Transforming Data into Decisions: Crafting Generative AI That Delivers Accurate Intelligence
This article explores how integrating rigorous data practices, and machine learning techniques can elevate the performance of generative AI systems.
Join the DZone community and get the full member experience.
Join For FreeIntroduction: Generative AI, driven by advancements in machine learning (ML), has transformed various industries by enabling machines to create text, images, music, and even code. However, developing robust, reliable, and personalized generative systems involves more than just large language models. Crucial components include data validation, thorough testing, personalized ranking, and structured reasoning (for example, chain-of-thought prompting). These elements are essential for improving the accuracy, relevance, and adaptability of generative AI systems.
This article will examine how integrating rigorous data practices, machine learning techniques such as personalized re-ranking, and reasoning strategies can improve the performance of generative AI systems. We will also introduce visual aids to clarify concepts such as linear classification, validation pipelines, and customer-centric ranking systems.
Why Now?
The rapid rise of large language models (LLMs) from research demonstrations to mainstream customer-facing tools has been remarkable. By early 2024, popular generative AI services were already serving hundreds of millions of users each month. Analysts predict that AI could facilitate 95% of customer interactions by 2025. Companies are racing to integrate LLM-driven chatbots, assistants, and content generators into products across various industries. This swift adoption means that more users than ever are engaging with AI outputs daily, ranging from banking chatbots to AI writing assistants, often without expert oversight.
Challenges
- Model Hallucinations: Unchecked language models fabricate facts or details, undermining user trust and leading to misinformation.
- Amplified Bias: Hidden data skews causing discriminatory or unethical outputs with real-world impacts on individuals and organizations.
- Data Corruption: Incomplete, inconsistent, or tampered data feeding into training or inference pipelines, resulting in faulty predictions or system failures.
- Regulatory Non-Compliance: Violations of data privacy, fairness, or industry-specific regulations (e.g., GDPR, FCRA) expose the business to legal penalties and reputational damage.
Importance of Data Testing and Validation in Generative AI: High-quality data is crucial for any reliable generative AI system. Without thorough testing and validation, even the most advanced models can generate outputs that are inaccurate, inconsistent, or biased, which undermines user trust and diminishes business value. Here are the key reasons why comprehensive data testing and validation should be a fundamental part of any generative AI pipeline
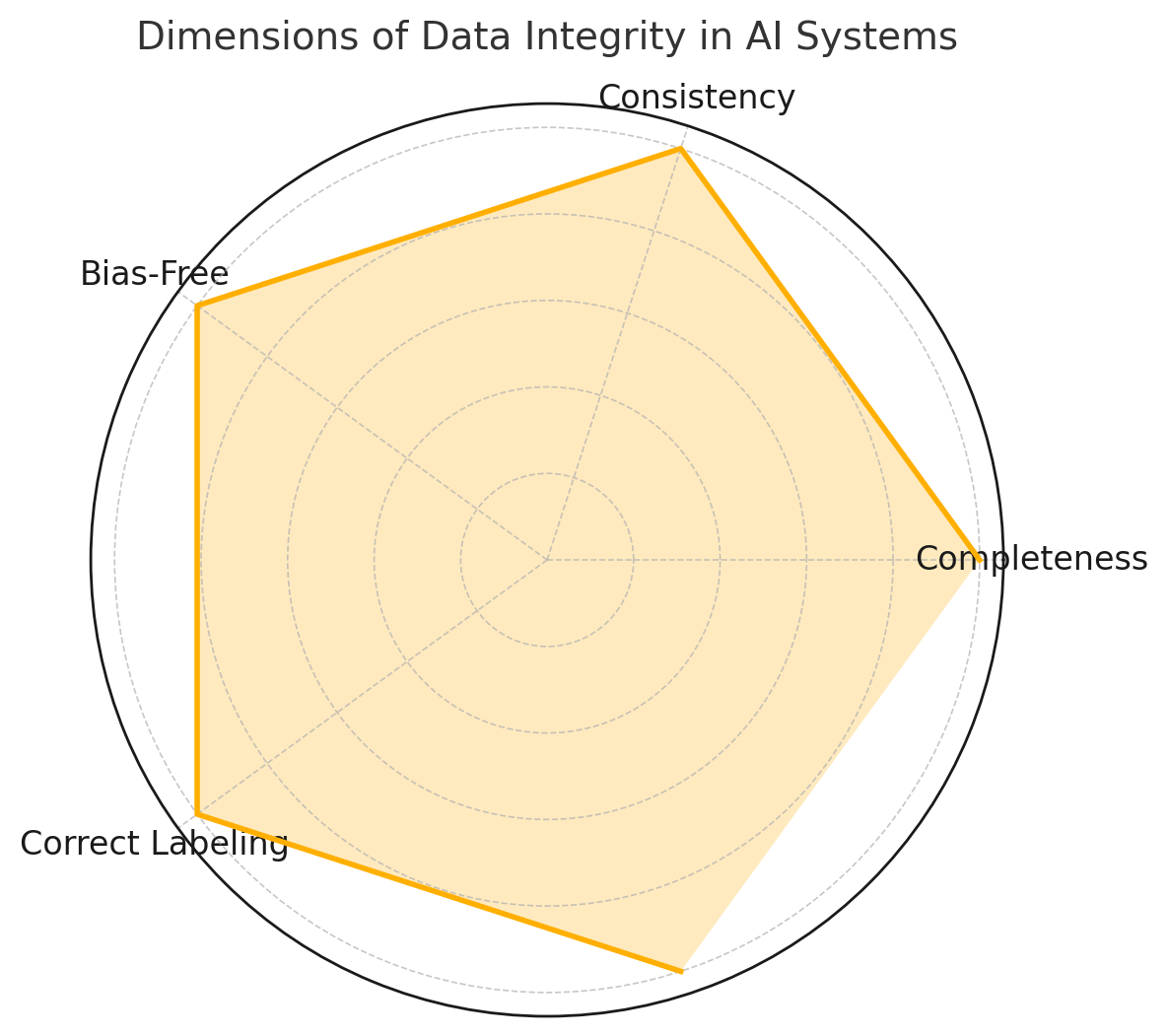
Ensuring Data Integrity: The Cornerstone of Reliable AI Models: Data integrity is not just a preliminary step; it is the foundation of all reliable AI systems. In generative AI, the quality of the data directly influences the relevance, safety, and fairness of the model’s outputs. A model trained on flawed or biased data will inevitably produce inaccurate, inappropriate, or misleading results, regardless of how advanced the underlying algorithms may be. Ensuring data integrity requires actively verifying and maintaining the trustworthiness of input data across several critical dimensions.
- Completeness: Missing records, null values, or incomplete feature sets can distort learning and introduce unintended behavior in model predictions. For instance, missing timestamp data in a conversational AI system may impair its ability to understand sequence and context.
- Consistency: Uniform formatting, unit alignment, and encoding standards are essential for seamless data ingestion and model training. Discrepancies—such as mixing currencies or measurement units—can silently erode model accuracy.
- Freedom from Bias: Biased data can amplify societal or structural inequities. Whether the bias originates from underrepresented user groups, skewed sampling methods, or historical decisions, its effects can be profound. Validating datasets for demographic parity, fairness constraints, or sentiment skew is vital to developing ethical AI systems.
- Correct Labeling: In supervised learning, mislabeled data introduces noisy signals that degrade model performance. Ensuring accurate and consistent ground-truth labels—especially in domains such as medical imaging, customer behavior, or sentiment analysis—is crucial for producing trustworthy results.
To Illustrate:
Imagine a product recommendation engine that is trained on incomplete and biased transaction logs. If purchases from certain regions are underrepresented or misclassified, the model may incorrectly conclude that there is lower interest in those products, resulting in their suppression in search rankings. This could lead to lost revenue and decreased user satisfaction. In contrast, using tools like AWS Glue DataBrew or custom Lambda validation jobs can help identify anomalies early in the pipeline. This practice not only preserves the quality of the model but also maintains business trust. Ultimately, robust generative AI relies on high-quality data. This isn't just a technical best practice; it's a fundamental requirement for ensuring fairness, accuracy, and long-term reliability in AI-driven systems.
Key Strategies for Ensuring Data Integrity
1. Schema Validation: Schema validation ensures the structural consistency of your data, including data types, required fields, and format standards.
# Example with AWS Deequ (Spark-based schema validation)
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
from com.amazon.deequ.checks import *
from com.amazon.deequ.verification import *
spark = SparkSession.builder.appName("DeequExample").getOrCreate()
schema = StructType().add("customer_id", StringType(), True)\
.add("age", IntegerType(), True)
df = spark.read.schema(schema).csv("s3://your-bucket/data/customers.csv")
check = Check(spark, CheckLevel.Error, "SchemaValidation")\
.hasSizeGreaterThan(0)\
.isComplete("customer_id")\
.isNonNegative("age")
VerificationSuite(spark)\
.onData(df)\
.addCheck(check)\
.run()2. Missing Data Handling: Detecting and imputing (or removing) missing values is vital for both training and serving robust models. Tool: AWS Glue DataBrew - DataBrew enables visual inspection of data quality and allows for the cleaning, normalization, and transformation of data without requiring code.
Example:
- Set up a Data Profile Job in AWS Glue DataBrew.
-
Configure transformations like “Fill missing values with median” or “Drop rows where target column is null.”
3. Bias Detection & Fairness Audits: Identifying sampling bias, representation gaps, or target leakage is key for ethical AI systems.
Tool: Amazon SageMaker Clarify. SageMaker Clarify can detect class imbalance, analyze feature correlation with sensitive attributes (e.g., gender, race), and compute bias metrics before and after model training
# Bias analysis with SageMaker Clarify (JSON configuration example)
clarify_config = {
"dataset_type": "text/csv",
"label": "outcome",
"facet": "gender",
"methods": ["difference_in_outcomes", "disparate_impact"],
}
4. Label Verification and Ground Truth Auditing: Accurate labeling is critical for supervised learning. Mislabels reduce model performance and trustworthiness.
Technique:
- Manual Spot Checks + Consensus Review
- Use Amazon SageMaker Ground Truth for human-in-the-loop data labeling
- Integrate spot checks for sampling audit batches
- Use majority vote or consensus strategies for subjective tasks (e.g., sentiment)
5. Outlier Detection: Outliers can skew model predictions and must be identified early in the pipeline.
Tool: Amazon SageMaker Data Wrangler or PyOD (Python)
#Using PyOD for outlier detection
from pyod.models.iforest import IForest
from sklearn.preprocessing import StandardScaler
import pandas as pd
df = pd.read_csv("data.csv")
features = ["feature1", "feature2"]
X = StandardScaler().fit_transform(df[features])
model = IForest()
model.fit(X)
df["outlier_score"] = model.decision_function(X)
df["is_outlier"] = model.predict(X)[Raw Data]
↓
[Schema Checks] → [Missing Value Imputation]
↓
[Bias Analysis & Label Audit]
↓
[Outlier Detection]
↓
[Model Input / Retraining]
Achieving data integrity is a continuous process that spans data collection, transformation, validation, and monitoring. By combining tools like AWS Glue, Deequ, DataBrew, SageMaker Clarify, and manual auditing techniques, organizations can significantly reduce data-related errors, ensuring that their generative AI models are accurate, fair, and ready for real-world deployment.
Data-to-Decision Pipeline: From Raw Input to Generative Output
To operationalize Generative AI with integrity, we need to ensure that each stage, from raw data collection to final generation, is rigorously designed. This includes:
- Data Ingestion and Preprocessing
- Tools: AWS Glue, Lambda, DataBrew
- Tasks: Cleaning, schema enforcement, and missing value handling
- Bias and Label Validation
- Tools: SageMaker Clarify, Ground Truth
- Tasks: Fairness audits, label verification
- Model Training or Fine-tuning
- Tools: SageMaker, HuggingFace Transformers, LoRA
- Tasks: Fine-tune LLMs or recommendation engines with clean inputs
- Personalized Ranking
- Tools: XGBoost, LightGBM, or neural models
- Tasks: Re-ordering recommendations based on individual behavior
- Generative Output with Reasoning (Chain-of-Thought Prompting)
- Prompt design → Multi-step reasoning → Explanation-aware output
- Use in: Recommender justification, FAQ generation, customer insight summarization
- Monitoring and Feedback Loops
- Tools: CloudWatch, Model Monitor
- Tasks: Data drift detection, output audit, real-time guardrails
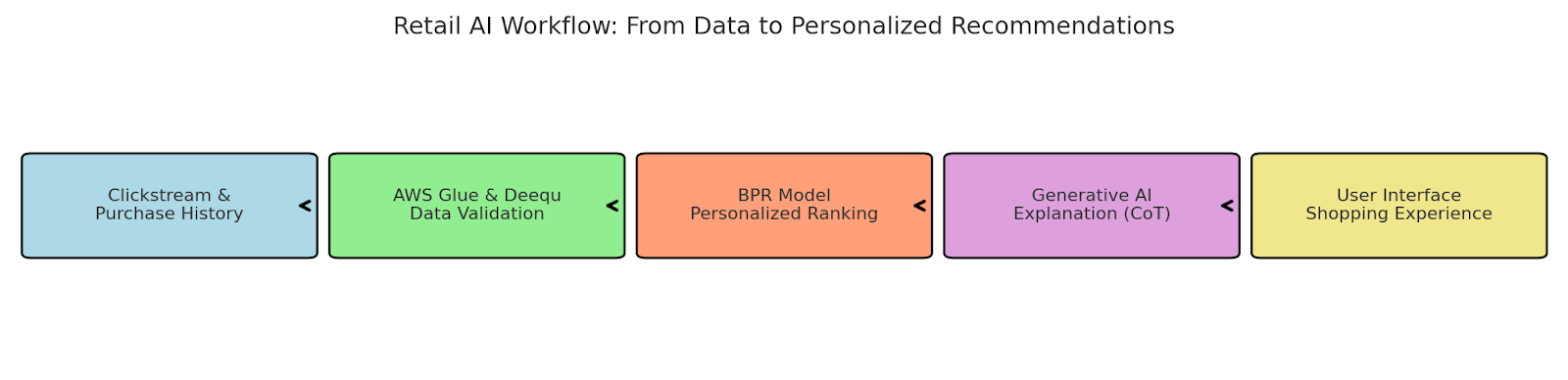
Retail AI Use Case: Customer Decision Pipeline
Consider a large online retail platform aiming to enhance product discovery and increase conversion rates through AI-driven personalization. The platform collects extensive user behavior data, including clickstream logs, past purchases, product ratings, and dwell time. To ensure data integrity, it applies schema validation, outlier detection, and missing value handling using AWS Glue and Amazon Deequ. These steps help cleanse the dataset of inconsistencies and biases before model training begins.
Next, the platform leverages Bayesian Personalized Ranking (BPR) to build a recommender system that predicts user preferences based on implicit feedback. This model reorders product listings on a per-user basis, surfacing items more likely to align with each customer’s interests. To further enhance engagement, the platform integrates a Generative AI model with a chain-of-thought prompting mechanism to explain recommendations in natural language. For example, instead of merely showing shoes, the system explains: “You’ve shown interest in trail running shoes. Here are newer models from your favorite brand.” This combination of validated data, personalized ranking, and transparent reasoning leads to a more informed shopping experience, resulting in a 12% increase in conversion rates while enhancing customer trust.
Conclusion: The power of Generative AI is only as strong as the integrity of its foundation and the intelligence of its design. By validating data, ensuring fairness, personalizing rankings, and enabling structured reasoning through chain-of-thought prompting, we can build systems that are not only creative but also responsible, transparent, and aligned with real-world decision-making.
From raw inputs to personalized, explainable outputs, this data-to-decision journey ensures that Generative AI works not only more complexly but also smarter.
Opinions expressed by DZone contributors are their own.
Comments