Deploying Kafka on OpenShift
Bringing Kafka to the cloud.
Join the DZone community and get the full member experience.
Join For FreeThis article describes an easy way for developers to deploy Kafka on Red Hat OpenShift.
Managed Services
There are multiple ways to use Kafka in the cloud. One way is to use IBM’s managed Event Streams service or Red Hat’s managed service OpenShift Streams for Apache Kafka. The big advantage of managed services is that you don’t have to worry about managing, operating, and maintaining the messaging systems. As soon as you deploy services in your own clusters, you are usually responsible for managing them. Even if you use operators which help with day 2 tasks, you will have to perform some extra work compared to managed services.
Operators
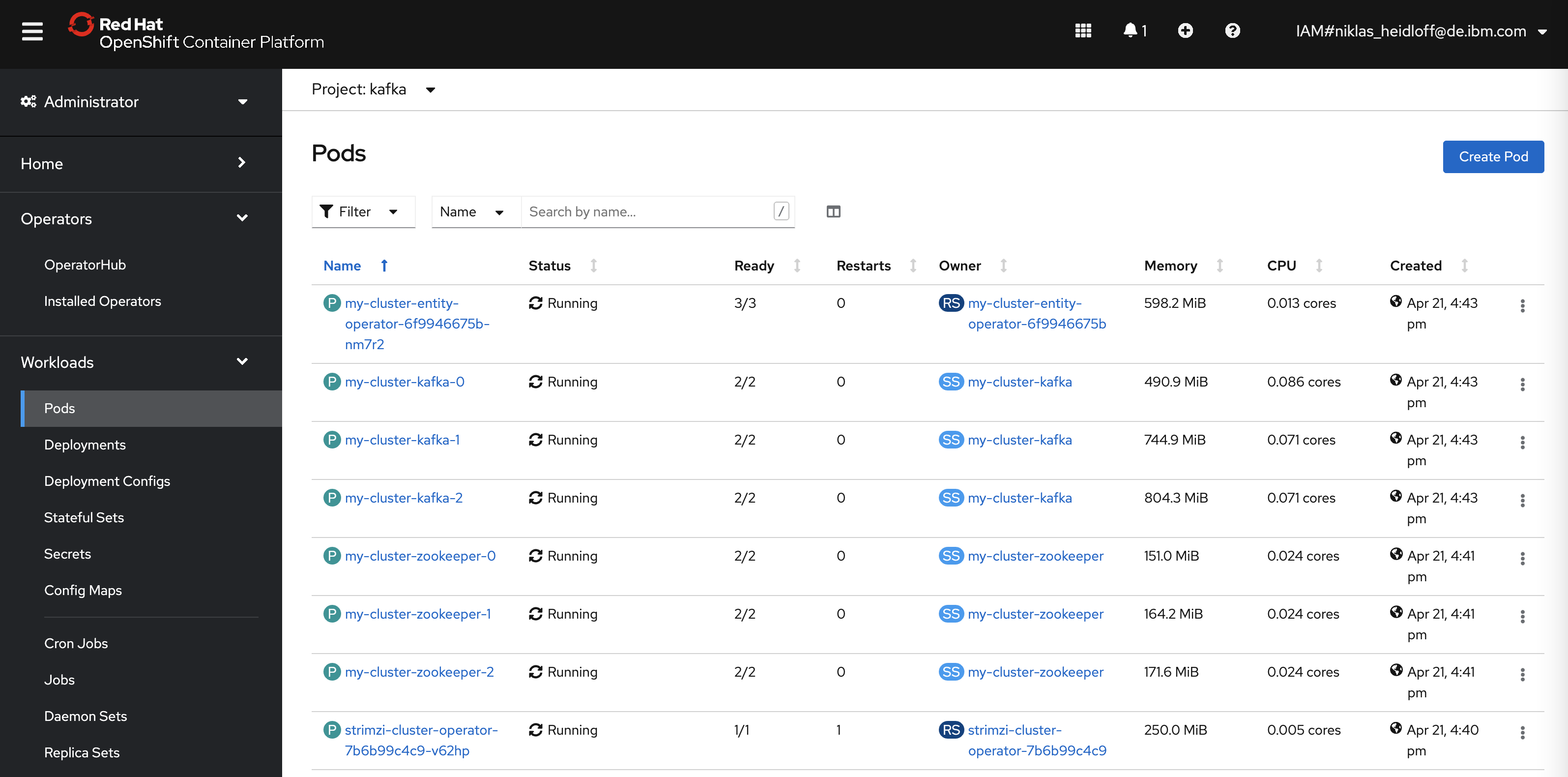
Another approach to use Kafka is to install it in your own clusters. Especially for the early stages in projects when developers want simply to try out things, this is a pragmatic approach to get started. For Kafka multiple operators are available which you find on the OperatorHub page in the OpenShift Console, for example:
- Strimzi
- Red Hat Integration – AMQ Streams
Strimzi is the open-source upstream project for Red Hat’s AMQ Streams operator. It’s also the same code base used in Red Hat’s new managed Kafka service.
As always you can install the operators through the OpenShift user interface or programmatically.
Programmatic Setup
For my application modernization example, I’ve used the programmatic approach to set up the Strimzi operator.
$ oc new-project kafka
$ curl -L https://github.com/strimzi/strimzi-kafka-operator/releases/download/0.15.0/strimzi-cluster-operator-0.15.0.yaml \
| sed 's/namespace: .*/namespace: kafka/' \
| oc apply -f - -n kafka
$ oc apply -f kafka-cluster.yaml -n kafka
$ oc expose svc/my-cluster-kafka-external-bootstrap --port=9094
$ echo Run this command \(potentially multiple times\): \"oc wait kafka/my-cluster --for=condition=Ready --timeout=300s -n kafka\"
In the file kafka-cluster.yaml, the cluster is defined.
xxxxxxxxxx
apiVersionkafka.strimzi.io/v1beta1
kindKafka
metadata
namemy-cluster
spec
kafka
version2.3.0
replicas3
listeners
plain
tls
external
typenodeport
tlsfalse
config
offsets.topic.replication.factor3
transaction.state.log.replication.factor3
transaction.state.log.min.isr2
log.message.format.version'2.3'
storage
typeephemeral
zookeeper
replicas3
storage
typeephemeral
entityOperator
topicOperator
userOperator
After this Kafka will be available under ‘my-cluster-kafka-external-bootstrap.kafka:9094’ for other containers running in the same cluster.
Next Steps
To learn more about OpenShift deployments and application modernization, check out the Application Modernization – From Java EE in 2010 to Cloud-Native in 2021 on GitHub.
Published at DZone with permission of Niklas Heidloff. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments