Deploy IBM App Connect Enterprise Apps From CI/CD
Sharing an Example Tekton Pipeline for Deploying an IBM App Connect Enterprise Application to Red Hat OpenShift.
Join the DZone community and get the full member experience.
Join For FreeThis post is about a repository I've shared on GitHub at dalelane/app-connect-tekton-pipeline. It contains an example of how to use Tekton to create a CI/CD pipeline that builds and deploys an App Connect Enterprise application to Red Hat OpenShift.

The pipeline uses the IBM App Connect Operator to easily build, deploy and manage your applications in containers. The pipeline runs on OpenShift to allow it to easily be integrated into an automated continuous delivery workflow without needing to build anything locally from a developer's workstation.
For background information about the Operator, and the different types of Kubernetes resources that this pipeline will create (e.g. IntegrationServer and Configuration), see these blog posts:
- What is an Operator and why did we create one for IBM App Connect?
- Exploring the IntegrationServer Resource of the IBM App Connect Operator
Pipeline
The pipeline builds and deploys your App Connect Enterprise application. You need to run this every time your application has changed and you want to deploy the new version to OpenShift.
When running App Connect Enterprise in containers, there is a lot of flexibility about how much of your application is built into your container image, and how much is provided when the container starts.
For background reading on some of the options, and some of the considerations about them, see the blog post: Comparing styles of container-based deployment for IBM App Connect Enterprise.
This pipeline provides almost all parts of your application at runtime when the container starts. The only component that is baked into the image is the application BAR file.
Baking the BAR files into custom App Connect images prevents the need to run a dedicated content server to host BAR files, however, if you would prefer to do that see the documentation on Mechanisms for providing BAR files to an integration server for more details on how to do this. (The pipelines in the repository use the approach described as "Custom image" in that documentation.)
Running the Pipeline
- pipeline spec:
- example pipeline runs:
- helper scripts:
What the Pipeline Does
Builds your IBM App Connect Enterprise application and deploys it to the OpenShift cluster.
Outcome From Running the Pipeline
A new version of your application is deployed with zero-downtime - replacing any existing version of the app once it is ready.

Background
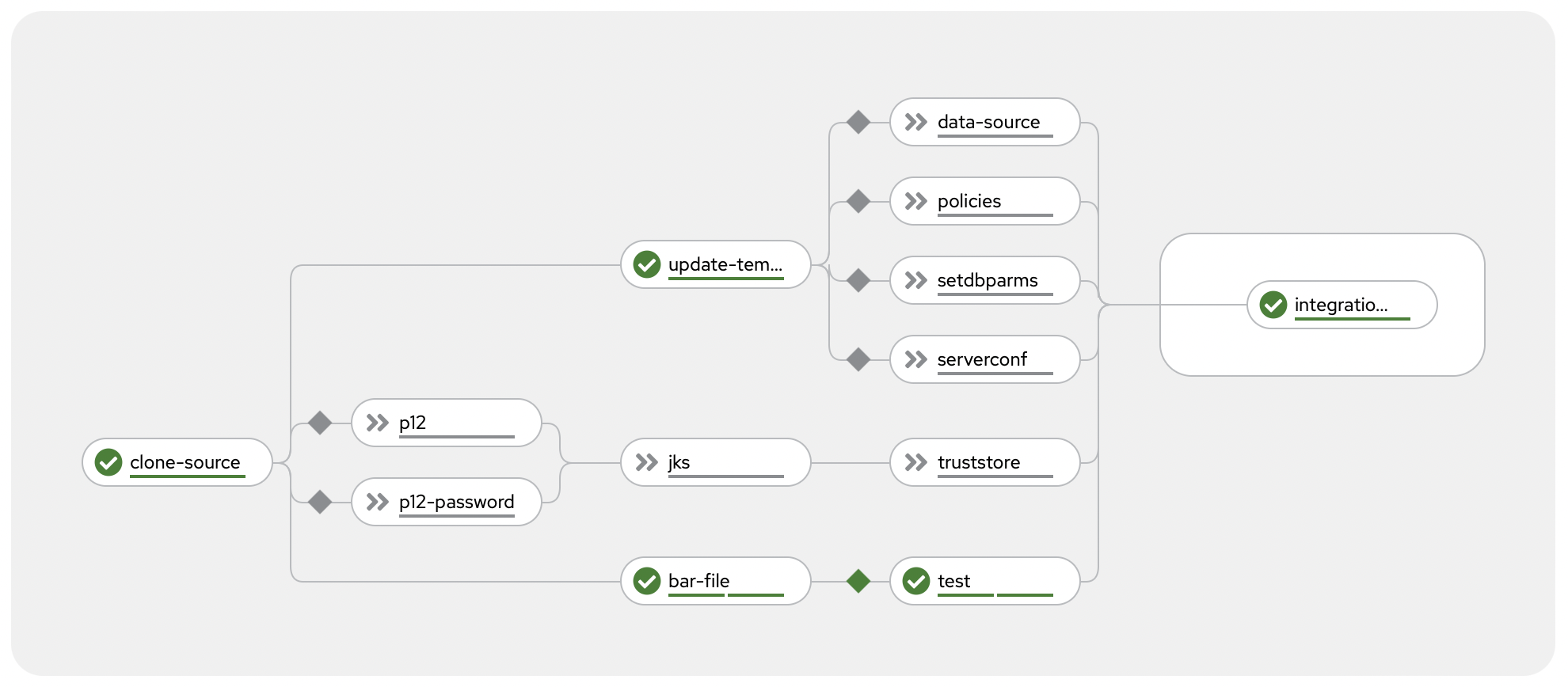
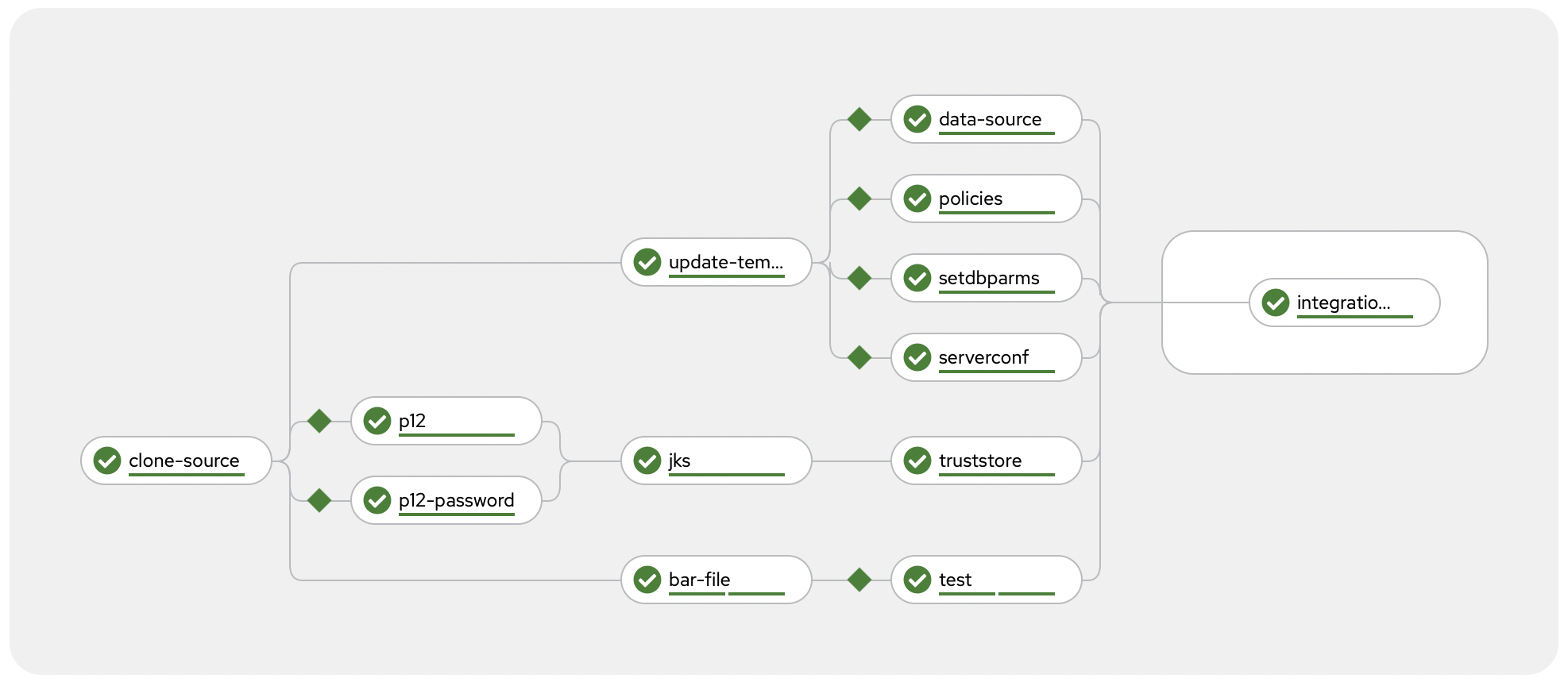
As discussed above, most of your application configuration will be provided to your application container at runtime by the Operator using Configuration resources.
