Data Tiering in SAP HANA Cloud-Native Storage Extension
Native Storage Extension - Warm data tiering in SAP HANA Cloud steps with screenshots taken while implementing at a customer
Join the DZone community and get the full member experience.
Join For FreeIn HANA Cloud, data can be stored in three categories. HOT, WARM, and COLD.
- HOT data is the data that resides in memory and is expensive.
- WARM data is the data that resides in the disk
- COLD data is the data that resides in a Data Lake.
In this article, we will explain how we can move data to a disk and what the steps are that need to be performed to be able to move data into the DISK.
Warm Data tiering in SAP is known as Native Storage Extension (NSE).
Native Storage Extension
Starting Point
- HANA Memory is expensive
- Most of the data in HANA Memory are not frequently accessed
- SLA to access non-frequent data is not rigid
Value Proposition
- Increase HANA data capacity at low TCO
- Deeply integrated warm data tier with full HANA functionality
- Will support all HANA data types and data models
- Scalable with good performance
NSE Sizing
- The HANA system must be scaled up
- Determine the volume of warm data to add to the HANA database
- May add as much warm storage as desired — up to a 1:4 ratio of HANA hot data in memory to warm data on disk
- Divide the volume of warm data by 8 — this is the size of the memory buffer cache required to manage warm data on the disk.
- Either add more HANA memory for the buffer cache or use some of the existing HANA memory for the buffer cache (which will reduce hot data volume).
- The work area should be the same size as hot data in memory (equivalent to HANA with no NSE)
Example
- Begin with a 2TB HANA system
- Database size: 1TB

Approach To Determine Data for Tiering
- Identify the top tables that are consuming the most memory
- The current state of the table (number of entries, state of the partition, memory size, etc.).
- Data Distribution Analysis for the fields that can be considered for partitioning.
- SQL plan cache analysis of last months to analyze the access patterns on the table.
- Data Temperature criteria for the selected tables.
- For example, one year of data will reside in the hot, and data that are older will reside in the warm store.
- Partitioning Strategy
Steps
Set Up Buffer Cache
First, set up the buffer cache depending on how much data you want to move to the disk. As explained above, it should be 1/8th of the data that needs to be moved to disk. In this case, we have taken the default value that is being set.
- Select ‘SAP HANA Cloud’ under ‘Instance and Subscription’ in the selected SubAccount

Click on the three dots.
![Click on the three dots.]() Select Open in SAP HANA Cockpit
Select Open in SAP HANA Cockpit
 Select Open in SAP HANA Cockpit
Select Open in SAP HANA Cockpit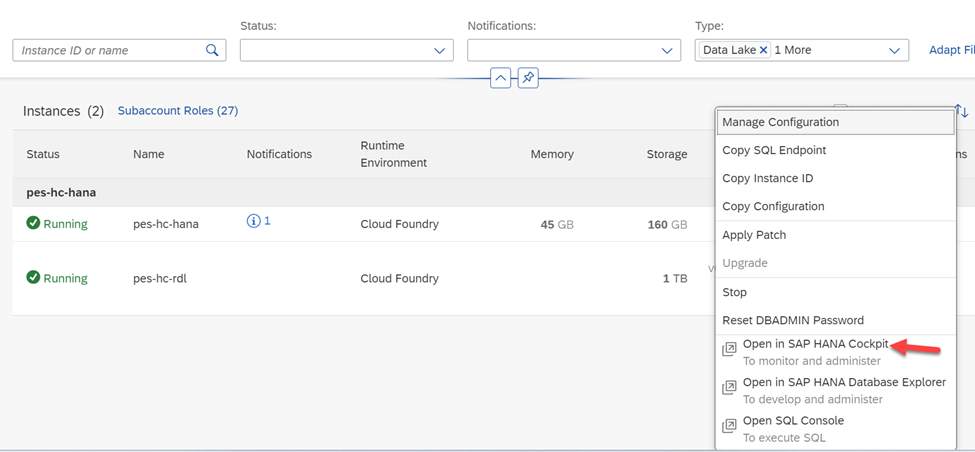
- Click on ‘Switch Application’ in the Cockpit and then select 'Buffer Cache Monitor'

- Click on ‘Configure Buffer Cache size’

- We have taken the default size. But the values can be changed in the below popup window.
![We have taken the default size. But the values can be changed in the below popup window.]() Identify the Table
Identify the Table
 Identify the Table
Identify the TableSince we don’t want production data for this exercise, we created a demo table and filled it with 100K records with a key that can be used for partition.
- Go to ‘Open SQL Console’

- In SQL Console, we created a table with three fields and filled it with 100k Records.
CREATE TABLE DEMO_NSE (
ID INTEGER,
NAME VARCHAR(10),
YEAR VARCHAR(4),
PRIMARY KEY (ID,YEAR)
);
CREATE PROCEDURE proc1 LANGUAGE SQLSCRIPT
AS
BEGIN
DECLARE a int = 100000;
DECLARE b int = 1;
DECLARE Name_var VARCHAR(10);
WHILE :b < :a DO
Name_var = CONCAT('NSE' , :b);
if :b < 30000 THEN
INSERT into DEMO_NSE VALUES(b,Name_var,'2019');
elseif :b >= 30000 and :b < 60000 THEN
INSERT into DEMO_NSE VALUES(b,Name_var,'2020');
else
INSERT into DEMO_NSE VALUES(b,Name_var,'2022');
END IF;
b = :b + 1;
END WHILE;
END;Check the Memory Usage of the Table
In this case, we will check if all the data in the table are HOT.
- In the HANA Cockpit, click on ‘Switch Application’ and then ‘Current table Distribution’ from the drop-down.
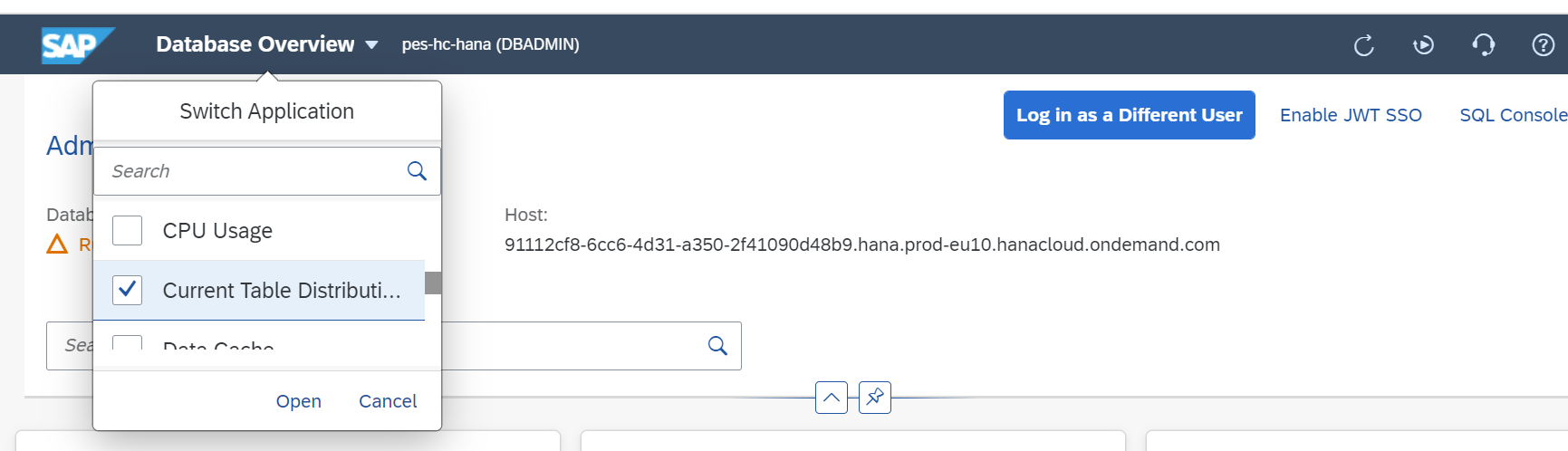
- Search and then select the table.
As seen below, the whole table is in the LOADED state, which means its all HOT.

Partition the Table
After confirming that all the data is HOT, we partition the table so that we can move the partitions that are old to the DISK. In this case, we will partition the table by the field YEAR.

Select the ‘Range’ tab and then select the field on which you intend to partition the table. In this scenario, we will partition by YEAR.
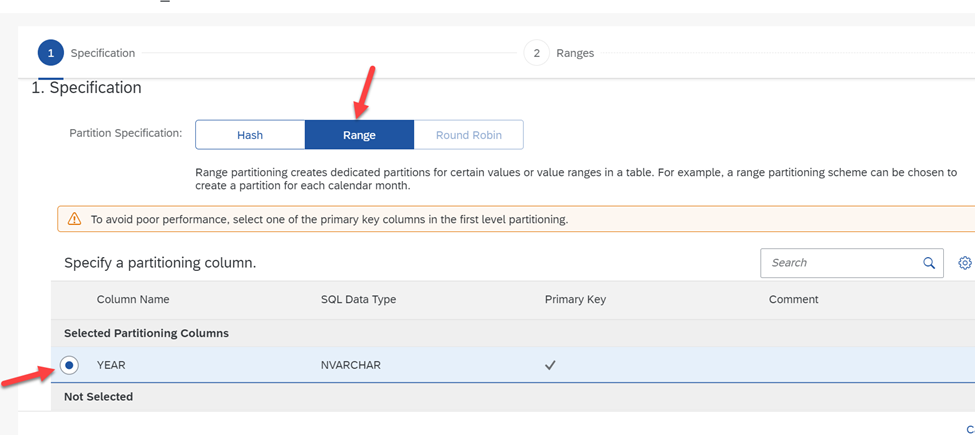
Click on ‘Add Partition Range’ and create three partitions for the years 2019, 2020 and 2022. Partition ‘Others’ is always added by the application to collect data that are not in the partitions created.
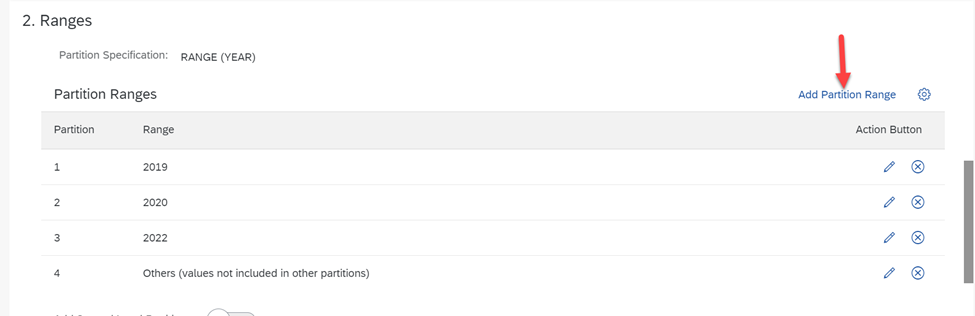
After the partitions are created, the table view changes. Click on the partition to see the details:

