Database Replication: Open-Source Tools and Options
Business systems generate large amounts of data, needing tools to manage it. Learn open-source tools for DB and stream-based replication for real-time.
Join the DZone community and get the full member experience.
Join For FreeFor the past few years, business systems have been generating large amounts of data and need tools to manage the data. One of the business requirements was to copy the primary data to secondary databases. Several popular tools are available in the market to replicate the data from master DB to secondary DB. This article will discuss various open-source tools for DB replication and stream-based replication for real-time.
Replication is the process of sharing/storing information in multiple places to ensure reliability, fault tolerance, and accessibility. The replication options are described as follows:
- Active/active replication
- Active/passive replication
Database replication is supported by many RDBMS (Relational Data Base Management Systems) to copy the data from primary to secondary DB systems. Database replication is complex for active/active replication, especially for systems that use horizontal scaling capabilities. Database replication is depicted in Figure 1, where write and read operations for a web/enterprise application are different. The replication system would be synced with the primary DB all the time. CAP (Consistency, Availability, and Partition tolerance) would be considered during the database replication process to avoid data replication issues.
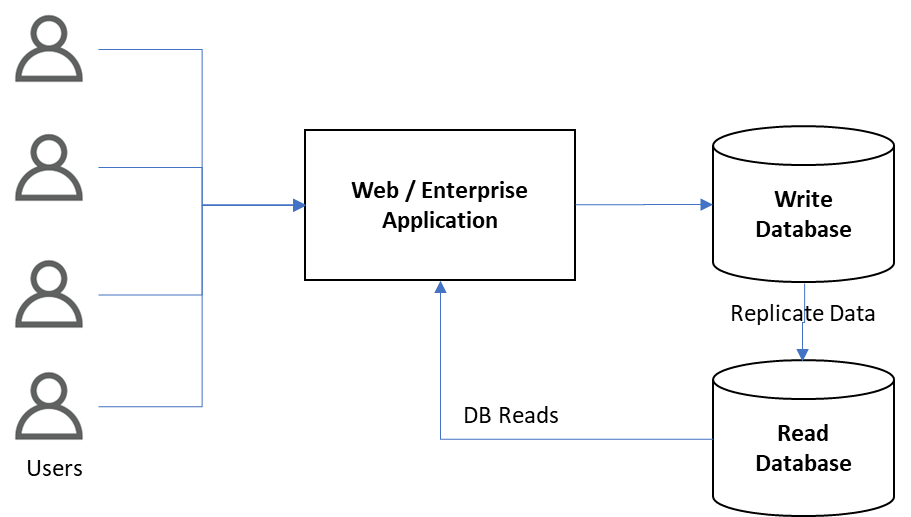
Figure 1: Replicating data for separate read operations for web/enterprise application
Data replication is critical for enterprise systems to maintain data in multiple nodes across the network for data availability. Key aspects include the following:
- Data availability in multiple places
- Reliability of data between nodes
- Data redundancy
- Data recovery if any corruption or loss of data
Open-Source Data Replication Tools
Many organizations prefer open-source tools for data migration based on their business needs. There are various commercial and open-source tools available for data migration. This article talks about four tools that have been popular in the open-source market for the last couple of years.
ReplicaDB
This is the most popular open-source data replication tool for transferring bulk data from relational to relational/NoSQL databases. It offloads the ETL activities. Currently, supported databases are:
- Oracle
- Postgres
- SQL Server
- MySQL
- MariaDB
- Denodo
- CSV on local files or Amazon S3
- Kafka
ReplicaDB is a command line tool that can support any platform. ReplicaDB is not supported by streaming data coming from systems like Kafka.
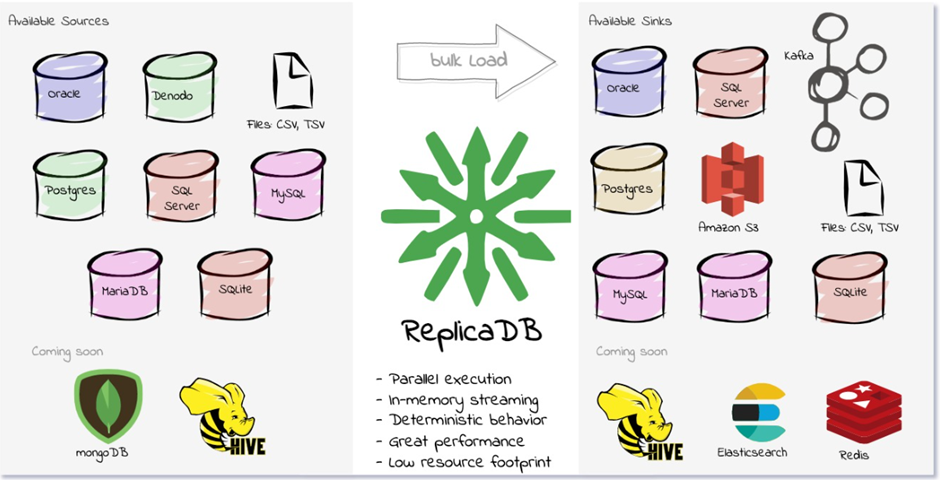
Figure 2: Image Source - ReplicaDB on GitHub
SymmetricDS
This open-source replication tool for databases supports features such as filtered synchronization, multi-master replication, and transformation capabilities. It is compactable with many databases and replicates data across different platforms. With SymmetricDS, sync from DB to DB in a heterogeneous manner. Table and column level sync configuration is available. Data migration is in one/multi-direction. High-level architecture is depicted in Figure 3.
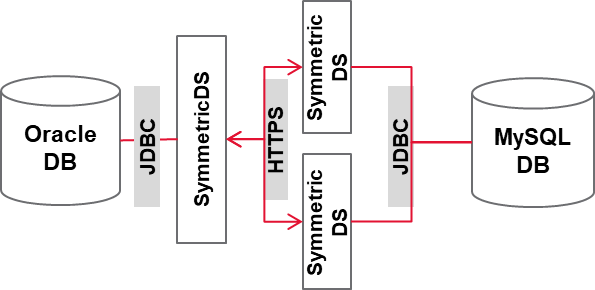
Figure 3: Data replication using SymmetricDS from Oracle to MySQL
Other features include the capability of transaction aware feature, where changes are recorded and played back. In multi-master replication, conflicts are detected and resolved automatically. Communication uses push/pull.
Talend
Use the open-source replication tool from Talend to integrate data sources into clean and complete. More than 1000+ connectors are available to connect any data sources in the cloud or on-premise. Easily develop a data pipeline using GUI interface by drag and drop feature. The Spark platform is used internally to support massive data replication with no timeline. Talend partners with major vendors including Amazon, Azure, and Google for data replication solutions. Talend was named the 2022 Gartner Magic Quadrant for Data Integration Tools. Commercial versions are also available for data replication.
Replicating Using Kafka
Currently, most applications are moving towards real-time processing architectures using Kafka. For this reason, the data resides in a streaming platform and there is a need to replicate the data from the streaming platform to DB/NoSQL/other systems. Use the Apache Kafka and Kafka Connector framework to replicate data from source DB to target/destination DBs. Figure 4 provides the high-level architecture.
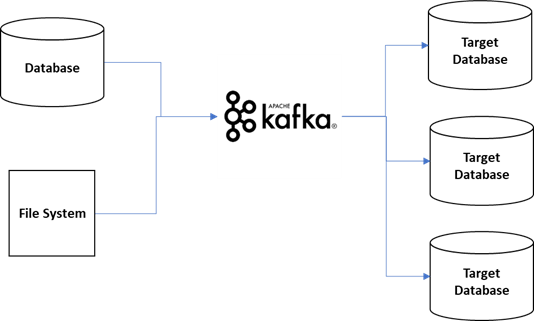
Figure 4: Apache Kafka and Kafka Connector between data replication
High-level process steps are as below:
- Enables change data capture (CDC) on source database tables to replicate
- Kafka DB Connector to read CDC from source DB and pushes to data to Kafka topic
- JDBC sink connector: push/pull data from Kafka topics from source/destination databases (table-wise configuration)
Conclusion
Hopefully, you conclude the article with an understanding of data replication and the open-source tools used for data replication. Application uses can make decisions based on the business need for data replications, either commercial or open source. Along with the tools, we have depicted the database replication using streaming platforms along with sink connectors for data replication between different databases.
Opinions expressed by DZone contributors are their own.
Comments