Denodo Data Virtualization — Interview
Ever heard of data virtualization? Read this interview to find out more about what it is.
Join the DZone community and get the full member experience.
Join For FreeHeard of Data Virtualization? It’s beginning to be one of the hottest trends in Integration right now. It offers the possibility to expose any data from any source to any consumer. Denodo, a DV Provider solution located at Palo Alto, is one of the fastest growing providers. I recently had the chance to interview Olivier Tijou, Country Director at Denodo Technologies.
Hello Olivier Tijou. Can you tell us what the Denodo solution is?
Denodo Platform for Data Virtualization (DV) is a data delivery software, one of the fastest and most cost-effective ones. Data Virtualization acts as an enterprise universal database (natively APIfied) used for decisional and operational needs, but contains no data! Whenever requested, Denodo Platform for DV will find the right information for you through your enterprise data (on-premise or Cloud) and deliver the result to you in a very performant way without replicating or pushing the original data structure or complexity. As it is an enterprise Data Layer, companies can reinforce their security and access their data as well as put compliance rules in place without reducing the agility they are providing to IT and business users.

What are the main use cases for which Denodo responds best?
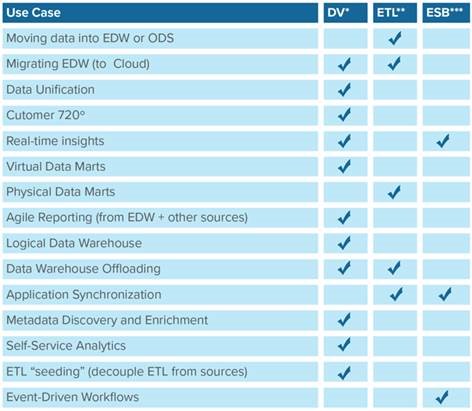
Data Virtualization use cases reside in any operational or decisional needs:
- Companies who have, on one hand, more than one database/source of data: companies that have multiple ERPs, databases, big data, multiple data marts, “unlimited” ETL flows, scripts and scheduler, much replication, acquisition growth, disparity of technologies and application ages, a mix between on-premise and off-premise data, adoption of SaaS application, etc.
- Companies who need fast access to data, potentially with a mix/merge/transform/enhancement/enrichment between multiple sources, applications, structures, formats, and origin of data.
So, historically, in order to cover previous use cases, and even if industrialized as much as we can, the approach would be through scripts/scheduler, launching ETL (Extract, Transform and Load) flows that will get data from one/multiple systems, do the right transformation before replicating/storing the data in a new container (Database/Data warehouse) in the format and structure requested by end users. On top of that, directly to the source, or through the intermediate/replicated data source, we install, create, and deploy ESB like a solution in order to expose the data into Web Services or API. You find yourself with multiple products, a complex enough architecture, a combined and detailed alignment between teams, very IT oriented tasks with direct impacts if any modification is done, and very small visibility on the origin of data. Let’s add on top of that what TDWI 2016 study mentioned; that 75% of stored data is not used (because of much replication), and 90% of end-user needs reside in source/real-time data (meaning that not only replicated data is not used, but also the data that can be used, because of today's real-time needs, doesn’t cover business needs).
Data Virtualization (and Denodo as leader and pioneer in DV) brings the fastest data delivery layer with a cost-effective approach: there is no data replication if it is not necessary. In one product, you can cover:
- Connecting to existing systems and applications, introspecting its content, and retrieving only data description, in order to play with it, transform it, and enhance it.
- Any Data virtualization “view” (standard or enhanced) is automatically consumable through database-like (odbc, jdbc) or APIs (Web Service, Rest/Json, Odata).
- Performance, Performance, Performance: Query optimizer (re-writing), multiple algorithms of execution, caching, and parallel execution.
In addition, as an enterprise data layer, Denodo platform has additional capabilities related to self-service, separation of duty, governance, and security:
- Through Data Catalog, an end-user (if authorized) can search for a specific attribute (let’s says total revenue), will automatically find all the views containing that aforementioned attribute, the graphical view also showing its origin, and what the transformation/enhancement (called data lineage) is. Denodo Data Catalog also allows you to search the content of data
- As a data layer is becoming the preferred enterprise access, Data virtualization is used for putting in place security rules, profiles/roles controls, filtering, masking, encrypting, authorization, etc., allowing companies to reinforce their governance, security and compliancy without impacting the agility in accessing data
Related topics where DV brings additional value: #analytics #predictive #bigData #EDW #BI #SelfService #DaaS #dataCatalog #enterpriseSearch #chatBot #dataExposition #Governance #GDPR #compliancies #goToTheCloud #Migration #dataMicroService #digital #dataForDigital #(Data)devOps #APIsInMinutes #360° #M&A #masterData #reporting #analyse #predictiveAnalytics #IoT #machineLearning #artificalInteligence #cloudApps #hybridDataFabric #dataHub #enterpriseDataLayer #files #mails #(un)structuredData #ETL #ESB #middleware #ingestion #connectors #dataDrivenCompany #dataAcquisition #anyConsolidatedViews
How can Denodo help enable what is referred to as “Hybrid Integration?”
Hybrid data platform or Hybrid data fabric is increasingly used by our customers.
In a hybrid environment, there is coverage at multiple levels:
- Source data (southbound): data can be located in internal or external systems, on premise or in the cloud, as a controlled application or fully managed (or SaaS). Denodo Platform allows to connect to any source of data, though connectors/adapters/APIs… and do the same “virtual” presentation of it inside Denodo for graphical, agile manipulation of (meta)data removing the complexity or the source of the data. As an example: “what is the generated revenue of a marketing event for a specific region for last 3 years:” DV allows to easily retrieve data from Salesforce (marketing — in the Cloud), BigData (point of sales tickets — on premises), Oracle (Customer data — managed services seen as on-premise) and provide a “logical table” (or API as described above)
- Consumer (northbound): Consumers can be analysis, reports, machine learning, AI, CRM, ESB, ERPs, Web apps, Mobile apps… any type of consumer apps that can be available in the Cloud or on-premise. All will inherit the same governance and security levels, whatever the chosen consumption channel. As an example, the previous request “what is the generated revenue of a marketing event for a specific region for last 3 years” is consumed by a data visualization tool (like Tableau) used in an on-premise approach, as well as a predictive/statistic algorithm part of the Data Lake strategy deployed on AWS (or Azure).
- For compliance, data control, data (geographic) location, confidentiality, level of certification, personal information, etc.: some critical/specific data can be stored only on-premise, giving access to external users/apps that will only use the data for calculation (and not store it as it is). As an example, in the previous “predictive/statistic algorithm part of the Data Lake strategy deployed on AWS (or Azure),” it is retrieving multiple information, in which the objective is to create “a sales vs marketing vs region scoring over 3 continents.” Only this information will be stored as a result in the Cloud as a continent name (or just ID) and a score (a number) related to it.
- Go to the cloud movement is also one of the hybrid use cases where multiple sources are consolidated into one for easier, faster, and cleaner exposition of data and migration. As an example, a company growing through acquisitions or a decentralized company with multiple business units decided to elect an enterprise (group) CRM like Salesforce. It can use Denodo Platform for DV in order to standardize the view of a customer, connect to multiple (internal/external sources) existing CRMs, databases, (sometimes Access or Excel), and give the right access in a language known by Salesforce as Rest API or Odata.
- Denodo itself can run on-premise or in the cloud, which allows Denodo users to chose their consumption way, following enterprise strategy as cloud first, or inherit some agility from IaaS platform (on or off premises). This also allows to have multiple Denodo platforms that can be on and off premises with a shared governance but not shared assets and sources of data. This allows Denodo users to add some bandwith, volumes, numbers of records, requests, etc that can transit in or out; as an example for cost control if data going out from the cloud or number of request, has a price per call, MB, etc.
What do you say to those who tell you that Data Virtualization does the same job as an ESB?
In a few words, ESB (Enterprise Service Bus) and DV complement each other. Some elements covered by DV are better done in DV and it is the same for ESB. An overlap exists (as between DV and ETL), but it is done in the fastest way with DV (and especially in a more cost-effective way when you think about build, run, day 2 in production, upgrades, separation/abstraction, etc.
In more detail:
- First of all, DV covers decisional and operational needs where ESB is very operation needs oriented
- ESB is also event oriented for synchronizing apps upon an event, where DV is on top of that on-demand real-time too, data consumption oriented
- As a referential architecture, and in order to avoid having one connector for each application, and as DV can work for decisional and operational needs, DV will act as a “super connector” for ESB, where you can change source applications without impacting your ESB orchestration/mediation or API exposition
- DV and ESB can both expose data sources into APIs. Denodo automatically exposes any “virtual view” in Web Services, Rest/JSON, and OData, where you need to do each of those in an ESB approach
- If any “virtual view” (and so API) is modified, there is a complete view of impacts (upstream: who is using it & what are the impacts of the modification, and apply the right versioning strategy — downstream: have a complete lineage of used data and sources)
- APIs exposed by DV should be a preferred approach (see it as your microservices creation), and then, with ESB, orchestrate/mediate those APIs in order to create conditional, more complex APIs, based on the original ones. All APIs (DV or ESB) would be ingested in API Management solutions (like Apigee, Mule, 3scale, Layer7, and Axway)
- Other than HTTP APIs, ESB and DV can also communicate via messaging systems (as an example via JMS)
(You can find a complete study here.
You have strong growth, can you tell us more?
“25% of Fortune 1000 use Data Virtualization extensively” — Gartner Predicts 2017: Data Distribution and Complexity Drive Information Infrastructure Modernization”
“Through 2020, 50% of enterprises will implement some form of data virtualization as one enterprise production option for data integration” — Gartner 2017 “Market Guide for Data Virtualization”
This is also supported by the maturity of DV and also by the fact that Denodo is a pure player in Data Virtualization for over 18 years.

Denodo is a profitable private company and has a 50+% annual growth. In 2017, Denodo opened APAC and French EMEA region branches to follow its growth with a great number of opening positions. Denodo is a data virtualization pure player and pioneer in his domain of expertise with 500+ ACTIVE customers, recognized by analysts and customers ensuring our strong growth in different verticals and markets.

Is there an interest in using Denodo's data virtualization in a Big Data/Data Lake context?
The logical data lake is one of the hottest topics within Denodo users/clients and ecosystem as there is a complete complementarity between DV and Data Fabric based on Hadoop solution: DV doesn’t store data, while big data solutions are very strong & mature.
DV increases the usage of data lake by putting in place what is called the “multi-purpose data lake” by solving the following: The original data lake’s architecture has two severe drawbacks. One relates to the physical nature of the data lake, which may kill the big data project entirely because it can be “too big” to copy to a central environment. The other relates to the restricted use of the data lake investment — it’s designed exclusively for data scientists.
Here are the main elements of complementarity:
- Denodo is certified by Hortonworks and Cloudera (others to come)
- Data Lake and DV: from Denodo's perspective
- Southbound as a source of data: Often, the data lake manages to receive big volumes of data, allowing data scientists to extract insights and value from it through algorithms, statistics, machine learning, etc. Data scientists results are stored and put as available “enhanced valuable” data within the data lake. Like any other source of enterprise data, this result can be easily used as input, mixed/enriched with other sources of data in order to maximize data consumption. As an example, the data lake massively receives all tickets from POS (point of sales) from shops, data scientists can calculate a related scoring with influence indexation through geographic location (with data already in the data lake). Pricing team can consume this data with manipulation of information coming also from pricing tools (can be Excel files).
- Northbound as a consumer of data not (yet) in the data lake: even though the final objective of the data lake is to contain all (or maximum) of the data, whatever the format or volume, all enterprise data are not (yet) available in the data lake. This can be due to timing (ingestion not yet in place), costs (projects to connect more source systems into the data lake) or legal (some compliances forbid coping some information into the data lake because of geographic, or use of cloud, etc.). So, for executing some calculation where the data lake doesn’t contain all information, Big data compute engine can call Denodo, which will retrieve the right information from external existing systems probably only results stored again in the data lake. Based on the previous example, marketing can provide new campaigns with customer data (sourced within CRM or Customer Unified Views that cannot be replicated into the data lake for compliance/GDPR reasons) where results can be stored (or not) into the data lake
- Within DV layer: for performance reasons, for workload upon source systems, for maximizing Big Data investments, etc. Denodo can pilot your big data distribution in order to store (cache) data within your data lake, and manage the data “freshness,” making all requests going through your big data (instead of your mainframe as an example, which is not available 24/7, while your data lake is available 24/7) and you choose your refresh synchronization frequency according to your external constraints. DV will shift in this use case all the workload into your data lake platform, which is built for that. In addition, when requests are “data and compute heavy,” Denodo can also pilot the data lake by using the MPP (Massive Parallel Processing) functions provided by your Hadoop system. As an example, in “what is the generated revenue of a marketing event for a specific region for last 3 years,” with optimization and minimization, we can still manipulate a few million records; Denodo will send it to your data lake, make it process the request (distributed in multiple nodes), and deliver the result, reducing the full execution time drastically.
- Data Lake and DV: from Data Lake perspective
- “Ingestion” with control and performance: Denodo connects to any system, any format, abstract its content (by creating a virtual view), and can then create complex/enhanced/advanced views based on Denodo combine and transform functionalities. The caching option (box to select) can become a native “store into the data lake:” the virtual model inside Denodo will become the physical model, and “cached data” will be stored into the newly created physical model (table) with greatest performances (Generation of Parquet files (in chunks) with Snappy compression in the local machine — Upload in parallel of Parquet files to HDFS). As an example from the previous paragraph, this is how you may use Denodo, in order to store (partially or not) data from your Mainframe, your Point of Sale, your ERP (in the Cloud or files with low performance), your multiple warehouses, offload of Teradata, etc.
- Granular, and multichannel “exposition:” Like any source of data, the data lake is inheriting Denodo's native standard consumption functionalities; as a database (odbc/jdbc), as an API (web services, Rest/Json, Odata) or exporting as files. Data stored in your data lake through Denodo (as explained just before), or data provided by other means into your data lake (example, Kafka/spark/ETL, etc. bringing raw video/audio files where intelligent algorithm extract structured information from it for further usage/analysis, etc.); combined potentially with data from outside the data lake (if needed); all are accessible to the bigger audience in the company, taking also advantage of data catalog browsing and search.
- “full governance and auto-pilot:” Denodo is given the right to act in your data lake on your behalf, automating activities or consolidating actions from different groups into one place: connect, transform, enhance, create table, store, expose. If the model changes you will be notified of impacts, Denodo will update the model, store the right data again and expose it again. Denodo will create temporary spaces or tasks, and delete them upon requests termination (example with MPP needs). Denodo will also provide all its governance as security, access control, roles & authorization, audit, end-to-end monitoring, lineage of your data (origin and transformation made to be as it is during consumption).



Opinions expressed by DZone contributors are their own.
Comments