Designing Chatbots for Multiple Use Cases: Intent Routing and Orchestration
Effective multi-use-case chatbots depend on strong intent routing, context-aware orchestration, tailored LLM parameters, and evaluation.
Join the DZone community and get the full member experience.
Join For FreeOrganizations today want to build chatbots capable of handling a multitude of tasks, such as FAQs, troubleshooting, recommendations, and ideation. My previous article focused on a high-level view of designing and testing chatbots. Here, I will dive deeper into how strong intent routing and orchestration should figure into your chatbot design.
What Is a Multi-Use Chatbot?
A multi-use case chatbot supports several distinct tasks, each with different goals, performance needs, and response styles. For each use case, LLM parameters are fine-tuned around its goals. For example, a factual FAQ flow might use a low temperature for consistency, while a recommendation flow might use a higher one for creativity. Similarly, top p-values, frequency, presence, and max token penalties are also adjusted based on the use case.
When multiple use cases are combined, adjusting and orchestrating these parameters dynamically becomes critical. The article is going to dive into two key concepts: intent routing (determining what the user wants) and orchestration (choosing how to handle it).
Understanding the Challenges of Multi-Use-Case Chatbots
The unique pain points of multi-use case chatbots explain why they require separate or further attention. Unlike single-use case chatbots, multi-use chatbots handle different tasks, requiring their parameters to be dynamically adjusted to the function at hand. This introduces three issues:
- Intent Confusion – The chatbot may misclassify the user’s goal (an example could be interpreting a refund query as a product recommendation)
- Overlapping Context—Tasks that leverage RAG or MCPs may utilize different knowledge bases. For example, a customer-support task might access a compliance repository instead of the intended troubleshooting documentation, returning accurate but irrelevant information
- Hallucinations – While not specific to just multi use case chatbots, there is more room for risk of the model fabricating information or retrieve incorrect information
As the number of supported tasks increases, these issues compound; even small intent misclassifications can cascade into poor user experience or compliance issues. To overcome these challenges, two pillars are essential – intent clarity and context management.
Step 1: Intent Recognition and Routing
For a chatbot to handle multiple use cases, the first step is to recognize the user's intent correctly.
Intent First Design:
The simplest way to identify intent is by asking directly. For limited and clearly defined tasks, this can be achieved through a simple menu-based interface or button selection. However, as the number of use cases increases, this becomes inefficient. Additionally, most users prefer to type naturally. This leads to Natural Language Understanding (NLU) routing.
NLU allows the chatbot to infer intent from free-form text. This typically involves:
- Text embedding: Represent the user’s query as a vector (using a transformer such as Sentence-BERT embeddings or OpenAI). This is the process of converting the textual representation into a numeric one.
- Context store (the intent vectors): A document containing all the tasks along with their respective parameters is stored and vectorized in a database for efficient routing
- Similarity Search: Compare the vector representations with known intent vectors to find the most likely match. The matching is usually done using a cosine similarity or a well fine-tuned classifier.
Confidence Thresholds and Clarification:
Similarity scores have ranged from 0 to 1, with 0 being not similar at all and 1 being exactly the same. A confidence threshold should be set for clear intent detection.
- If the confidence threshold exceeds 95%, the task can be routed automatically if it is not critical. If critical (e.g., making changes to an internal file system), then a simple confirmation is necessary that “X” activity is being performed.
- If it's below this value but above 70%, then trigger a clarifying step. This could be taking the top 2 or top 3 similarity scores. An example would be replying with, “Did you mean to track an order or request a refund?”
A chatbot that clarifies when uncertain builds user trust far more than one that just guesses.
Fallbacks and Human in the Loop:
When intent remains unclear after 3-4 clarifying questions, the chatbot should gracefully fall back to a default statement that admits not only its inability to resolve the issue, but also where they could possibly find it. At this points, the best solution is to have a human in the loop.
Step 2: Orchestration and Context Management
Once the user's intent is identified, the system must answer that question correctly at the lowest cost. Achieving this requires orchestration and context management.
Orchestration refers to selecting the right pipeline based on the detected intent. I have shared some examples below to clarify the definition.
- If the user wants to track a product order, directing them to the rules engine pipeline with simple API calls to the database will resolve this.
- If the user is looking for product recommendations, directing them towards an LLM for creative purposes, but also grounding it with a RAG or MCP would be necessary.
Note: An LLM can solve both cases. But ensuring orchestration is in place guarantees a more robust model that is always available to the user in the fastest, most cost-effective way.
Once we have determined the correct pipeline, context management ensures the chatbot only surfaces relevant data. This reduces hallucinations and costs. Reiterating the same above examples:
- To track a product's order, the order ID and shipment ID must be retrieved from the database.