As shown in the screenshot above, this example pipeline currently supports many, but not all, of the types of Configuration resource:
- Loopback data source type
- Policy project type
- setdbparms.txt type
- server.conf.yaml type
- Truststore type
For more information about the other Configuration types, see the documentation on Configuration types for integration servers. Adding support for any of these additional types would involve adding additional tasks to the tasks provided in the repo - the existing tasks are commented to help assist with this.
Each of these configuration resources is individually optional. Two example App Connect applications are provided to show how the pipeline supports different application types.
Simple Stand-Alone Applications
The pipeline can be used to deploy a stand-alone application with no configuration dependencies.
- sample application
- pipeline run config
- demo script:
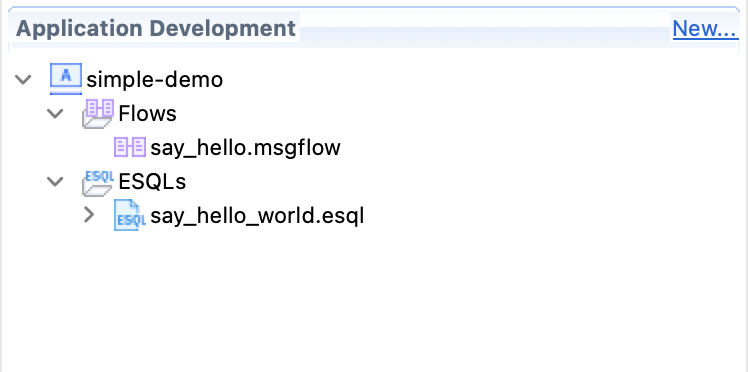
This is a simple App Connect application with no external configuration.
When deploying this, the pipeline skips all of the Configuration tasks:
Watching the pipeline run looks like this (except it takes longer).
Complex Applications
The pipeline can be used to deploy complex applications with multiple configuration dependencies and support Java projects.
- sample application
- pipeline run config
- demo script:

This is an example of an App Connect application that needs configuration for connecting to:
- a PostgreSQL database
- an external HTTP API
- an Apache Kafka cluster
When deploying this, the pipeline runs all of the Configuration tasks required for this application:
Watching the pipeline run (also sped up!) it looks like this.

To avoid needing to store credentials in Git with your application code, the pipeline retrieves credentials from Kubernetes secrets. When configuring the pipeline for your application (see the section below) you need to specify the secrets it should use to do this.
Sample Apps
I've put notes on how I set up the sample apps to demonstrate the pipeline in demo-pre-reqs/README.md however, neither of the sample apps is particularly useful and was purely used to test and demo the pipeline.
You can import them into App Connect Toolkit to edit them if you want to by:
- File -> Import... -> Projects from Folder or Archive
- Put the location of the ace-projects folder as the Import source.
- Tick all of the projects
That will let you open the projects and work on them locally. If you're curious what they do, I'll include some brief notes below:
Simple App
It provides an HTTP endpoint that returns a Hello World message.