Load the Partitions to the Disk
Now, we will move two partitions to the DISK by offloading the partitions from memory to disk.
This step can be achieved through the tool, or you can run some scripts to upload the partitions from memory to disk.
Run the below scripts in the SQL Console to unload the partitions 2019 and 2020 from Memory.
ALTER TABLE DEMO_NSE ALTER PARTITION RANGE ("YEAR")
((PARTITION VALUE = '2019')) PAGE LOADABLE;
ALTER TABLE DEMO_NSE ALTER PARTITION RANGE ("YEAR")
((PARTITION VALUE = '2020')) PAGE LOADABLE;Check the Memory
After offloading the partitions from memory, we will check if the partitions are offloaded from memory to disk.
As seen, the table is now partially loaded, which means some of the data is not in memory. We know that we offloaded two partitions.

To know detailed statistics of the partitions that are offloaded from memory, execute the below query:
SELECT
TC.table_name,
TC.part_id,
LPAD(TO_DECIMAL((TC.MEMORY_SIZE_IN_TOTAL - TC.MEMORY_SIZE_IN_PAGE_LOADABLE_MAIN)/1024/1024,10,2),7) as MEMORY_MAIN_MB_TABLE_LEVEL,
LPAD(TO_DECIMAL((TC.MEMORY_SIZE_IN_PAGE_LOADABLE_MAIN)/1024/1024,10,2),7) as MEMORY_PAGE_MB_TABLE_LEVEL,
LPAD(TO_DECIMAL((TC.ESTIMATED_MAX_MEMORY_SIZE_IN_TOTAL)/1024/1024,10,2),7) as ESTIMATED_MAX_MEMORY_MB_TABLE_LEVEL,
LPAD(TO_DECIMAL((TD.DISK_SIZE)/1024/1024,10,2),7) as DISK_SIZE_MB_TABLE_LEVEL,
TC.load_unit
FROM M_CS_TABLES TC
INNER JOIN M_TABLE_PERSISTENCE_LOCATION_STATISTICS TD on TC.part_id = TD.part_id
AND TC.schema_name = TD.schema_name
AND TC.table_name = TD.table_name
WHERE TC.table_name in ('DEMO_NSE') ;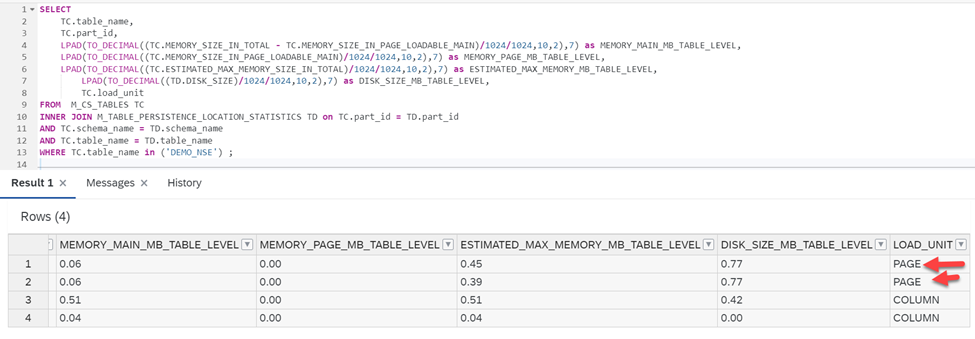
As seen above, the two partitions that we offloaded from memory are now paged and are residing in the disk.
Opinions expressed by DZone contributors are their own.
Comments