Data Architectures With Emphasis on Emerging Trends
This article gives you a thorough rundown of the newest data architectures, tools, and technologies with an emphasis on emerging trends.
Join the DZone community and get the full member experience.
Join For FreeIn this emerging Generative AI era as a data architect, it is your responsibility to keep a tap on the emerging architectures that cater to Generative AI. From data management to data governance to data lineage, architectures need to emerge to handle volumes of data.
In this article, you learn about emerging data architectures like data mesh, Generative AI, and Quantum-based along with the existing architectures like Data Fabric. The article will conclude by showing the key differences between the existing and the emerging data architectures.
Generative AI and Data Architecture
As we started the article with Generative AI, it makes more sense to talk about how Generative AI including large language models (LLMs) and other generative models, is transforming how organizations process and utilize data. The generative AI models require vast amounts of high-quality data for training and inference, driving the need for scalable, flexible data architectures.
Key Components of Generative AI Architecture
- Data processing layer: This layer collects, organizes, and processes data for generative AI models. It is responsible for data cleansing, standardization, and feature extraction.
- The generative model layer: This layer contains AI models that generate new material or data and includes model selection, training, and fine-tuning.
- The feedback and improvement layer: This layer incorporates user feedback and interaction analysis to improve model performance.
- Application layer: This facilitates human-machine collaboration and makes AI models available via user interfaces or APIs.
- Model layer and hub: Consists of foundation models, fine-tuned models, and a centralized model hub for accessing and managing diverse AI models
Modern Data Architecture Paradigms
Data Mesh
Data mesh is a decentralized architecture that treats data as a product and assigns responsibility for each data domain (e.g., sales, marketing, finance) to the relevant business units. Data mesh is more about distributing data ownership and enabling cross-functional teams to manage data in a way that aligns with the business needs of that domain.
Example
In a large healthcare organization, each department like cardiology, radiology, and pathology owns and manages its own datasets, exposing them as products that can be accessed by other departments as needed.
Key Components
- Domain-oriented data products
- Self-serve data platform
- Federated governance
- Data discovery and catalog
Tools
- Apache Kafka
- Kubernetes
- Databricks Unity Catalog
- Collibra Data Intelligence Cloud
Data Fabric
Data fabric as a data architecture used by companies like IBM is a unified architecture that aims to provide seamless, integrated data access, governance, and management across all environments (on-premise, cloud, hybrid) using a combination of technologies, tools, and processes. To ensure a consistent data experience across an organization, the data fabric architecture focuses on data integration, discovery, security, and orchestration.
Data fabric can enable seamless data access and governance for customer data from multiple sources (websites, mobile apps, CRM systems) across different regions (Europe, Asia, North America) in a centralized manner.
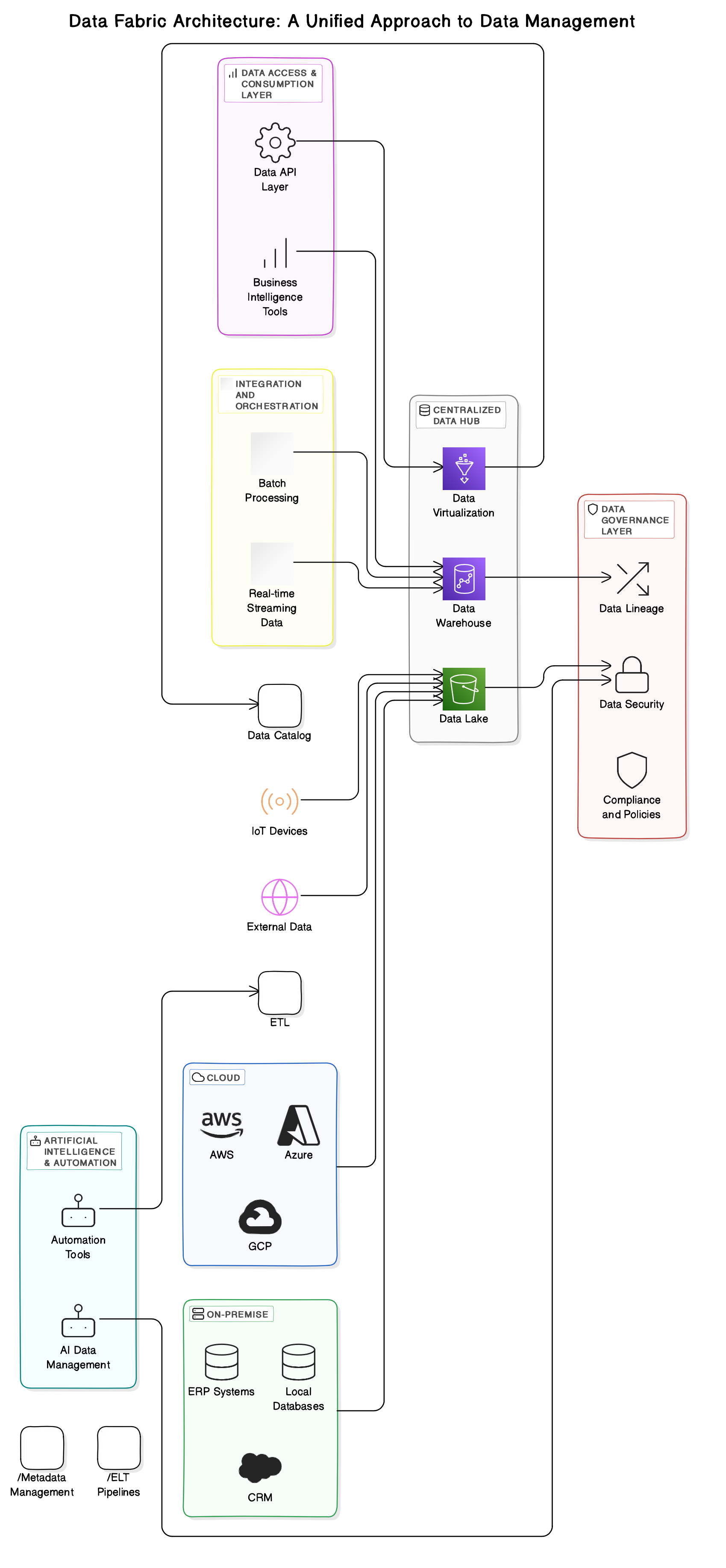
Data Fabric Architecture
Key Components
- Metadata management
- Data integration layer
- Data virtualization
- AI/ML engine for automated data management
Tools
- Informatica Intelligent Data Management Cloud
- IBM Cloud Pak for Data
- Talend Data Fabric
Lakehouse Architecture
Lakehouse combines the best features of data lakes and data warehouses. Lakehouses provide a flexible foundation for storing and processing the large datasets required for generative AI.
Key Components
- Object storage
- Metadata layer
- Query engine
- ACID transaction support
Tools
- Databricks Delta Lake
- Apache Hudi
- Snowflake
- Google BigLake
Cloud-Native and Real-Time Architectures
Cloud-native and real-time architectures are essential for supporting the computational demands and low-latency requirements of generative AI applications.
Key Components
- Serverless computing
- Containerization
- Stream processing
- In-memory computing
Tools
- AWS Lambda
- Azure Functions
- Apache Kafka
- Apache Flink
- Redis
AI and Machine Learning Integration
Specialized architectures for AI and ML workloads are crucial for supporting generative AI models.
Key Components
- Feature store
- Model registry
- Experiment tracking
- GPU clusters
Tools
- MLflow
- Kubeflow
- Amazon SageMaker
- Google Vertex AI
- Weights & Biases
Data Governance and Security
With the sensitive nature of data used in generative AI, robust governance and security measures are paramount.
Key Components
- Data catalog
- Data lineage tracking
- Fine-grained access control
- Data encryption
Tools
- Collibra
- Alation
- Apache Atlas
- HashiCorp Vault
Emerging Trends
Edge Computing
Edge computing is becoming increasingly important for deploying generative AI models closer to data sources, reducing latency, and improving privacy.
Tools
- Azure IoT Edge
- AWS IoT Greengrass
- TensorFlow Lite
Quantum Computing
While still in the early stages, quantum computing has the potential to revolutionize certain aspects of generative AI, particularly in areas like cryptography and complex optimization problems.
Tools
- IBM Quantum
- Google Cirq
- Microsoft Quantum Development Kit
Generative AI-Specific Architectures
Retrieval Augmented Generation (RAG)
RAG architectures combine retrieval systems with generative models to produce more accurate and contextually relevant outputs.
Key Components
- Document retrieval system
- Vector database
- LLM for generation
- Prompt engineering layer
Tools
- Pinecone
- Weaviate
- LangChain
- Haystack
Fine-Tuning and Transfer Learning Architectures
Fine-tuning and transfer learning architectures support adapting pre-trained generative models to specific domains or tasks.
Key Components
- Pre-trained model repository
- Fine-tuning pipeline
- Evaluation framework
- Model versioning system
Tools
- Hugging Face Transformers
- OpenAI GPT-3 Fine-tuning API
- Google T5
Multimodal Generative AI Architectures
Architectures supporting generative AI across multiple modalities (text, image, audio, video) are becoming increasingly important.
Key Components
- Modality-specific encoders and decoders
- Cross-modal attention mechanisms
- Unified representation learning
Tools
- OpenAI DALL-E
- Google Imagen
- NVIDIA Omniverse
Conclusion
To conclude, as a data architect, it's essential to understand these evolving architectures and how they can be applied to support generative AI initiatives within your organization. The choice of architecture may vary depending on the specific use cases, data volumes, performance requirements, and existing infrastructure. By leveraging these emerging architectures, tools, and technologies, you can design scalable, flexible, and efficient data systems that drive innovation in the era of generative AI.
| Aspect | Existing Architectures | EMERGING Architectures |
|---|---|---|
| Data Storage | Centralized (Data Warehouse, Data Lake) | Decentralized (Blockchain, Edge, Quantum Databases) |
| Data Processing | ETL, Batch Processing, Streaming | AI-driven automation, Quantum Computing, Edge processing |
| Data Ownership | Centralized (often by IT or a data team) | Domain-oriented (Data Mesh) or decentralized (Blockchain) |
| Scalability | Vertical scaling (on-premise) or hybrid (cloud-based) | Horizontal scaling (quantum, edge) and distributed (blockchain) |
| Data Governance | Centralized with manual interventions | AI-driven governance, automated compliance, decentralized governance |
| Real-Time Processing | Limited, often batch-driven, or near-real-time in cloud | Real-time everywhere (Edge, AI-driven automation) |
Opinions expressed by DZone contributors are their own.
Comments