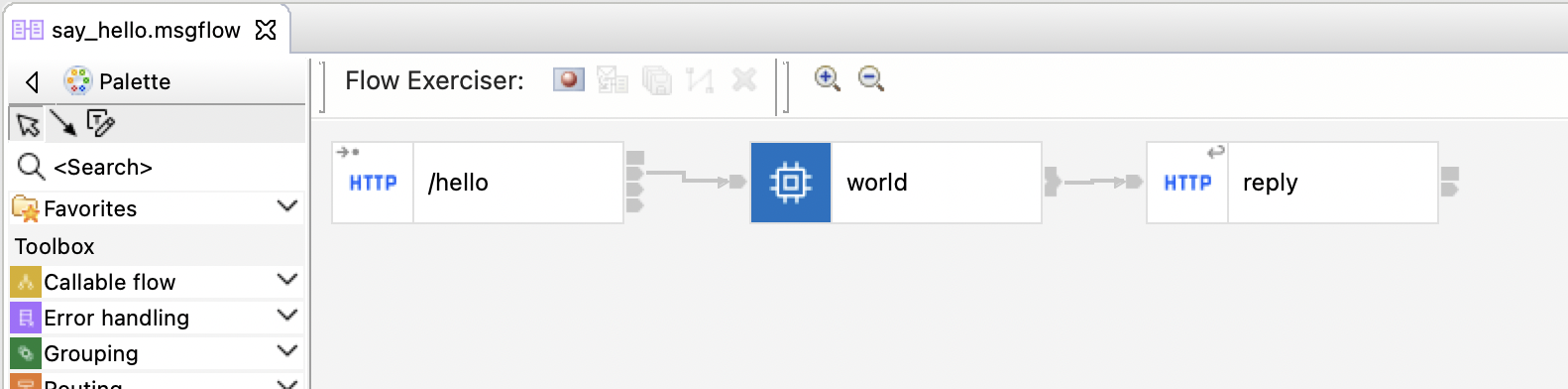
Running this:
curl http://$(oc get route -nace-demo hello-world-http -o jsonpath='{.spec.host}')/hello"returns this:
{ "hello" : "world" }Complex App
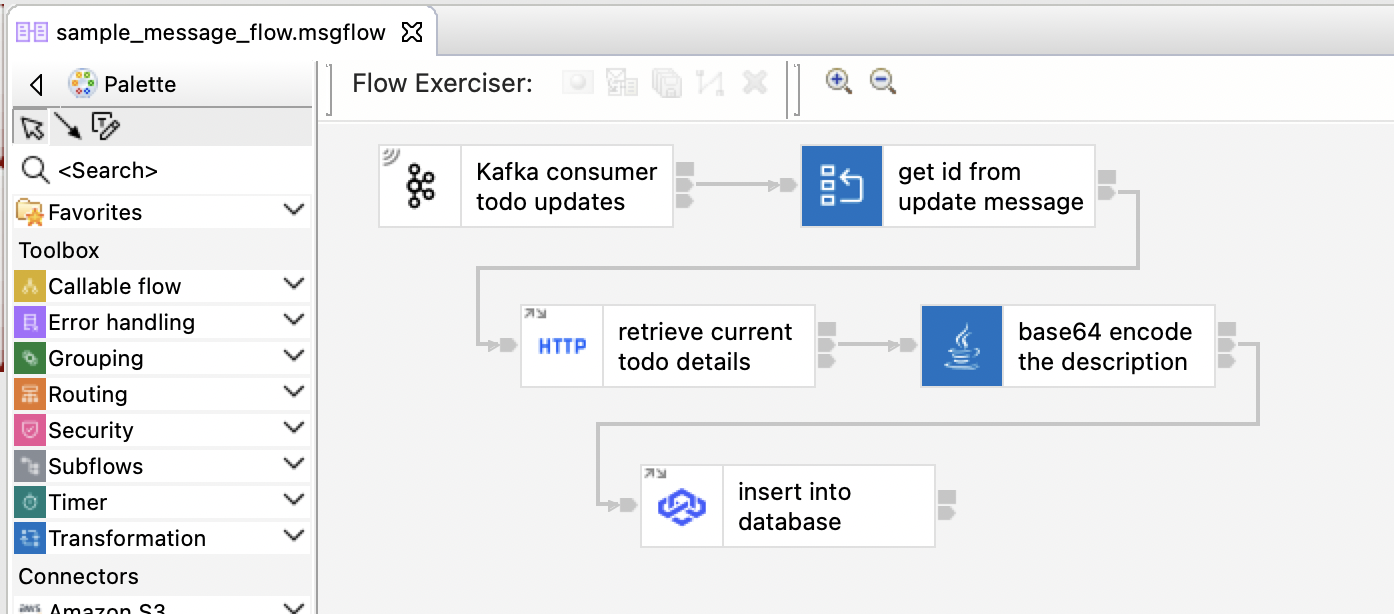
It provides an intentionally contrived event-driven flow that:
- "Kafka consumer todo updates"
- receives a JSON message from a Kafka topic
- "get id from update message"
- parses the JSON message and extracts an ID number from it
- uses the id number to create an HTTP URL for an external API
- "retrieve current todo details"
- makes an HTTP GET call to the external API
- "base64 encode the description"
- transforms the response from the external API using a custom Java class
- "insert into database"
- inserts the transformed response payload into a PostgreSQL database
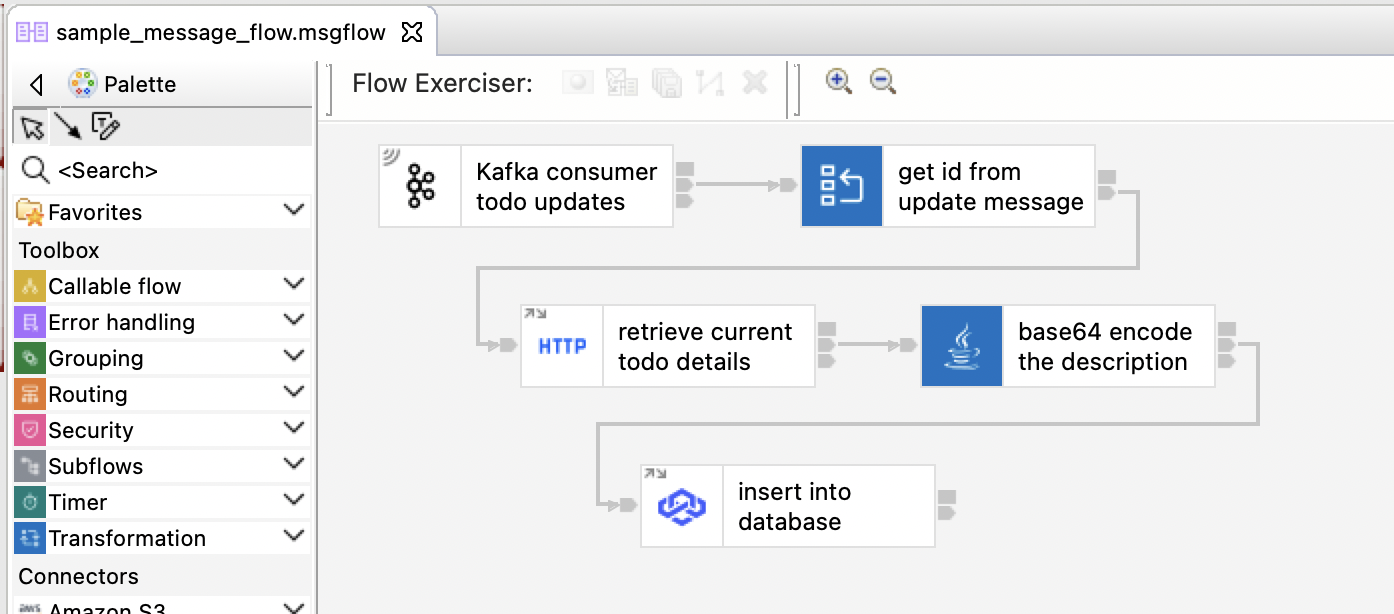
The aim of this application was to demonstrate an ACE application that needed a variety of Configuration resources.
But it means that running this:
echo '{"id": 1, "message": "quick test"}' | kafka-console-producer.sh \
--bootstrap-server $BOOTSTRAP \
--topic TODO.UPDATES \
--producer-property "security.protocol=SASL_SSL" \
--producer-property "sasl.mechanism=SCRAM-SHA-512" \
--producer-property "sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="appconnect-kafka-user" password="$PASSWORD";" \
--producer-property "ssl.truststore.location=ca.p12" \
--producer-property "ssl.truststore.type=PKCS12" \
--producer-property "ssl.truststore.password=$CA_PASSWORD"
gets you this:
store=# select * from todos; id | user_id | title | encoded_title | is_completed ----+---------+--------------------+--------------------------------------+-------------- 1 | 1 | delectus aut autem | RU5DT0RFRDogZGVsZWN0dXMgYXV0IGF1dGVt | f (1 row)
Configuring the Pipeline for Your App Connect Enterprise Application
To run the pipeline for your own application, you need to first create a PipelineRun.
The sample pipeline runs described above provide a good starting point for this, which you can modify to your own needs. You need to specify the location of your App Connect Enterprise application code and configuration resources. All of the available parameters are documented in the pipeline spec if further guidance is needed.
Alternative Approaches
Running App Connect Enterprise in containers is ideally suited to a variety of CI/CD approaches. The pipeline described in this post was useful for a project I recently worked on, but you can find a variety of other pipeline approaches for managing your ACE application. For another great option, see github.com/ot4i/ace-demo-pipeline.
Published at DZone with permission of Dale Lane. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments