How to Design an AI-Based Enterprise Search in AWS
Step-by-step guide in designing an intelligent Enterprise Search capability using natural language processing and advanced machine learning in AWS.
Join the DZone community and get the full member experience.
Join For FreeFinding right information at the right moment is a key distinguisher in today's modern organization. This not only saves huge time and effort but boosts customer satisfaction as well as employee productivity. However, in most large organizations, all the contents and information are scattered and not indexed and organized properly. Often employees and customers browse through unrelated links for hours when they look for some urgent information (e.g., product information or process flows or policies, etc.) in the company's portal or intranet. Popular content management (CMS) software or wikis like Confluence or document management repositories like SharePoint lack the perfect intelligent search capabilities resulting in inefficiency as they only use the partial or full-text search based on keyword matching ignoring the semantic meaning of what the user is looking for.
Also, the traditional search doesn't understand if the question is being asked in natural language. It treats all words as search queries and tries to match all documents or contents based on that. For example, if I need to find which floor our IT helpdesk is located in my office building and simply search "Where is the IT Helpdesk located?" in general, CMS or Wiki software powering the company intranet it may bring up all links or texts matching every word of my question including "IT," "Helpdesk" as well as "located.” This would waste employee productivity, time, and morale as he or she would be spending a long time identifying correct info.
Let's assume there is an e-commerce retailer in the clothing field. If someone searches using French words for black shirt using "chemise noire," the regular full-text search probably wouldn't find anything if language translation is not done in the system. It would show no results to the users, and effectively there is a loss in the business.
Designing the Solution
To overcome the problem the organizations are facing while using keyword matching services, Amazon launched the Amazon Kendra serverless service that uses machine learning to understand the context and intent of the question asked by the user in natural language and, using this, figure out the right content or answers and respond back to the user in the same natural language.
Amazon Kendra comes with many data connectors to support quick integration to any Enterprise data sources (Salesforce CRM, Sharepoint, Jira/Confluence or S3 buckets, file server). So it is really easy to connect to any content repository.
Once the source integration is done, in the Amazon Kendra console, the "index" can be created, which would be synced from the content even if that changes over time. This syncing process helps Kendra to learn and rank the content internally using Machine Learning.
Once Kendra indexing is complete and ready to be used, the UI can either be customized or can be accessed through API integration. Below design depicts the flow:
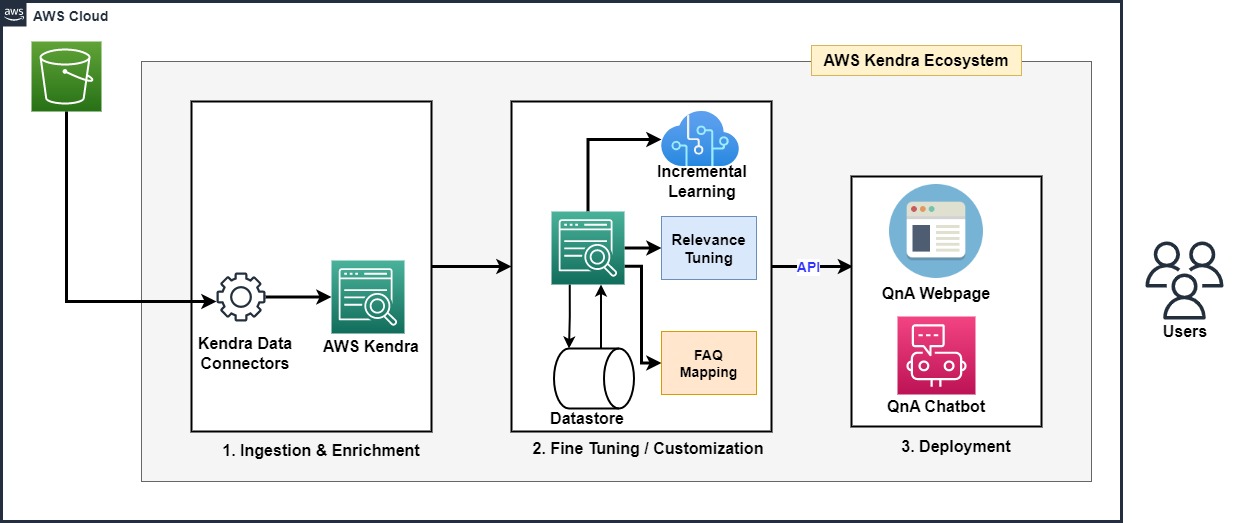
Enterprise Use Cases
There are multiple use cases where the intelligent search capability can be leveraged.
- Helpdesk/ Contact Center: Helpdesk or contact center agents spend a significant amount of time identifying the right steps while assisting internal or external customers when the knowledge base grows up. Using this intelligent search capability would help the CC agents quickly answer customers' queries. This would not only reduce the call volume time but increase customer satisfaction as well as agents' performance.
- Recommendation System: AWS Kendra can also be used to build a recommendation platform where the customers would be more engaged based on the recommendation service through integrating the FAQ system.
- SAAS applications or products can leverage the ML-powered in-app search so users can quickly find the relevant answers they are looking for.
- Since Kendra's API can be integrated with QnA bots, the contact center cost or waiting time will be lesser as users would be able to find answers quickly using the self-serve bots or agent-less information finder.
Benefits of Using AWS Kendra
- AWS Kendra helps you to quickly launch and implement a unified search experience across your organization with varying data sources from multiple structured and unstructured contents. Since it has almost all the data connectors to ingest data from Salesforce or SharePoint or S3 buckets, or DBs, the development effort is very minimal.
- Kendra supports using natural language processing (NLP) to get highly accurate answers using the machine learning (ML) technique, but that doesn't mean you have to have machine learning expertise in the organization but still can provide similar capabilities to the users.
- In Kendra, it is possible to use the metadata attributes, user behavior, and freshness to fine-tune the search results.
- AWS Kendra supports integrating external FAQ with the content ingested based on document ranking and machine learning which engage the users.
Demo
The very basic steps to design a solution with Kendra are:
- Create an Index
- Integrate the required data source using the available multi-channel data connectors in Kendra.
- Deploy and do testing using the built-in UI or use the REST API to integrate your own UI.
Amazon Kendra has multiple data connectors for Amazon RDS database, S3, Jira / Confluence, SalesForce CRM, ServiceNow, Slack, Google Drive, Microsoft OneDrive, and Microsoft SharePoint and can extract and consume data from PDF or HTML or CSV - almost any popular format. In the following sections, we will go through in detail of each step.
1. Create an Index
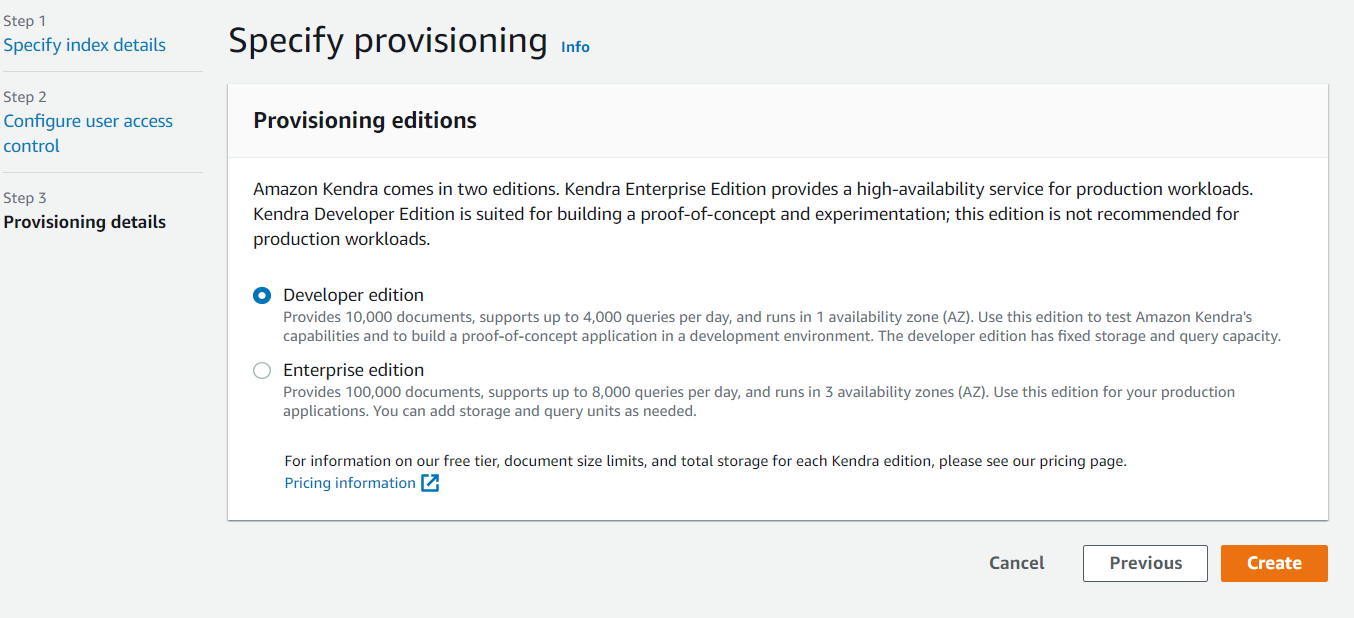
Log in to the AWS console and change the region to the supported region where AWS Kendra is available. Launch AWS Kendra from the search bar. Click on the Create index and enter details, as shown in the screenshot below. You can choose to use your own name here.


Since we will be using a couple of documents to experiment so, I selected "Developer Edition."
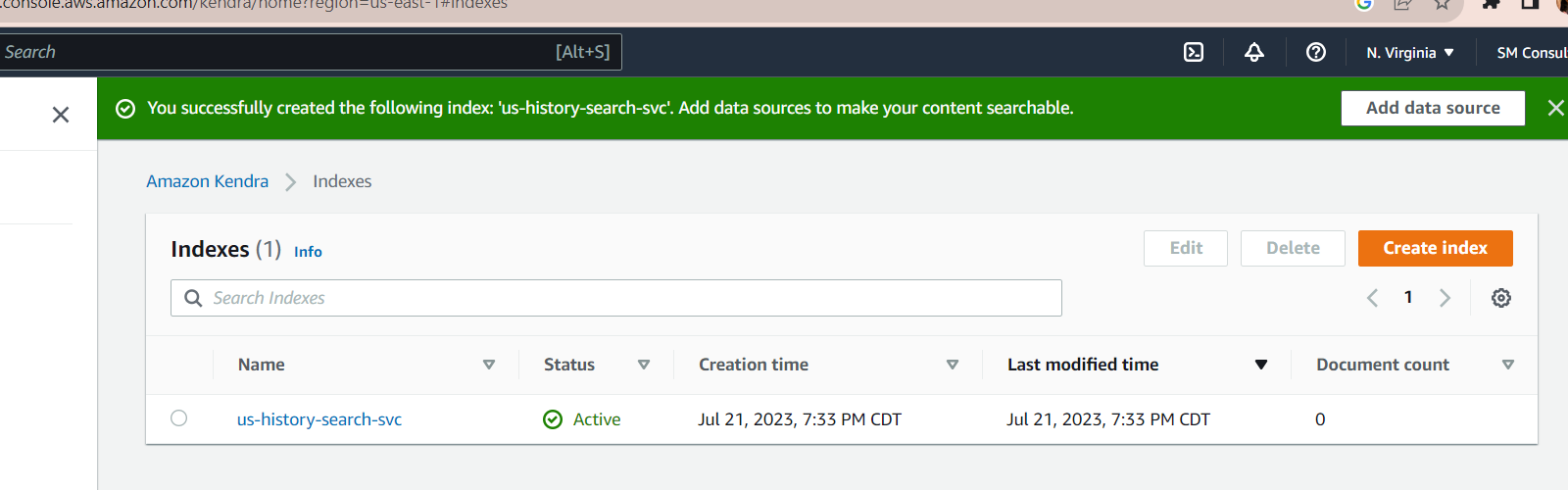
Once you click the Create button, AWS would provision an AWS Kendra instance with the index created.
2. Integrate the Data Ingestion
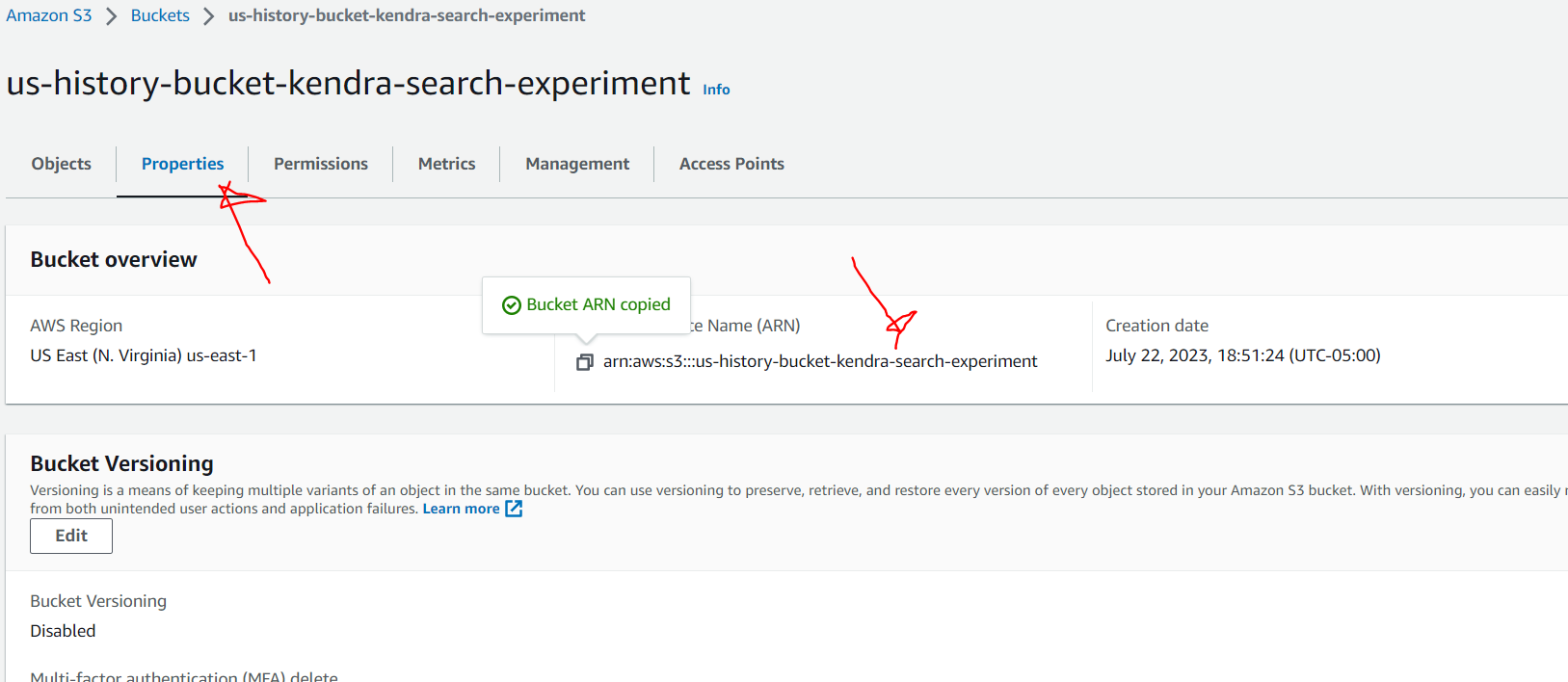
Before we integrate the S3 bucket as a data source, we need to create the S3 bucket first. Once the bucket is created, we can upload some PDF files of your choice. I downloaded 2 US history ebooks (Volume 2 and 3) from Project Gutenburg, which I uploaded to the bucket.


Once you have uploaded all the files go to the Properties tab in the S3 service to copy the ARN.
Go to the AWS Kendra service and select the index we created earlier. You will see the "Add Data Source" option to connect to the data source. We need to use the Amazon S3 connector to connect to the S3 bucket.

You can provide any name to the data source; for simplicity, I am using s3-pdf-docs.
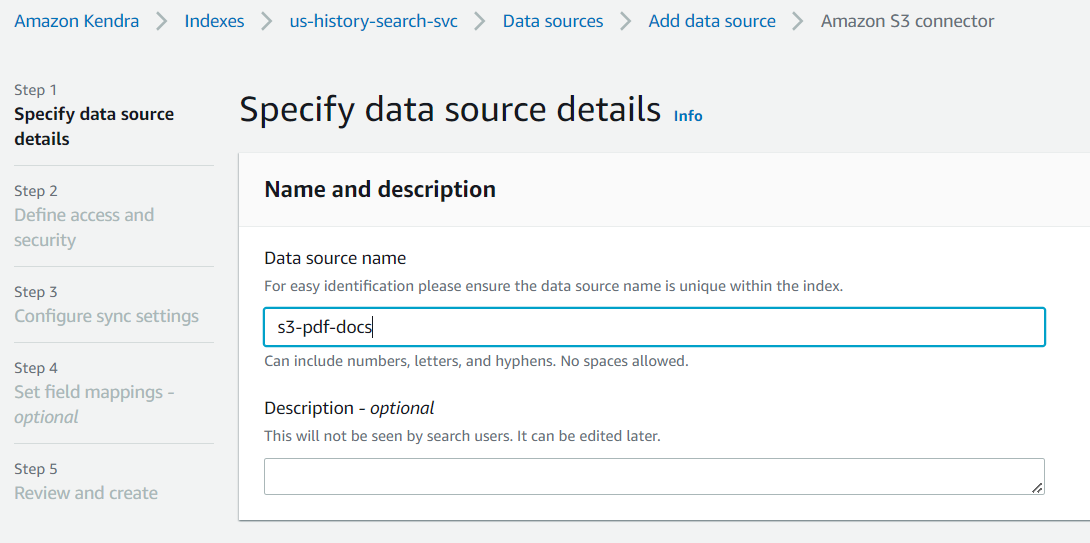
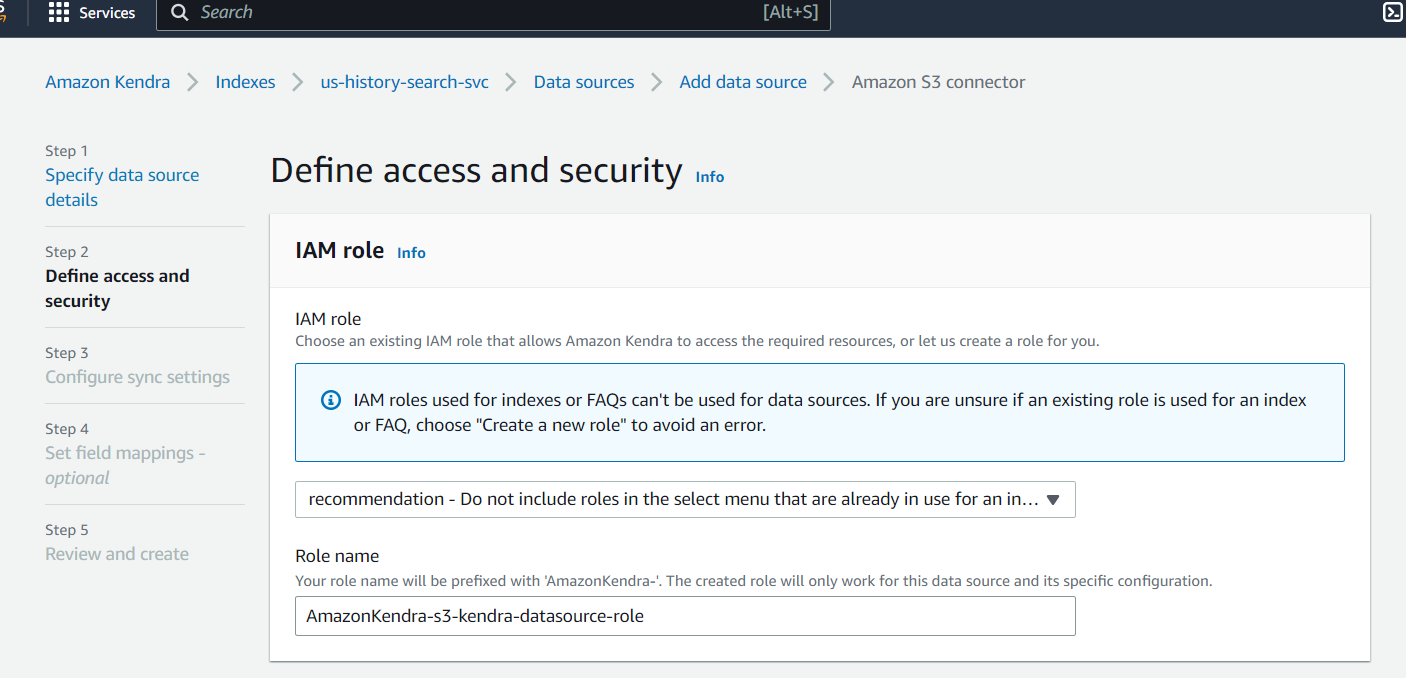
Create a new IAM role for the data source.
For the sync section, browse the S3 bucket to sync from, and frequency would be on demand.

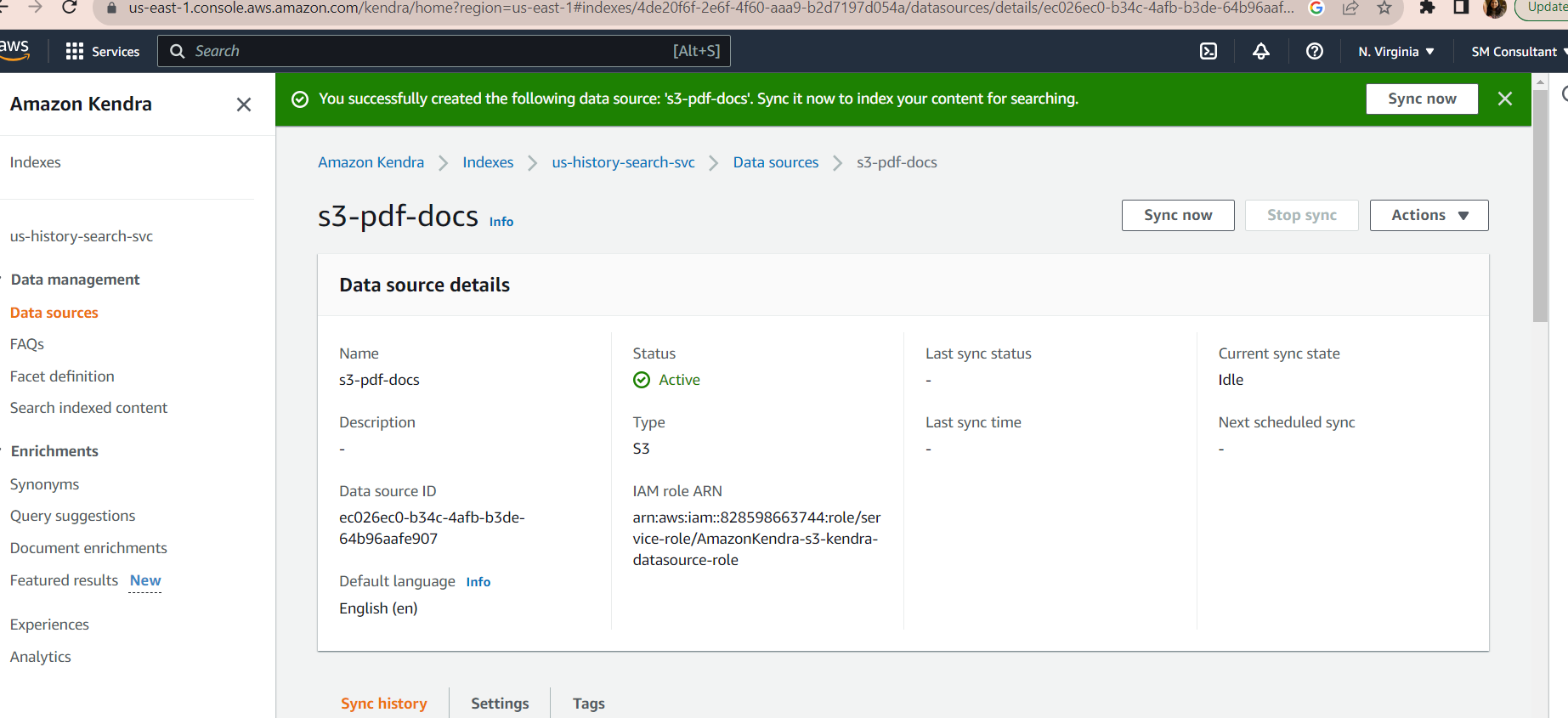
Choose the default options that come next and click the Add Data source to start the syncing process.
3. Sync the Ingestion Process From the Source
Once the data source is active, you must start the Sync process to load the pdf text data from the S3 bucket to Kendra's index.
Once syncing process is started, it will be shown as In progress status in the history section.
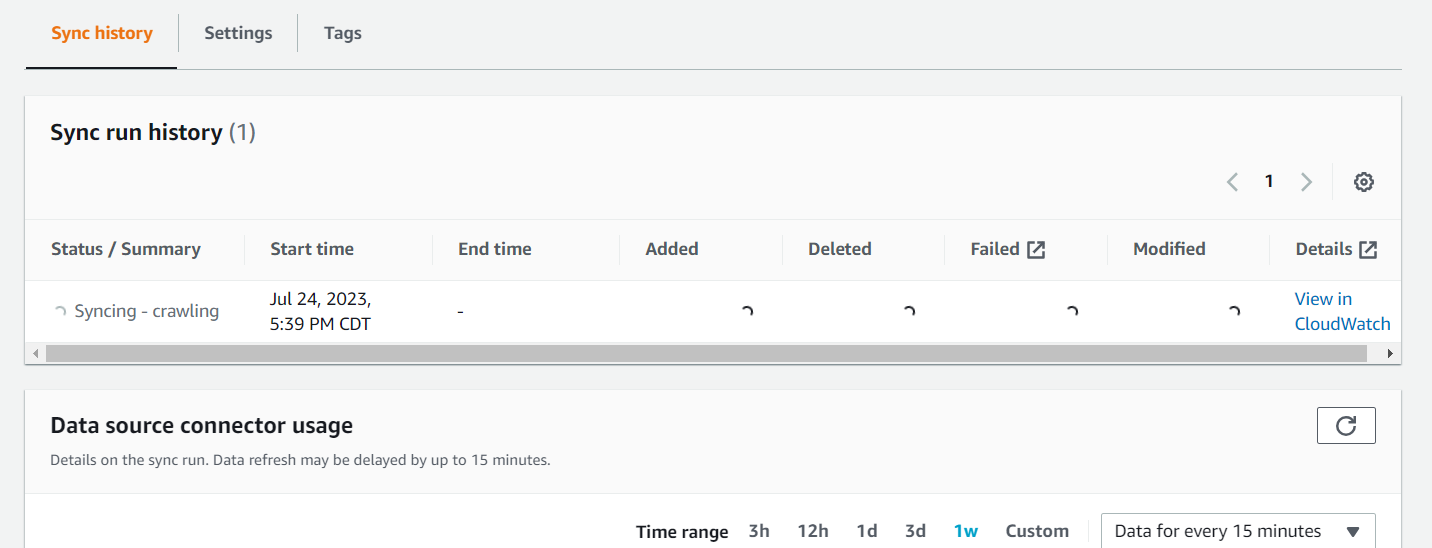
4. Validate the Data Ingestion
When the syncing process is completed, it will show the document count confirming that the new documents have been added and indexed.
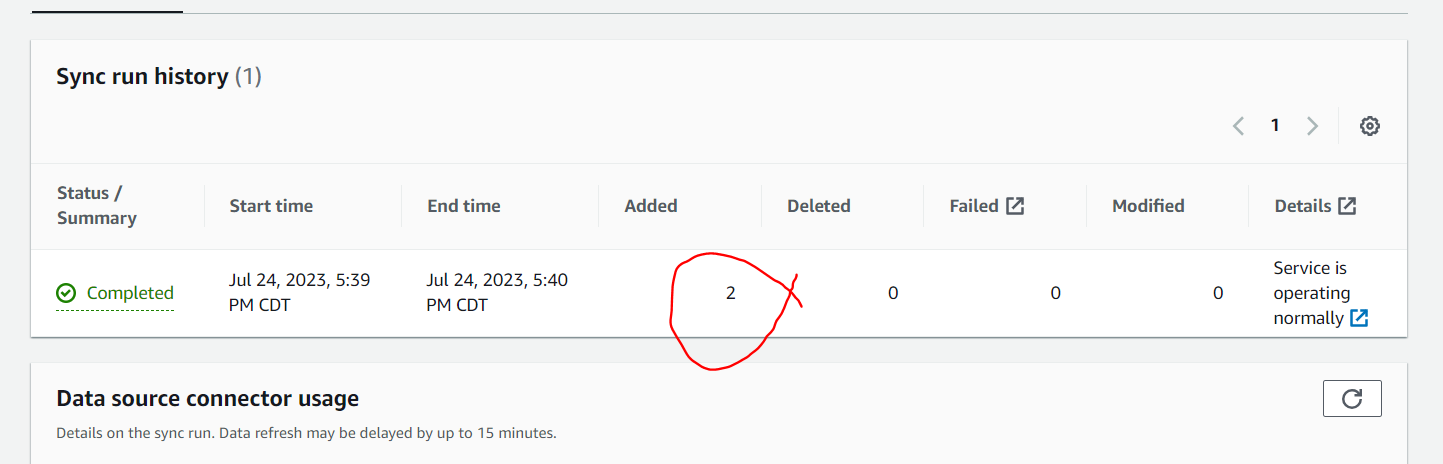
Once the document is ingested, click on the "Search Indexed content" to validate the search.

5. Test AWS Kendra Default Search in the Console
I searched using the keyword (shown below), and the results have been fetched immediately. It didn't get the results correctly, but it was able to pull the excerpt from the document as well.
Kendra comes with many in-built features so that the results can be fine-tuned and exposes API and SDK to connect and use in other UI.
Remember to delete the Index when you are done with experimenting; otherwise, it might incur some cost in the future.

Conclusion
As it is shown in the above guide that it is so easy to set up a full fledge machine learning-based custom Enterprise search based on proprietary Enterprise data and documents, which not only is scalable but provides out-of-the-box features to customize the results which would suit the requirements. Amazon Kendra provides API to combine with any Single Page Application or QnA bot providing greater flexibility. The best feature is that Kendra comes with so many data connectors that it can seamlessly be integrated with any kind of Enterprise data source, and there is no need to put any extra effort into building such.
Published at DZone with permission of Suvoraj Biswas. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments