Stop Your GenAI From Burning Cash in Production
GenAI in production is expensive, but most teams waste 60-80% of their budget on preventable mistakes. Five proven optimizations that cut costs by 40-75%
Join the DZone community and get the full member experience.
Join For FreeEvery developer who's deployed GenAI to production knows this moment. The feature works great. Users love it. Then the cloud bill arrives.
Your harmless chatbot just cost more than your entire infrastructure. That RAG pipeline you built? It's eating tokens like there's no tomorrow. Welcome to the reality of production GenAI, where every API call has a price tag.
The problem isn't GenAI itself. It's that most teams deploy first and optimize never. Studies indicate that over 75% of GenAI-driven productivity programs fail to deliver measurable cost reductions. The teams that succeed aren't using less AI. They're using it smarter.
The Real Cost Problem Nobody Talks About
Traditional software has predictable costs. You provision servers, pay monthly, done. GenAI breaks this model completely. Every user interaction costs money. Every word generated. Every piece of context you feed the model.
A typical enterprise chatbot handling 10,000 queries daily can rack up $20,000+ monthly just in API costs. Scale that to millions of users and you're looking at bills that would make your CFO cry.
The worst part? Most of this spending is waste. Analysis across production deployments shows teams waste 60–80% of their GenAI budget on:
- Using GPT-5 for simple tasks smaller models could handle
- Regenerating identical responses thousands of times
- Stuffing entire documents into prompts when a paragraph would do
- Running expensive models for basic data extraction
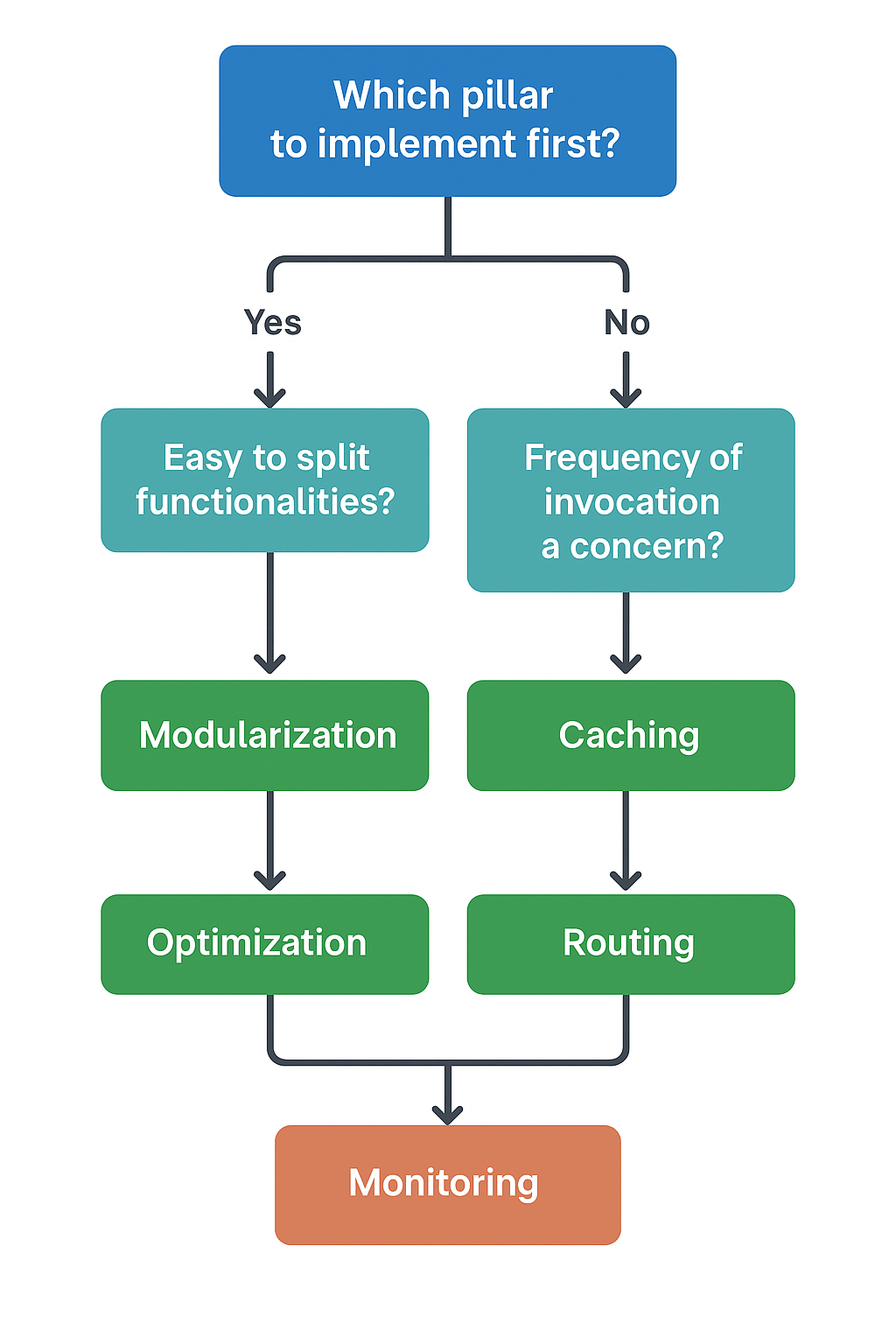
Figure 1. Flowchart for choosing which optimization pillar to start with.
Five Ways to Cut Costs Without Killing Quality
After building GenAI systems that went from hemorrhaging money to profitable, I've identified five techniques that actually work. Not theory. Real production tactics. Teams implementing these strategies typically see 40-75% cost reduction while maintaining or improving quality.
1. Make Your Prompts Pay Their Weight
Trim wasted tokens
Every word costs money.
Before (wasteful):
"I need you to summarize this article for me in a way that covers all the main points but is not too long and is understandable by an average person"
21 tokens, vague instructions, rambling output.
After (efficient):
"Summarize in 5 bullet points, simple language"
7 tokens, same result, 67% cheaper.

Figure 2. Token usage before vs after optimization.
Build a prompt library
Version control prompts, peer review them, A/B test for both quality and token count. One week optimizing your top 20 prompts can save thousands monthly.
Set max_tokens in API calls. If you need a short answer, cap it at 100 tokens. The model cannot ramble if you don't let it.
2. Stop Using a Ferrari to Deliver Pizza
Simple model routing
GPT-5 costs about 30x more than GPT-3.5 per token. Yet most teams use GPT-5 for everything.
Build a router. Simple concept, huge impact.
def route_query(prompt, complexity_score):
if complexity_score < 3:
return call_small_model(prompt) # $0.001 per 1K tokens
elif complexity_score < 7:
return call_medium_model(prompt) # $0.01 per 1K tokens
else:
return call_gpt5(prompt) # $0.03 per 1K tokens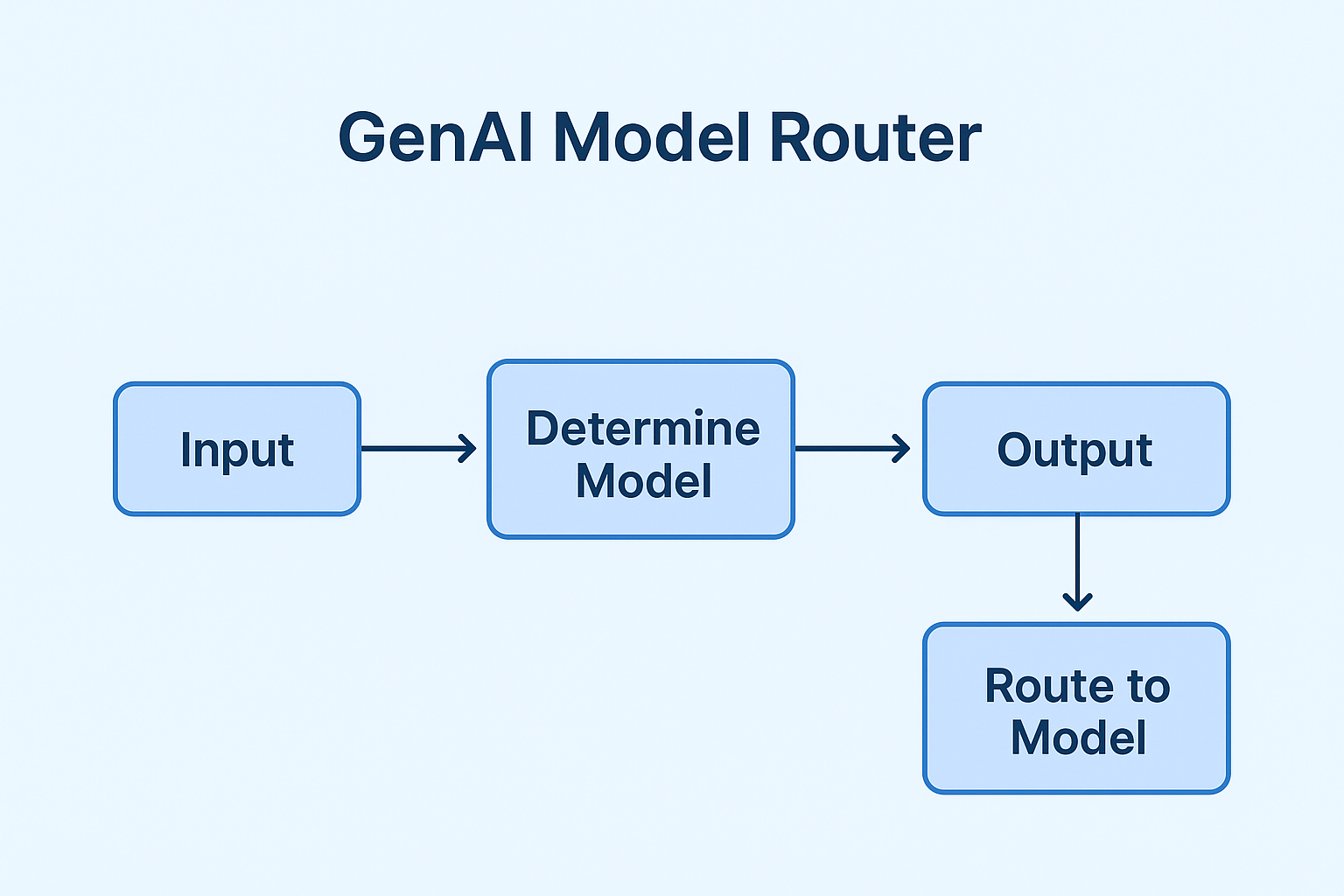
Figure 3. Simple GenAI Model Router.
How to measure complexity
Start simple:
- Word count under 50 → small model
- Asking for facts or extraction → small model
- Need creativity or reasoning → large model
Most apps find 70%+ of queries work fine with smaller models. Bills drop by 75% with no loss of quality.
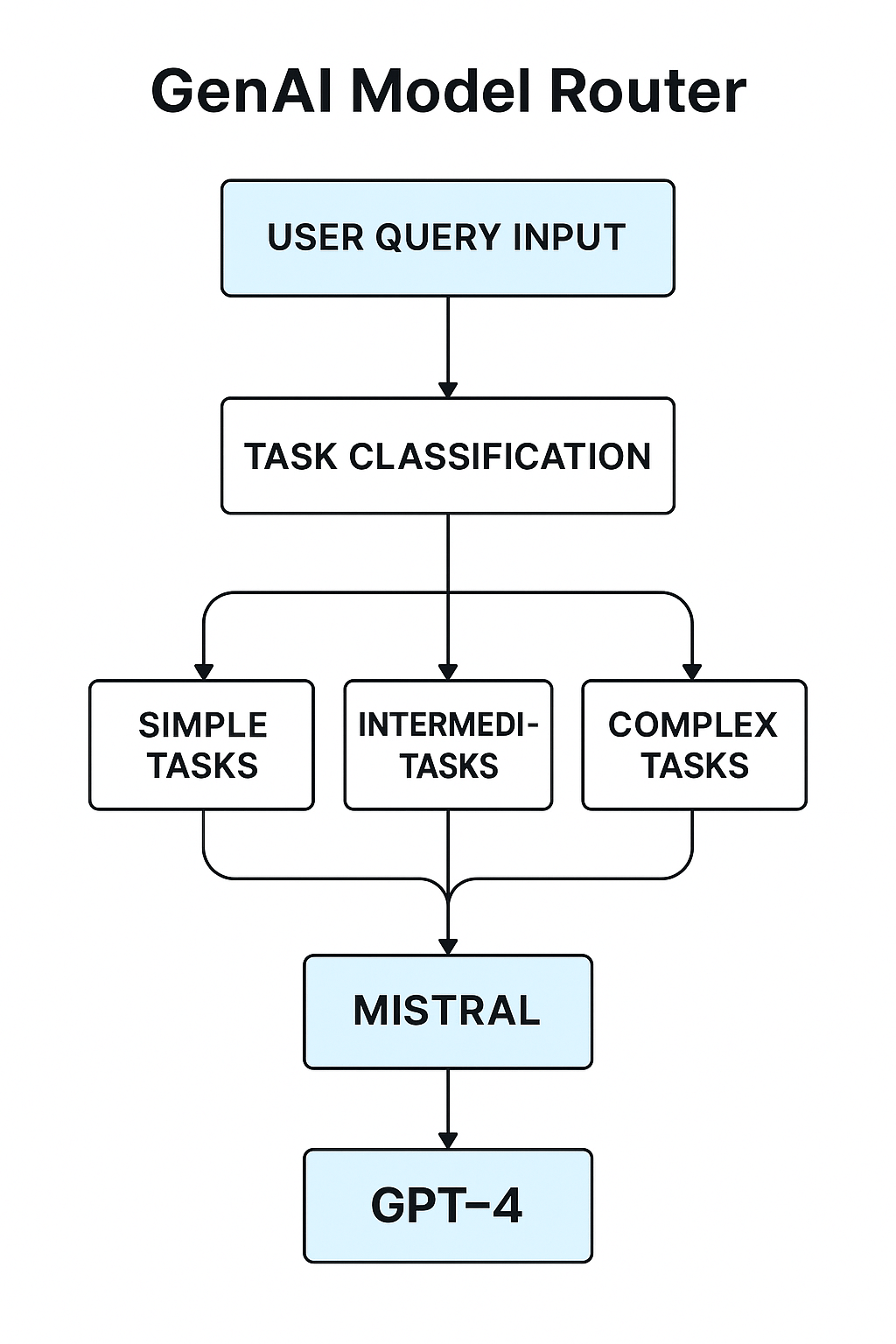
Figure 4. Routing diagram for classifying tasks.
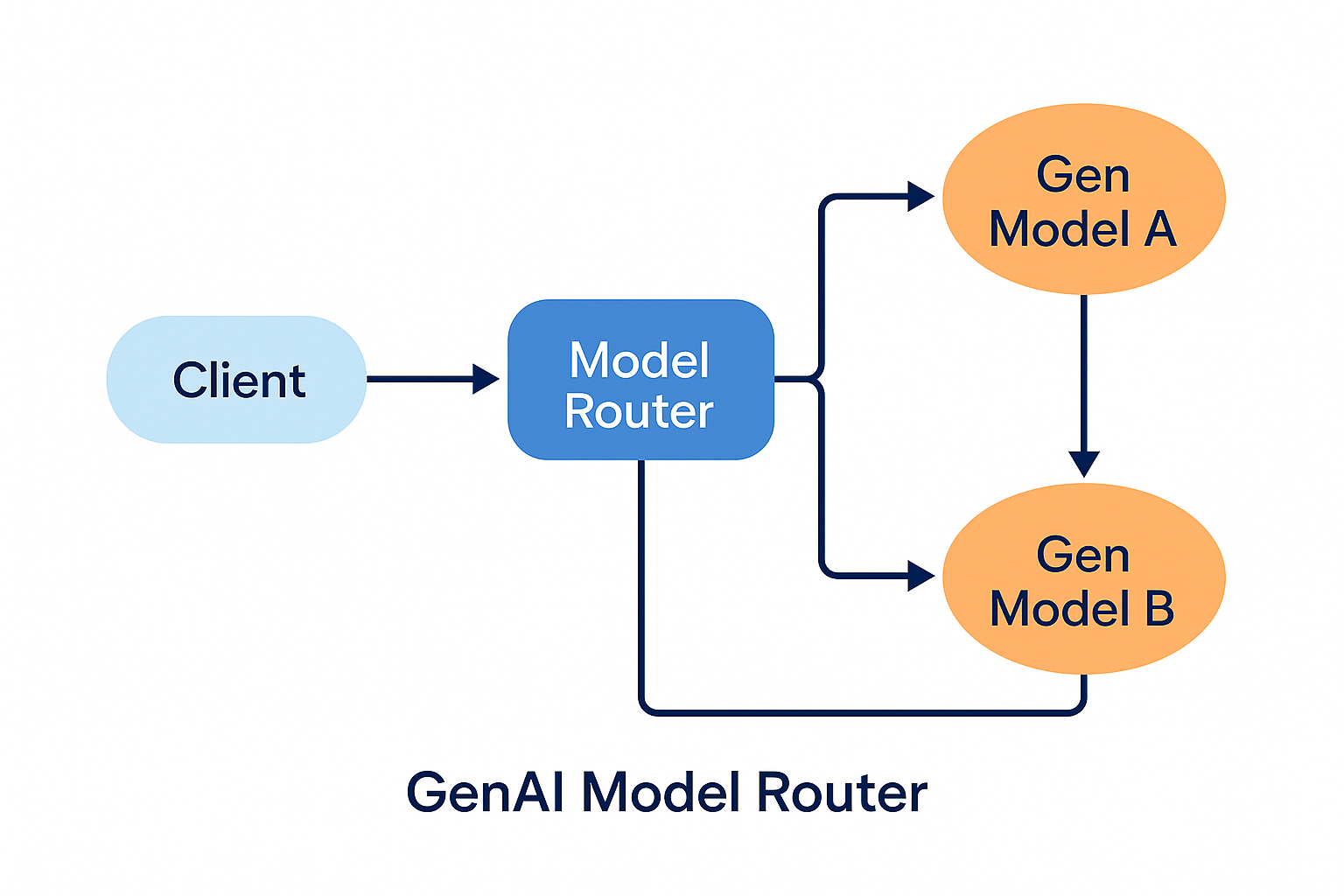
Figure 5. Router with fallback loop for failures.
3. Cache Like Your Budget Depends on It
Exact match caching
We waste thousands calling APIs for identical questions. "How do I reset my password?" doesn't need GPT-5 every time.
import hashlib
from diskcache import Cache
cache = Cache('./llm_cache')
def cached_llm_call(prompt, ttl=3600):
cache_key = hashlib.md5(prompt.encode()).hexdigest()
if cache_key in cache:
return cache[cache_key]
response = expensive_llm_api_call(prompt)
cache.set(cache_key, response, expire=ttl)
return responseSemantic caching
Go beyond exact matches. Use vector similarity to cache semantically similar queries:
- "What's the capital of France?"
- "France capital?"
- "Capital city of France?"
All same answer. One API call. Savings: 40–60% fewer calls.
