Deploy Elasticsearch on Kubernetes Using OpenEBS LocalPV
Join the DZone community and get the full member experience.
Join For FreeOverview
Elastic Stack is a group of open-source tools that includes Elasticsearch for supporting data ingestion, storage, enrichment, visualization, and analysis for containerized applications. As a distributed search and analytics engine, Elasticsearch is an open-source tool that ingests application data, indexes it then stores it for analytics.
Since it gathers large volumes of data while indexing different data types, Elasticsearch is often considered write-heavy. To manage such dynamic volumes of data, Kubernetes makes it easy to configure, manage, and scale Elasticsearch clusters. Kubernetes also simplifies the provisioning of resources for Elasticsearch using Infrastructure-as-Code configurations, abstracting cluster management.
While Kubernetes alone cannot store data generated by a cluster, persistent volumes can be used to sustain it for future use. To help with this, OpenEBS provisions local persistent volumes or LocalPV and allows for data to be stored on physical disks.
Many users have shared their experience of using OpenEBS for local storage management in Kubernetes for Elasticsearch, including the Cloud Native Computing Foundation, ByteDance (TikTok), and Zeta Associates (Lockheed Martin) on the Adopters list in the OpenEBS community available here.
In this guide, we explore how OpenEBS LocalPV can provision data storage for Elasticsearch clusters. This guide will also cover -
- Primary functions of Elastic Stack operators in a Kubernetes cluster
- Integrating Elasticsearch operators with Fluentd and Kibana to form the EFK stack
- Monitoring Elasticsearch cluster metrics with Prometheus and Grafana
Getting Started with Elasticsearch Analytics
Elasticsearch extends the ability to store and search large amounts of textual, graphical or numerical data efficiently. Kubernetes makes it easy to manage the connections between Elasticsearch nodes, thereby simplifying deploying Elasticsearch on-premises or in hosted cloud environments. It must be noted that Elasticsearch nodes are different from Kubernetes nodes of a cluster. While an Elasticsearch node runs a single instance of Elasticsearch, a Kubernetes node is a physical or virtual machine that the orchestrator runs on.
Elasticsearch Cluster Topology
From Kubernetes’ point of view, an Elasticsearch node can be considered as a POD. Whenever an Elasticsearch cluster is deployed, three types of Elasticsearch PODs are created:
- Master - manage the Elasticsearch cluster
- Client - direct incoming traffic to appropriate PODs
- Data - responsible for storing and availing cluster data
The diagram below shows the topology of a typical 7 POD Elasticsearch cluster with 3-master, 2-client and 2-data nodes:
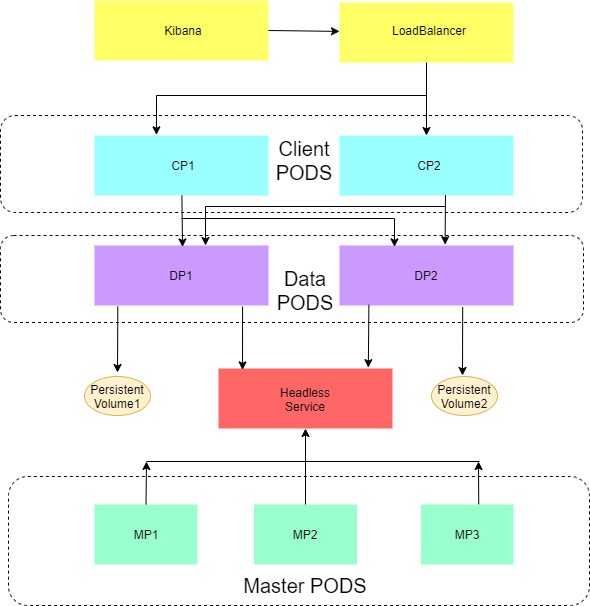
Deploying Elasticsearch involves creating manifest files for each of the cluster’s PODs. By connecting to the cluster, OpenEBS creates a visibility tier that enables cluster monitoring, logging and topology checks for LocalPV Storage. Additionally, to enable cluster-wide analytics, the following tools are deployed :
- Fluentd - An open-source data collection agent that integrates with Elasticsearch to collect log data, transform it then ship it to the Elastic Backend. Fluentd is set up on cluster nodes to collect and convert POD information and send it to the Elasticsearch data PODs for storage and indexing. It is typically set up as a DaemonSet to run on each Kubernetes worker node.
- Kibana - Once the cluster is deployed on Kubernetes, it needs to be monitored and managed. To help with this, Kibana is used as a visualization tool for cluster data by providing the Elasticsearch client service as an environment variable in PODs that Kibana should connect to.
Solution Guide
The following solution guide explains the steps and important considerations for deploying Elasticsearch clusters on Kubernetes using OpenEBS Persistent Volumes. By following the guide, you can create persistent storage for the EFK stack supported by Kubernetes, to which OpenEBS is deployed. The guide includes steps on performing metric checks and performance monitoring for the Elasticsearch cluster using Prometheus and Grafana.
Let us know how you use Elasticsearch in production and if you have an interesting use case to share. Also, please check out other OpenEBS deployment guides on common Kubernetes stateful workloads on our website.
- Deploying Kafka on Kubernetes
- Deploying WordPress on DigitalOcean Kubernetes
- Deploying Magento on Kubernetes
- Deploying Percona on Kubernetes
- Deploying Cassandra on Kubernetes
- Deploying MinIO on Kubernetes
- Deploying Prometheus on Kubernetes
This article has already been published on https://blog.mayadata.io/deploy-elasticsearch-on-kubernetes-using-openebs-localpv and has been authorized by MayaData for a republish.
Published at DZone with permission of Sudip Sengupta. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments