an architectural paradigm that decentralizes data ownership by assigning responsibility to domain-specific teams within an organization. Instead of relying on centralized IT departments to manage all organizational data, data mesh treats data as a product managed by the teams closest to it. This approach fosters collaboration across domains while ensuring that high-quality, domain-relevant data is readily accessible.
Key principles of data mesh include:
- Domain-oriented ownership: Each team manages its own datasets independently.
- Self-service infrastructure: Teams have access to tools for managing their data efficiently without relying on IT support.
- Federated governance: A governance framework ensures consistency across domains while allowing flexibility.
- Data discoverability: Metadata-driven discovery mechanisms enable users to locate relevant datasets easily.
Data mesh is particularly beneficial for large enterprises with diverse operations. However, implementing it requires careful planning to address challenges such as governance complexities and integration overhead.
Data Fabric: Unified Integration Across Environments
Data fabric represents a next-generation approach to integrating diverse datasets across hybrid environments (on-premises, cloud-based, and edge systems). By creating a unified layer for accessing and orchestrating data, it eliminates silos and simplifies management.
Key features of data fabric include:
- Metadata management: Centralized repositories enable efficient governance and discovery.
- AI-powered automation: Machine learning algorithms optimize processes like schema mapping and anomaly detection.
- Real-time synchronization: Support for real-time event processing ensures timely insights.
- Data virtualization: Abstracting complexities allows seamless access without physical movement.
Data fabric is ideal for organizations seeking agility in managing complex ecosystems while maintaining performance and compliance.
Lakehouse Architecture: Bridging Lakes and Warehouses
Lakehouse architecture combines the scalability of data lakes with the reliability of warehouses into a single system. This hybrid model addresses challenges associated with traditional lakes (e.g., unstructured storage) and warehouses (e.g., rigid schemas).
Key characteristics include:
- Unified storage: Supports both structured (SQL-based) and unstructured (object-based) storage formats.
- ACID transactions: Ensures reliability through atomicity, consistency, isolation, and durability.
- Integrated query engines: Enables efficient querying across diverse datasets.
- Metadata layers: Enhances transparency into stored datasets.
Lakehouses are gaining traction due to their ability to support advanced analytics while reducing operational complexity.
New Paradigms in Data Architecture
LakeDB: The Evolution of Lakehouses
LakeDB represents a significant leap forward from traditional lakehouse architectures by integrating database-like functionality directly into data lakes. Unlike existing lakehouses (e.g., Delta Lake or Apache Hudi), LakeDB natively manages buffering, caching, indexing, and write operations, eliminating the need for external processing frameworks like Apache Spark or Flink.
The benefits of LakeDB include:
- Enhanced performance through native management capabilities.
- Simplified workflows by reducing reliance on external processing tools like Spark or Flink.
- Greater interoperability across diverse workloads.
LakeDB is expected to play a pivotal role in bridging the gap between lakes, warehouses, and databases.
Comparative Table of Current LakeDB Offerings
| Offering | Key Features | Delivery Model | Best For |
|---|---|---|---|
| Chaos LakeDB | Generative AI support, SQL analytics | SaaS & embedded database | AI-driven applications |
| Google Napa Vision | Queryable timestamps, dynamic optimization | Conceptual framework | Fine-grained control over workloads |
| Delta/Hudi/Iceberg Enhancements | Materialized views, secondary indexing | Open-source tools | Incremental adoption of LakeDB features |
Zero ETL Architectures
Zero ETL (Extract, Transform, Load) architectures aim to minimize or eliminate traditional ETL processes by enabling organizations to analyze data directly at its source. This paradigm leverages technologies like federated query engines and virtualization layers to access and process data without duplication or movement.
Advantages of zero ETL include:
- Reduced latency by eliminating time-consuming ETL workflows.
- Improved security by minimizing exposure during data transfers.
- Enhanced collaboration through secure sharing protocols like Delta Sharing.
Zero ETL aligns well with modern enterprise needs for agility and efficiency in managing real-time analytics.
Supporting Technologies
Emerging architectures are supported by advanced tools that enhance their capabilities:
- AI-orchestrators: Automate complex workflows across multiple domains within decentralized systems.
- Knowledge graphs: Facilitate metadata-driven discovery for improved accessibility.
- Federated query engines: Enable seamless analysis across distributed datasets without physical movement.
- Cloud-native platforms: Provide scalable infrastructure optimized for hybrid environments.
These tools ensure that emerging architectures can meet the demands of modern enterprises effectively.
Future Trends in Data Architecture
As we move further into 2025, several trends are shaping the future of enterprise data management:
Edge Computing
Edge computing is becoming increasingly important as organizations deploy systems closer to their data sources rather than relying solely on centralized cloud infrastructures. By processing information locally at "the edge," businesses can reduce latency significantly while enhancing privacy protections—a critical requirement for IoT devices or localized AI models.
AI-Powered Pipelines
AI-powered pipelines simplify complex workflows associated with managing machine learning workloads while ensuring scalability across large-scale deployments. These pipelines automate tasks like feature extraction and anomaly detection while enabling real-time decision-making.
Domain-Specific Models
Specialized language models tailored for specific industries (e.g., healthcare or finance) are driving demand for domain-centric architectures that prioritize quality over quantity in dataset preparation.
Conclusion
The future success of enterprise operations lies in embracing cutting-edge paradigms such as data mesh, fabric systems, lakehouses, LakeDBs, zero ETL architectures — and beyond! The table below outlines how each architecture is supported by specific tools that enhance its functionality while aligning with modern enterprise needs.
By adopting these frameworks strategically alongside emerging technologies like generative AI and edge computing, businesses can unlock unprecedented efficiencies, scalability, and innovation opportunities.
|
Architecture |
Key Tools |
Description |
|---|---|---|
|
Data Mesh |
Apache Kafka, Databricks Unity Catalog |
Decentralized ownership; domain-oriented self-service infrastructure |
|
Data Fabric |
Informatica Intelligent Cloud Services, IBM Cloud Pak |
Unified integration; metadata-driven automation |
|
Lakehouse |
Databricks Delta Lake, Snowflake |
Combines lakes' scalability with warehouses' reliability |
|
LakeDB |
Delta Lake format with native management |
Database-like functionality integrated into object storage |
|
Zero ETL |
Apache Arrow Flight, Delta Sharing |
Direct analysis at source; eliminates traditional ETL workflows |
Opinions expressed by DZone contributors are their own.
Comments