Database vs. Data Science
Join the DZone community and get the full member experience.
Join For Free One thing that Big Data certainly made happen is that it brought the
database/infrastructure community and the data
analysis/statistics/machine learning communities closer together. As
always, each community had it’s own set of models, methods, and ideas
about how to structure and interpret the world. You can still tell these
differences when looking at current Big Data projects, and I think it’s
important to be aware of the distinctions in order to better understand
the relationships between different projects.
One thing that Big Data certainly made happen is that it brought the
database/infrastructure community and the data
analysis/statistics/machine learning communities closer together. As
always, each community had it’s own set of models, methods, and ideas
about how to structure and interpret the world. You can still tell these
differences when looking at current Big Data projects, and I think it’s
important to be aware of the distinctions in order to better understand
the relationships between different projects.
Because, let’s face it, every project claims to re-invent Big Data. Hadoop and MapReduce being something like the founding fathers of Big Data, other’s projects have since appeared. Most notably, there are stream processing projects like Twitter’s Storm who move from batch-oriented processing to event-based processing which is more suited for real-time, low-latency processing. Spark is yet something different, a bit like Hadoop, but puts greater emphasis on iterative algorithms, and in-memory processing to achieve that landmark “100x faster than Hadoop” every current project seems to need to sport. Twitter’s summingbird project tries to bridge the gap between MapReduce and stream processing by providing us with a high-level set of operators which can then either run on MapReduce or Storm.
However, both Spark or summingbird leave me sort of flat because you can see that they come from a database background, which means that there will still be a considerable gap to serious machine learning.
So, what exactly is the difference? In the end, it’s the difference between relational and linear algebra. In the database world, you model relationships between objects, which you encode in tables, and foreign keys to link up entries between different tables. Probably the most important insight of the database world was to develop a query language, a declarative description of what you want to extract from your database, leaving the optimization of the query and the exact details of how to perform them efficiently to the database guys.
The machine learning community, on the other hand, has its roots in linear algebra and probability theory. Objects are usually encoded as a feature vector, that is, a list of numbers describing different properties of an object. Data is often collected in matrices where each row corresponds to an object, and each column to a feature, not much unlike a table in a database.
However, the operations you perform in order to do data analysis are
quite different from the data base world. Take something as basic as
linear regression: your try to learn a linear function f(x)=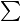 di=1wixi in a d-dimensional space (that is, where your objects are described by a d-dimensional vector) given n examples Xi, and Yi, where Xi are the features describing your objects and Yi is the real number you attach to Xi. One way to “learn” w is to tune it such that the quadratic error on the training examples is minimal. The solution can be written in closed form as
di=1wixi in a d-dimensional space (that is, where your objects are described by a d-dimensional vector) given n examples Xi, and Yi, where Xi are the features describing your objects and Yi is the real number you attach to Xi. One way to “learn” w is to tune it such that the quadratic error on the training examples is minimal. The solution can be written in closed form as
In order to solve this, you need to solve the linear equation (XXT)w=XY which can be done by one of a large number of algorithms, starting with Gaussian elimination, which you’ve probably learned in your undergrad studies, or the conjugate gradient algorithm, or by first computing a Cholesky decomposition. All of these algorithms have in common that they are iterative. They go through a number of operations, for example O(d3) for the Gaussian elimination case. They also need to store intermediate results. Gaussian elimination and Cholesky decomposition have rather elementary operations acting on individual entries, while the conjugate gradient algorithm performs a matrix-vector multiplication in each iteration.
Most importantly, these algorithms can only be expressed very badly in SQL! It’s certainly not impossible, but you’d need to store your data in much different ways than you would in idiomatic database usage.
So, it’s not about whether or not your framework can support iterative algorithms without significant latency, it’s about understanding that joins, group bys, and count() won’t get you far, but you need scalar products, matrix-vector and matrix-matrix multiplications. You don’t need indices for most ML algorithms, maybe except for being able to quickly find the k-nearest neighbors, because most algorithms tend to either take in the whole data set in each iteration or otherwise stream the whole set by some model which is iteratively updated like in stochastic gradient descent. I’m not sure projects like Spark or Stratosphere have fully grasped the significance of this yet.
Database infrastructure-inspired Big Data has it’s place when it comes to extracting and preprocessing data, but eventually, you move from database land to machine learning land, which invariably means linear algebra land (or probability theory land, which often also reduces to linear algebra like computations). What often happens today is that you either painstakingly have to break down your linear algebra into MapReduce jobs, or you actively look for algorithms which fit the database view better.
I think we’re still at the beginning of what is possible. Or, to be a bit more aggressive, claims that existing (infrastructure, database, parallelism inspired) frameworks provide you with sophistic data analytics are widely exaggerated. They take care of a very important problem by giving you a reliable infrastructure to scale your data analysis code, but there’s still a lot of work that needs to be done on your side. High-level DSLs like Apache Hive or Pig are a first step in this direction but still too much rooted in the database world IMHO.
In summary, one should be aware of the difference between a framework which mostly is concerned with scaling and a tool which actually provides some piece of data analysis. And even if it comes with basic database-like analytics mechanisms, there is still a long way to go to do some serious data science.
That’s why we’re also thinking that streamdrill occupies an interesting spot, because it is a bit of infrastructure, allowing you to process a serious amount of event data, but it also provides valuable analysis based on algorithms you wouldn’t want to implement yourself, even if you had some Big Data framework like Hadoop at hand. That’s an interesting direction I also would like to see more of in the future.
Note: Just saw that Spark has a logistic regression example on their landing page. Well, doing matrix operations explicitly via map() on collections doesn’t count in my view ;)
Published at DZone with permission of Mikio Braun. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments