Cutting P99 Latency From ~3.2s To ~650ms in a Policy‑Driven Authorization API (Python + MongoDB)
We cut tail latency by making queries index-friendly, removing cold-start connection costs, and overlapping third‑party I/O with computation.
Join the DZone community and get the full member experience.
Join For FreeModern authorization endpoints often do more than approve a request. They evaluate complex policies, compute rolling aggregates, call third‑party risk services, and enforce company/card limits, all under a hard latency budget. If you miss it, the transaction fails, and the failure is customer-visible.
This post walks through a practical approach to take a Python authorization API from roughly ~3.2s P99 down to ~650ms P99, using a sequence of changes that compound: query/index correctness, deterministic query planning, connection pooling and warmup, and parallelizing third‑party I/O.
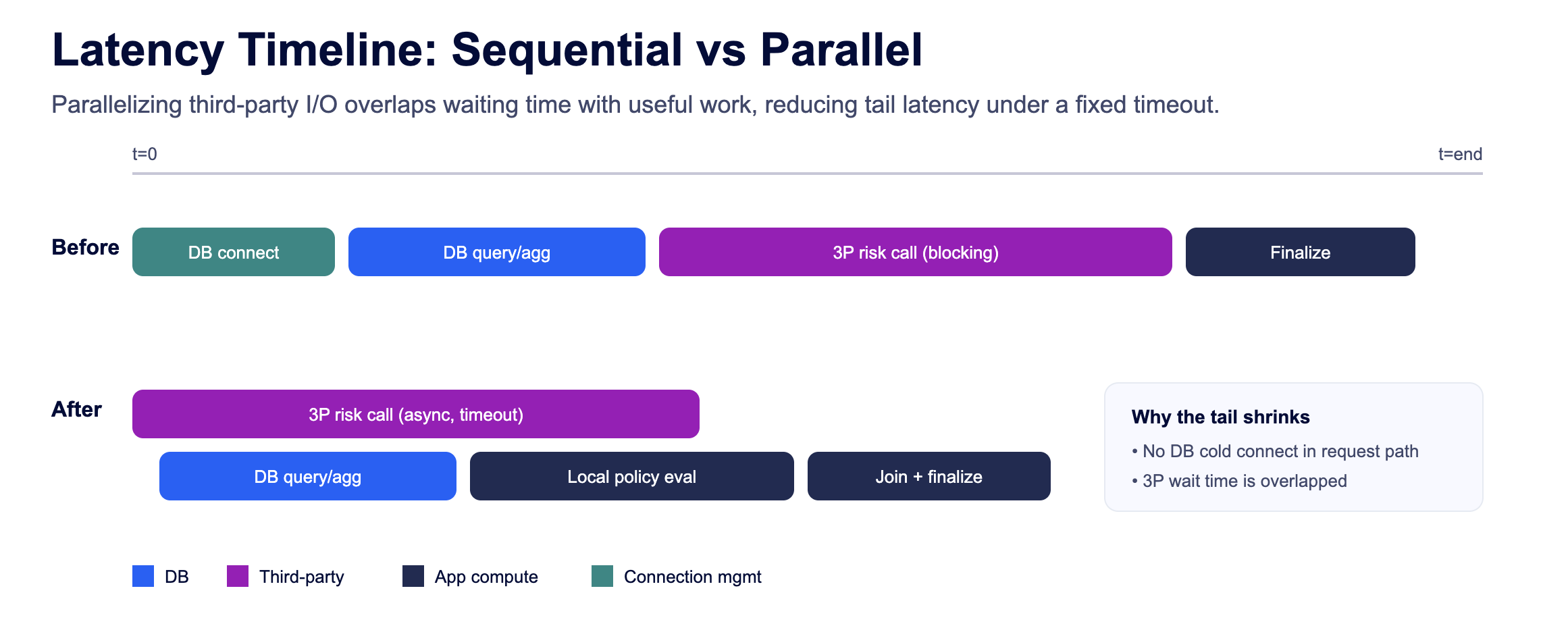
1. Baseline First: Measure Where The Tail Comes From
Before optimizing, capture:
- End‑to‑end p50/p95/p99
- A dependency breakdown (DB vs application vs third‑party)
- Production-like load and dataset scale
Minimal timing middleware (FastAPI):
import time
from fastapi import FastAPI, Request
app = FastAPI()
@app.middleware("http")
async def timing_middleware(request: Request, call_next):
start = time.perf_counter()
resp = await call_next(request)
elapsed_ms = (time.perf_counter() - start) * 1000
resp.headers["Server-Timing"] = f"app;dur={elapsed_ms:.2f}"
return resp
Structured spans around dependencies:
import time
import logging
log = logging.getLogger(__name__)
class Span:
def __init__(self, name: str):
self.name = name
def __enter__(self):
self.t0 = time.perf_counter()
return self
def __exit__(self, exc_type, exc, tb):
dt_ms = (time.perf_counter() - self.t0) * 1000
log.info("span=%s duration_ms=%.2f", self.name, dt_ms)
def authorize(req):
with Span("db.rollup"):
rollup = compute_rollup(req)
with Span("third_party.risk"):
risk = call_risk(req)
with Span("policy.eval"):
decision = eval_policy(req, rollup, risk)
return decision
This tells you whether P99 is dominated by slow queries, connection setup, third‑party calls, or CPU.
2. Fix Index Usage: Composite Indexes Work Left to Right
A common P99 killer: an index exists, but the query shape prevents using it efficiently.
Assume a transaction document:
{
"company": "acme",
"role": "employee_123",
"card": "card_456",
"transaction_date": "2026-01-25T12:00:00Z",
"amount_cents": 1299
}
And a composite index:
from pymongo import ASCENDING
db.transactions.create_index([
("company", ASCENDING),
("role", ASCENDING),
("card", ASCENDING),
("transaction_date", ASCENDING),
])
The Pitfall: Missing the Left-Most Field(s)
Bad (omits company):
query = {
"role": role_id,
"card": card_id,
"transaction_date": {"$gte": start, "$lt": end},
}
Better:
query = {
"company": company_id,
"role": role_id,
"card": card_id,
"transaction_date": {"$gte": start, "$lt": end},
}
Verify With explain().
plan = db.transactions.find(query).explain()
print(plan["queryPlanner"]["winningPlan"])
If you see COLLSCAN or a plan not using the intended index, that’s usually a direct line to tail latency.
3. Make Query Planning Deterministic (When You Must)
Even with correct indexes, intermittent P99 spikes can come from the query planner choosing a different index based on changing stats or data shape.
Detect plan variance.
def plan_and_run(coll, query, projection=None, limit=0):
plan = coll.find(query, projection=projection).limit(limit).explain()
winning = plan["queryPlanner"]["winningPlan"]
rows = list(coll.find(query, projection=projection).limit(limit))
return winning, rows
If slow traces correlate with a different winning plan, you can:
- Adjust indexes so the correct plan is always best, or
- Apply a selective hint for the most latency-sensitive queries
Hint example (MongoDB):
idx_name = "company_1_role_1_card_1_transaction_date_1"
cursor = db.transactions.find(query).hint(idx_name)
Use hints carefully: they can become wrong as the data distribution evolves. If you hint, add monitoring (e.g., periodic explain() in staging with production-like data).
4. Stop Paying Connection Setup on the Request Path: Pool + Warm
Connection setup costs can be surprisingly high (TCP/TLS/auth/discovery), and cold pods can drag P99.
Use a single global pooled client per process.
from pymongo import MongoClient
mongo = MongoClient(
MONGO_URI,
maxPoolSize=200,
minPoolSize=20,
serverSelectionTimeoutMS=250,
connectTimeoutMS=250,
socketTimeoutMS=900,
)
db = mongo["payments"]
Warmup on startup (avoid cold-start penalties).
def warmup():
db.command("ping")
db.transactions.find_one({"company": "__warmup__"})
db.limits.find_one({"company": "__warmup__"})
warmup()
In Kubernetes, run warmup before the service reports readiness so traffic only hits warmed instances.
5. Parallelize Third‑Party I/O With Local/DB Work
Third‑party risk/fraud calls often dominate the tail. If you call synchronously, you idle while waiting. A better pattern is to start the call first, do independent work, then join with a strict timeout.
Threaded overlap pattern (requests + ThreadPoolExecutor).
import requests
from concurrent.futures import ThreadPoolExecutor, TimeoutError
SESSION = requests.Session()
EXEC = ThreadPoolExecutor(max_workers=64)
def risk_call(payload, timeout_s: float = 1.1):
resp = SESSION.post(
"https://risk.example.com/score",
json=payload,
timeout=(0.2, timeout_s), # connect, read
)
resp.raise_for_status()
return resp.json()
def authorize(req):
fut = EXEC.submit(risk_call, {"company": req.company, "amount": req.amount_cents})
# Independent work while the network call is in flight
rollup = compute_rollup(req) # DB aggregation / cached rollups
base = eval_local_policy(req, rollup) # pure CPU / local logic
# Join with timeout and safe fallback behavior
try:
risk = fut.result(timeout=1.1)
except TimeoutError:
risk = {"status": "timeout", "score": None}
except Exception:
risk = {"status": "error", "score": None}
return finalize_decision(base, risk)
This preserves a hard cap while reclaiming idle time. It’s one of the most reliable ways to reduce P99 when a dependency is volatile.
6. Prevent Regression: Make Performance A Testable Contract
Once you’ve improved P99, keep it. Add a repeatable performance test that:
- Runs the hot path thousands of times
- Asserts p95/p99
- Uses a realistic dataset scale and index configuration
import time
import statistics
def run_trials(n=3000):
times = []
for _ in range(n):
t0 = time.perf_counter()
authorize(sample_request())
times.append((time.perf_counter() - t0) * 1000)
times.sort()
return {
"p50": statistics.median(times),
"p95": times[int(0.95 * len(times)) - 1],
"p99": times[int(0.99 * len(times)) - 1],
"max": max(times),
}
print(run_trials())
Takeaways
If you’re trying to move tail latency (not just average latency), these tend to be the biggest levers:
- Query shape + index correctness (especially composite indexes)
- Stabilizing query planning (index tuning or selective hinting)
- Connection pooling and warmup (remove cold-start penalties)
- Overlapping third‑party I/O with useful work (reduce idle wait)
Apply them in that order, validate each change with P99 measurements, and you’ll get repeatable gains instead of “optimizations” that don’t show up where it matters.
Opinions expressed by DZone contributors are their own.
Comments