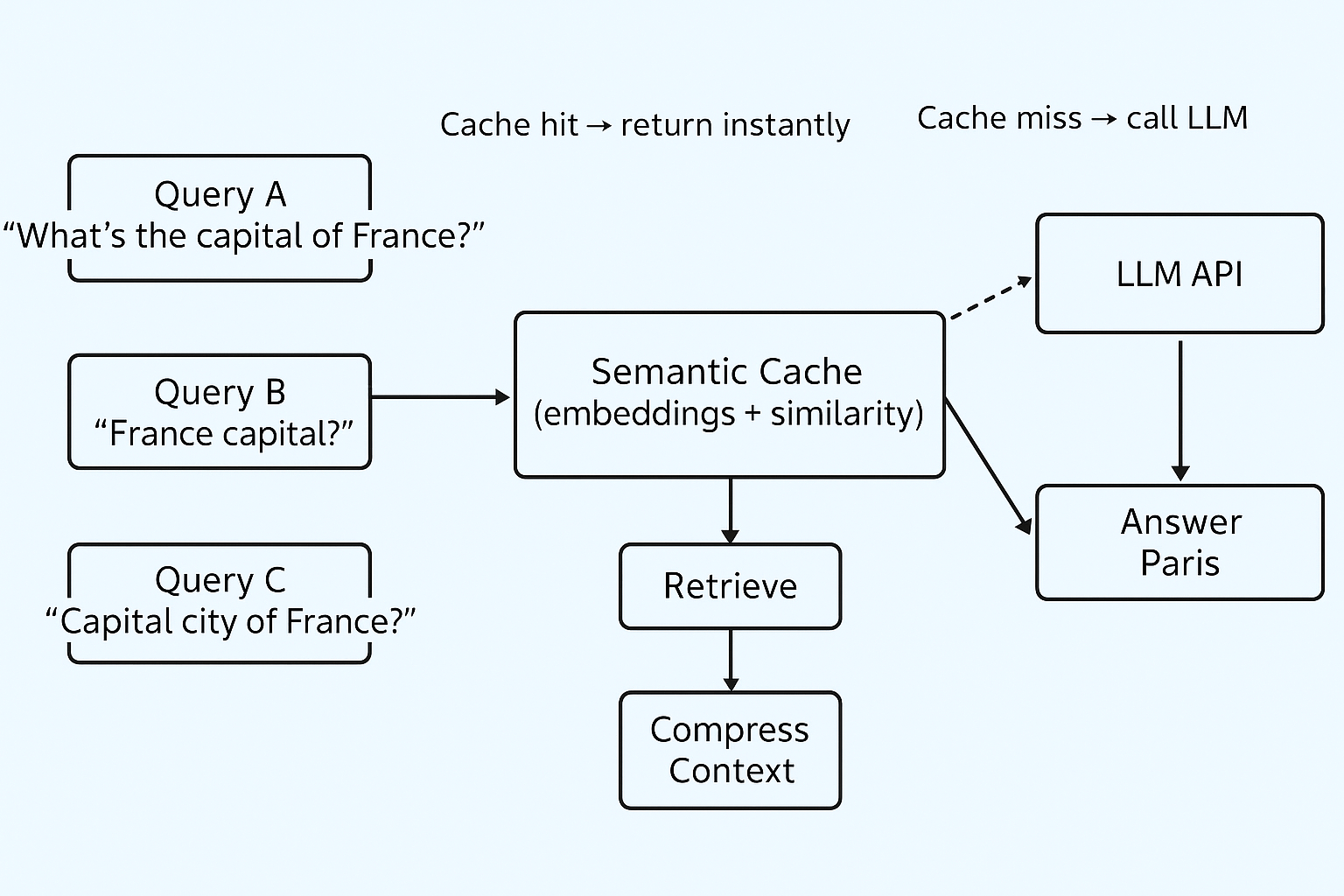
Figure 6. Semantic caching reduces redundant calls.
4. Fix Your RAG Pipeline Before It Bankrupts You
Cut tokens in context
RAG is powerful but costly if misused. Most teams dump entire docs into prompts.
Smarter pipeline:
- Chunk by paragraphs, not tokens
- Rank aggressively, keep top 3
- Summarize chunks before feeding model
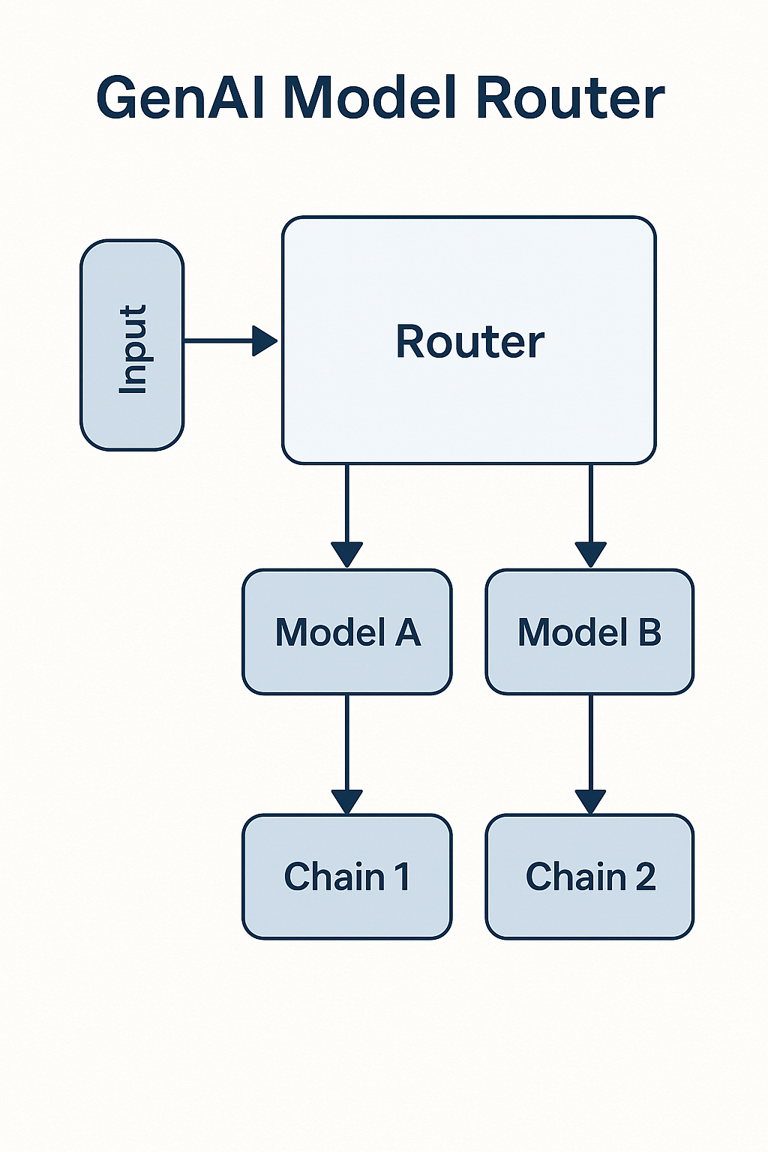 Figure 7. RAG orchestration pipeline.
Figure 7. RAG orchestration pipeline.
5. When All Else Fails, Go Custom
Fine-tune for your task
If you still bleed money after optimizing, consider fine-tuning and hosting.
- GPT-5 API: $0.03 per 1K tokens
- Self-hosted 7B: $0.0003 per 1K tokens
That's 100x cheaper. A tuned Mistral or Llama can match GPT-5 accuracy for specific tasks at 95% lower cost.
Beware Agentic AI Loops
Agentic AI adds planning and tool use. That power comes with cost risks. A single query can trigger a long chain of calls. Without guardrails, loops run until the budget is drained.
Guardrails to apply:
- Set a max step limit per agent run
- Log every tool call with tokens used
- Cap per-request spend so one runaway agent cannot burn the budget
Agents are valuable but must be supervised like interns with credit cards.
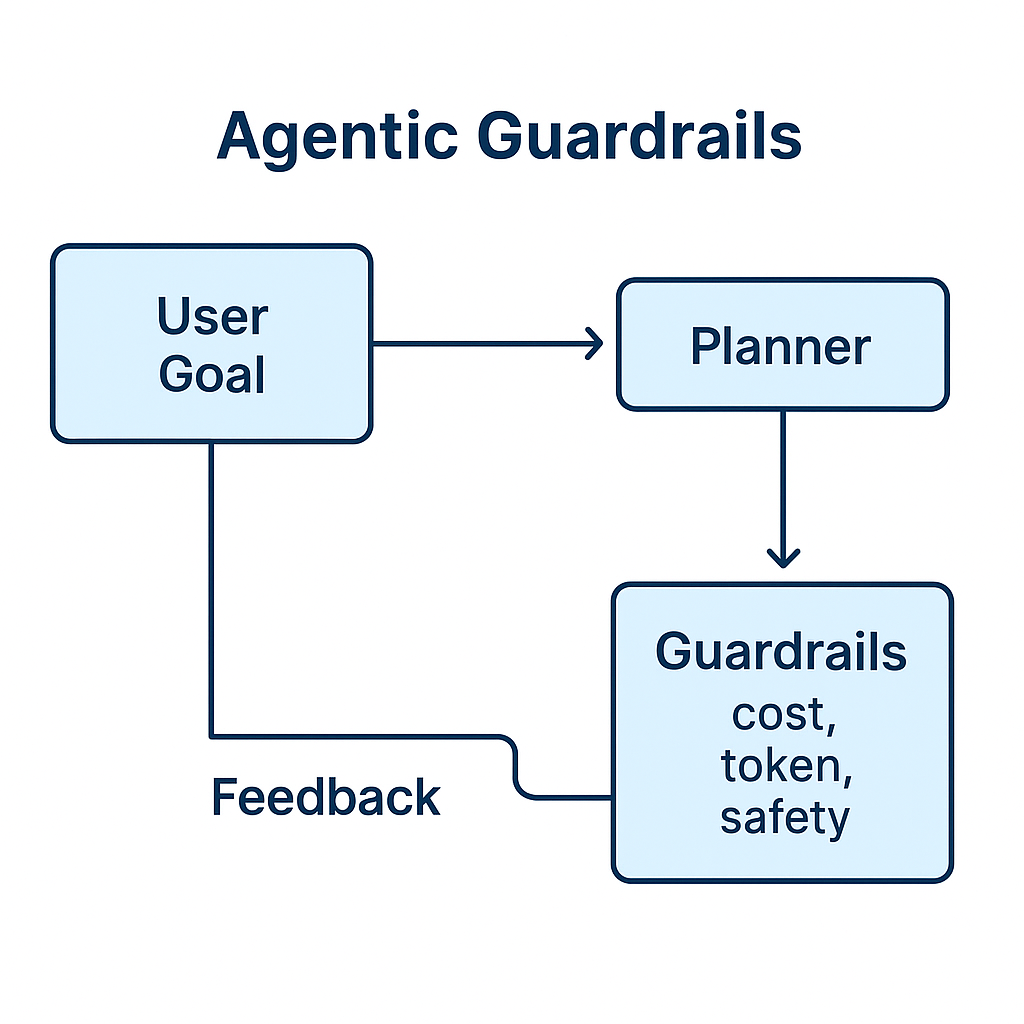
Figure 8. Guardrails for controlling Agentic AI loops.
DIY vs Managed Services
Managed APIs like OpenAI Assistants or Anthropic Console handle caching and memory automatically. They save engineering time but can cost more at scale.
DIY optimization takes effort but gives you fine-grained control. Most teams start managed for speed, then shift hybrid or DIY as costs grow.
Implementation Roadmap
- Log every API call with token counts and costs
- Identify top 10 most expensive prompts
- Add caching for repeat queries
- Build a model router
- Optimize your RAG pipeline if you use one
Pick the highest-impact optimization first. Measure, then iterate.
The Bottom Line
GenAI doesn't have to be a money pit. Companies that win treat tokens like a finite resource.
Every optimization compounds. A 30% reduction here, 40% there, suddenly you are running GenAI at 80% lower cost with better performance.
Start by benchmarking your monthly token spend. Apply one of these techniques. Measure again. Share your before-and-after results with the community.
Full implementation code, examples, and detailed guides available at github.com/cppraveen/genai-cost-optimization
Opinions expressed by DZone contributors are their own.
Comments