Data Privacy Engineering for AI Models: What Developers Need to Build In
A technical discipline that embeds data privacy protection into AI architectures across data ingestion, training, and model serving.
Join the DZone community and get the full member experience.
Join For FreeThe Privacy Problem in AI
Data privacy engineering is a critical requirement for modern Artificial Intelligence systems that operate on sensitive data. As AI systems are increasingly trained on sensitive and regulated data, data privacy has become an engineering concern
This article outlines architectural patterns and engineering practices that embed data privacy protection into AI workflows, from data ingestion to model serving, helping developers to design AI systems with data privacy protection
AI systems face privacy and security challenges, including vulnerabilities to cyberattacks and data breaches, which can compromise data privacy. As these systems increasingly rely on confidential information, securing them is a very critical responsibility. Organizations must adopt AI-specific safeguards across the lifecycle, such as data ingestion, training pipelines, preventing memorization and inference risks, and implementing access control tailored to AI systems. By integrating these measures, organizations can better protect the information and embed security and confidentiality into the architecture.
How Developers Can Implement AI-Specific Safeguards to Protect Sensitive Data
Data Ingestion Safeguards
Data ingestion is the process of collecting, transforming, and loading data from various sources into a data warehouse for AI/ML model training and analysis.
Protecting data after entering an AI system is essential to protect sensitive information. Developers should classify and label data to identify PII, financial records, and confidential information before ingestion. Data minimization ensures that the features required for the model are collected and reduces exposure risk. Sensitive identifiers can be protected through pseudonymization, a data de-identification method that replaces private information with pseudonyms, such as tokenization. Source validation ensures that only trusted data enters the pipeline. Finally, all raw data should be securely stored and form a strong foundation for privacy-aware AI systems.
Training Pipeline Safeguards
Securing AI system training pipelines requires layered threat mitigations that address vulnerabilities at each stage of the training lifecycle.
The training pipeline is the common source of unintended data exposure and must be secured. Developers should separate development, testing, and production pipelines to prevent unauthorized access to sensitive data, which is used for training models. To protect sensitive data, developers should implement least privilege access controls to limit data exposure to only specific roles that require access. Teams should apply privacy-preserving techniques and monitor overfitting actively for the models. In addition, audit logging processes and practices are essential without recording raw data, ensuring privacy is maintained throughout the training life cycle.
Model Design Safeguards
Model design safeguards are used to protect data privacy during AI model development to prevent models from learning, memorizing, and exposing sensitive data.
Model design plays a critical role in preventing unintended disclosure of sensitive data. Developers should apply regularization techniques to limit memorization of confidential data. Controlling output confidence helps reduce the risk of sensitive patterns that are being inferred from model responses. Care should be taken to avoid storing raw data within models, as these can become leakage points later. Teams should proactively test models against model inversion attacks to identify privacy risks before model deployment.
Model Serving and Inference Safeguards
Model serving is the process of deploying trained machine learning models to make predictions on new data that provide real-time predictions and ensure high availability for modern applications. Inference safeguards are security and content-filtering mechanisms that help ensure models operate securely and reliably during deployment.
Model serving is the stage where trained machine learning models are deployed to handle real-world requests. As the model will be exposed to users and systems, security and safety controls are critical at this stage.
Key model serving and inference safeguards include:
- Input validation and sanitization
- Strong authentication and access control
- Content moderation and output filtering
- Encryption (in transit and at rest)
- Logging and auditing
These safeguards protect the model from misuse and ensure secure, safe, and reliable operations.
Monitoring and Auditing Safeguards
Monitoring and auditing safeguards are security mechanisms used to protect data privacy, maintain model accuracy, and ensure regulatory compliance.
Monitoring safeguards focuses on the observation of system activity. They help to detect cyberattacks early, alert administrators when suspicious behavior occurs, and improve security through visibility. Monitoring also supports incident response by capturing evidence when events occur.
Auditing safeguards help to review past activities. They verify policy compliance and help to identify unauthorized data access, policy violations, configuration changes, and misuse of account privileges.
Both monitoring and auditing depend on proper logging, and best practices are centralizing log storage, defining retention policies, and protecting access.
Architecture Diagram
This diagram shows how privacy can be built into every step of an AI system. It starts with collecting and cleaning data, then securing it during training so that the model does not memorize the sensitive information. It also shows how the model that was deployed can be protected with access controls and encryption. Finally, monitoring and auditing ensure that any misuse or suspicious activities are detected quickly, helping organizations keep data safe and maintain user trustworthiness.
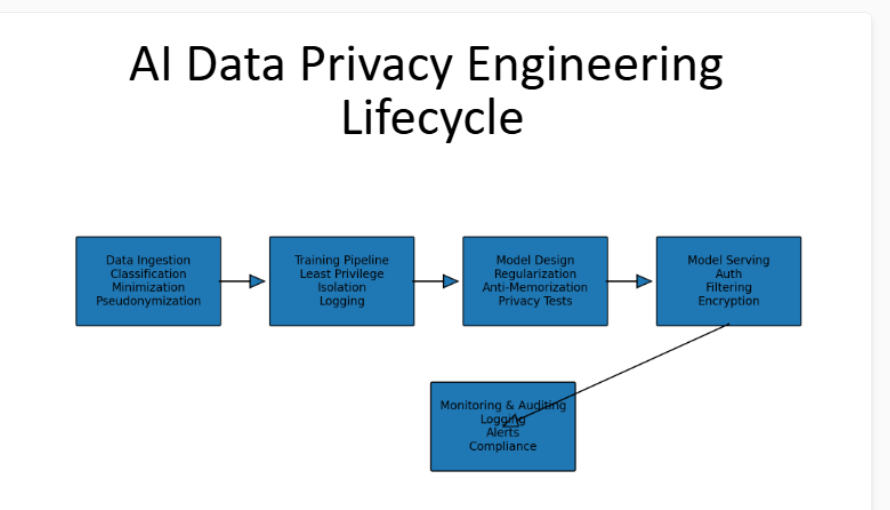
Data privacy engineering in AI must be added and built into the entire model lifecycle, from collecting data to executing the model in real time. Applying the above safeguards at every stage of the model lifecycle helps organizations prevent models from memorizing sensitive information, protect systems with access controls, and monitor and audit. These practices help developers reduce the risk of data misuse and data leakage.
Opinions expressed by DZone contributors are their own.
Comments