From Data Lakes to Intelligence Lakes: Augmenting Apache Iceberg With Generative AI Metadata on AWS
Build an AI-augmented data lake using Iceberg, Glue, and Bedrock to turn static metadata into searchable intelligence with semantic tags and AI summaries.
Join the DZone community and get the full member experience.
Join For FreeOver the last decade, we've seen data lakes evolve from static storage into dynamic, queryable systems.
With Apache Iceberg, engineers gained ACID transactions and schema evolution on Amazon S3. With AWS Glue, metadata management became serverless and automatic.
Yet one limitation persists: metadata still lacks intelligence.
Your Glue catalog knows column names and data types, but it doesn’t know what those fields represent in real life. It can’t tell you that customer_id maps to a CRM entity, or that email is a piece of PII that should trigger compliance checks.
The next leap forward is building AI-augmented data lakes, or what I call Intelligence Lakes, environments that not only store data but can describe, categorize, and connect it automatically using Generative AI.
Why Traditional Metadata Falls Short
Typical data catalogs store structural metadata such as names, types, partitions, and lineage. They’re perfect for machines but difficult for humans.
An analyst searching for “customer intent” data might find 40 similarly named tables: customer_behavior, cust_intentions_v2, ad_clicks_final, leadscore_events, etc.
Without a business context, it’s impossible to know which one truly represents the customer journey.
As datasets grow, so does this “semantic sprawl.” What’s missing is an intelligent layer that understands what the data means, not just how it’s stored.
The Shift: Generative AI for Metadata Intelligence
Generative AI introduces that missing semantic layer. By combining large language models and embedding models, we can automatically:
- Summarize a table’s business purpose.
- Tag fields as PII, identifiers, or metrics.
- Link related datasets across domains.
- Answer questions about data in natural language.
Think of it as moving from schema-on-read to context-on-read. Instead of asking “What columns exist?”, we can ask “Which datasets measure customer churn?”
Architecture Overview
Below is the high-level architecture of an Intelligence Lake built on AWS.
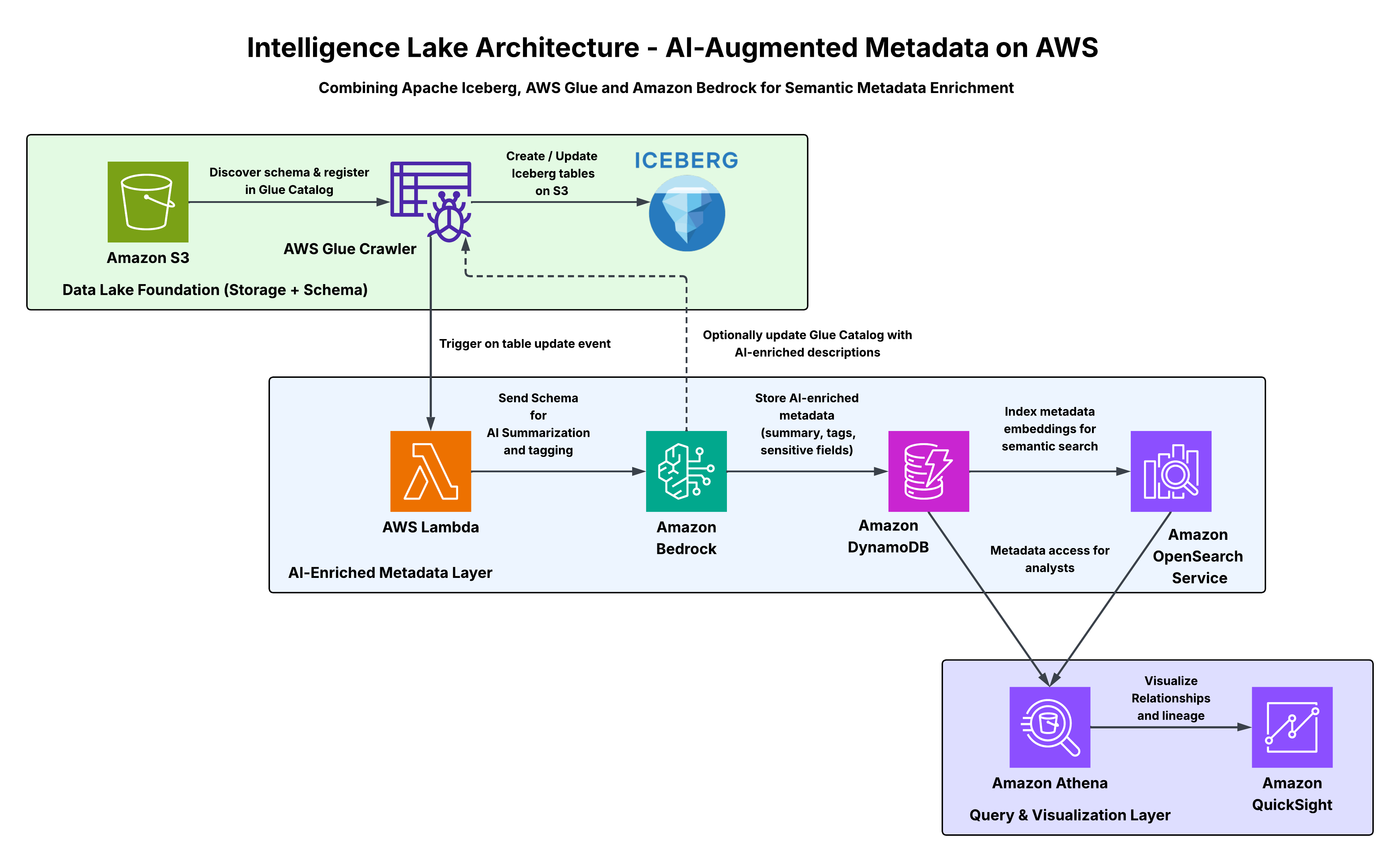
Step-by-Step Implementation
Step 1: Create the Iceberg Table
CREATE TABLE iceberg_demo.customer_behavior (
customer_id STRING,
session_id STRING,
channel STRING,
dwell_time DOUBLE,
purchase_flag BOOLEAN,
email STRING
)
LOCATION 's3://intelligence-lake/iceberg_demo/customer_behavior/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='PARQUET'
);
This defines a transactional Iceberg table registered in AWS Glue.
Step 2: Lambda for Metadata Enrichment
Each time Glue updates, a Lambda function triggers an Amazon Bedrock model (Claude 3 Sonnet or Titan) to summarize the schema and flag sensitive fields.
import boto3, json
bedrock = boto3.client('bedrock-runtime')
glue = boto3.client('glue')
dynamodb = boto3.client('dynamodb')
def lambda_handler(event, context):
db_name, table_name = event['database_name'], event['table_name']
schema = glue.get_table(DatabaseName=db_name, Name=table_name)
columns = schema['Table']['StorageDescriptor']['Columns']
prompt = f"""
Analyze this schema and return JSON with:
summary, semantic_tags, sensitive_fields.
Schema: {json.dumps(columns)}
"""
res = bedrock.invoke_model(
modelId='anthropic.claude-3-sonnet-2024-10-01',
body=json.dumps({'prompt': prompt})
)
output = json.loads(res['body'].read().decode())
dynamodb.put_item(
TableName='intelligence_lake_metadata',
Item={
'table_name': {'S': table_name},
'summary': {'S': output.get('summary', 'NA')},
'semantic_tags': {'S': ','.join(output.get('semantic_tags', []))},
'sensitive_fields': {'S': ','.join(output.get('sensitive_fields', []))}
}
)Step 3: Enriched Metadata Example
{
"table_name": "customer_behavior",
"summary": "Tracks cross-channel user activity and dwell time across sessions.",
"semantic_tags": ["customer", "marketing", "session", "conversion"],
"sensitive_fields": ["email"]
}
This AI-enriched JSON is stored in DynamoDB for fast access and optionally indexed in OpenSearch for similarity queries.
Step 4: Semantic Search With OpenSearch
from opensearchpy import OpenSearch
client = OpenSearch(
hosts=[{'host': 'search-intelligence-lake.us-east-1.es.amazonaws.com', 'port': 443}],
http_auth=('admin', 'password'),
use_ssl=True, verify_certs=True
)
query_vec = [0.31, 0.22, 0.48, ...] # Titan embedding for "customer intent"
res = client.search(
index="intelligence-lake",
body={"query": {"knn": {"embedding_vector": {"vector": query_vec, "k": 3}}}}
)
for hit in res['hits']['hits']:
print(hit['_source']['table_name'], hit['_score'])Now queries like “datasets related to churn” retrieve semantically linked tables even if naming conventions differ.
Step 5: Expose Through Athena
SELECT table_name, summary
FROM intelligence_lake_metadata
WHERE contains(semantic_tags, 'churn');
Analysts can explore datasets by concept, not by file path.
Why This Matters
This approach bridges the gap between data engineering and knowledge engineering.
Benefits observed in enterprise prototypes:
- 40% faster dataset discovery for analysts.
- 60% reduction in manual documentation effort.
- Automated PII detection across hundreds of tables.
- Natural-language data exploration using Bedrock-powered chat interfaces.
Instead of maintaining static documentation, metadata becomes living knowledge, continually updated as the lake evolves.
The Role of Embeddings and Governance
Embedding models (e.g., Titan Text Embeddings v2) convert schema names and descriptions into numeric vectors that capture meaning.
This allows you to measure dataset similarity, cluster related domains, or recommend joins.
From a governance perspective, AI tagging supports:
- Row- and column-level policies (e.g., Lake Formation).
- Data-classification dashboards that track PII exposure.
- Explainable lineage graphs enriched with natural-language context.
It’s an early step toward self-governing data ecosystems, where metadata drives both discovery and compliance.
Challenges and Next Steps
Like any AI-driven workflow, this approach isn’t without hurdles:
- Model accuracy: LLMs can misinterpret niche domain schemas. Human validation loops remain vital.
- Cost management: Each enrichment call to Bedrock or Titan incurs API costs; batching and caching strategies help.
- Security: Don’t send sensitive data values, only schema metadata, to AI models.
- Versioning: Metadata itself must be versioned alongside Iceberg snapshots for traceability.
Future enhancements may include reinforcement learning (RL) for continuous metadata improvement and multi-modal embeddings that incorporate lineage, query logs, and sample data statistics.
Comparative Snapshot
| Feature | Traditional lake | intelligence lake |
|---|---|---|
| Metadata | Static | AI-enriched |
| Discovery | Manual search | Semantic search |
| Documentation | Human-written | Auto-generated |
| Compliance | Reactive | Proactive |
| Onboarding | Slow | Instant context |
Conclusion
We are witnessing a pivotal shift in data engineering.
The combination of Apache Iceberg for structure, AWS Glue for automation, and generative AI for understanding transforms the traditional data lake into a truly Intelligent Data Platform.
This isn’t just about automation. It’s about context awareness. A platform that can describe, classify, and connect its own data unlocks faster analytics, stronger governance, and new creative possibilities.
Iceberg provides the foundation. Glue provides the plumbing. AI provides the intuition.
Together, they build the Intelligence Lake, where data finally speaks the language of business.
Opinions expressed by DZone contributors are their own.
Comments