- Fetching product ideas, on the other hand, requires the LLM to be grounded in the product catalog and customer history to ensure effective recommendations and avoid recommending products that aren’t available.

Together, these ensure that the right pipeline is chosen and then narrowed in scope to deliver the best possible answers to the user at the most cost-effective level.
Goal: Once intent is known, decide how to answer.
- Orchestration = Selecting the right pipeline (LLM, rules engine, API)
- Grounding = Fetching relevant context for that use case (RAG, MCP)
- Isolate context per intent to avoid cross-contamination
- Use modular architecture: each use case as a separate “tool” or “agent.”
- Examples:
- “
Refund request” → route → rules engine + database - “
Product suggestion” → route → LLM + RAG product description
- “
Step 3: Parameter and Behavior Customization per Use Case
Now that the query is routed to the correct pipeline, it is important to tune parameters so responses align with the behavior a user expects. This is particularly necessary when using LLMs.
Core parameters to tune in an LLM are:
- Temperature
- Top-p
- Max tokens
- Frequency/presence penalties
I have covered these in my previous article, under the section titled Parameter Tuning. This step naturally integrates with orchestration since each routed intent of a task can load a predefined parameter set.
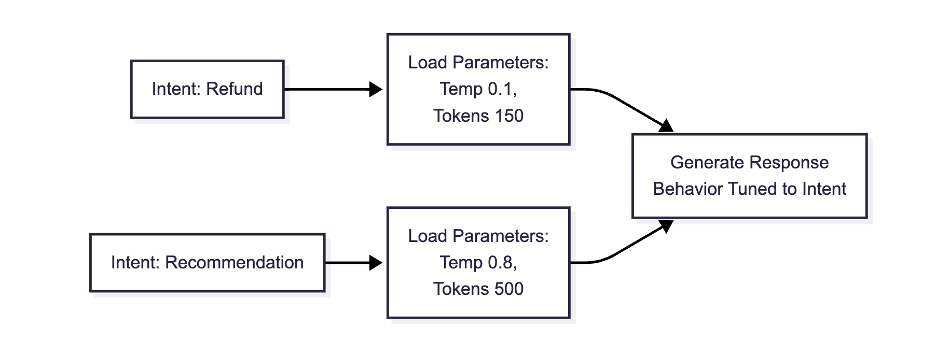
- Each intent can have its own LLM settings:
- Factual → temperature 0.1, short token limit
- Creative → temperature 0.8, long token limit
- Examples:
- Compliance queries → strict, low randomness
- Brainstorming → open, higher randomness
Step 4: Evaluation and Feedback Loops
After putting significant effort into creating this chatbot, it is important it is tested, not just for accuracy, but also for how well routing, orchestration, and parameter tuning work.
Below is a simple ordering of testing that can be done. Future readings will consist of a deep dive exclusively into testing.
Testing per Intent
Every intent must be tested, this means testing precision, recall, accuracy, grounding score, and latency. More on each of these testing parameters is available in my previous article in the Testing section.
Routing Accuracy
Routing accuracy is one of the most important metrics for evaluating an intent-first design. It measures how often a query is routed to the correct task without human intervention. This metric should be tested on at least 100 queries and then monitored continuously in production.
In most digital transformations, organizations invest in chatbots expecting the system to resolve more than 85% of user issues autonomously. High routing accuracy is therefore essential to proving the chatbot’s effectiveness.
Escalation and User Satisfaction
Escalation rate refers to the number of times an issue must be escalated to a human to be resolved. This differs from routing accuracy, as it indicates how much knowledge our chatbot possesses. A rising escalation rate can indicate new customer problems, gaps in the chatbot’s knowledge, or increased complexity in known issues — all of which may require updates in orchestration logic or parameter tuning
Continuous Feedback
Misrouted queries aren't purely negative; rather, they become a valuable dataset for improving the chatbot.
For a small batch (10–20 misrouted queries), you can often correct them by grounding the model with RAG at inference time. However, if misrouting becomes frequent or persistent, it’s a signal that the intent model or LLM needs fine-tuning for that specific task.
Conclusion
Overall, designing multi-use-case chatbots is not just about adding more functionality; it’s about ensuring each task continues to perform optimally and cost-effectively as complexity increases. The key lies in orchestrating these systems efficiently while keeping intent routing, context management, and parameter tuning aligned to the purpose of each task.
Throughout this article, we examined how intent recognition underpins understanding what a user really wants, how orchestration and context management ensure the right path is taken, and how parameter tuning and feedback loops continuously refine performance. When done correctly, these layers allow a chatbot to be not just functional, but scalable and reliable.
Opinions expressed by DZone contributors are their own.
Comments