Designing for Empathy: Human-Centered AI Patterns for Real Systems
This is a practical guide for developers to build empathy-aware AI with edge sensing, policy-driven actions, audit trails, and real-world app patterns.
Join the DZone community and get the full member experience.
Join For FreeAbstract
Empathy-aware interaction is becoming a core requirement as AI systems mediate healthcare, education, and public services. For software teams, the challenge is not “make the bot nice,” but: how do we design and ship systems that sense user context, adapt with calibrated empathy, and still remain private, auditable, and predictable?
This article proposes a practice-oriented framework that unifies affect sensing, context modeling, policy-based adaptation, and transparent explanations into a deployable pipeline for human–machine systems. The contributions for developers are:
- A capability taxonomy across perception, reasoning, action, transparency, and learning.
- A reference architecture with edge inference, a privacy gateway, a policy engine, a UX adapter, and an audit bus (Figure 1).
- Two concrete application patterns—telemedicine intake and adaptive tutoring—with repeatable metrics and implementation notes (Figures 2 and 3).
- A risk/guardrail catalog for bias, over-trust, and consent, plus a simple empathy control loop (Figure 4) that fits into existing backends.
Evaluation on small cohorts shows that empathy-aware policies can improve trust, disclosure quality, and task efficiency with minimal latency overhead when implemented with explicit guardrails. The goal is to give engineering teams practical building blocks, not a black-box “empathy API.”
Introduction: Empathy as an Engineering Property
In this article, empathy is treated as a system property, not a vague feeling. An empathetic AI system should be able to:
- Detect: sense signals from text, voice, or interaction patterns.
- Infer: estimate user state with uncertainty, not hard labels.
- Decide: choose bounded actions from an approved policy.
- Act: adjust tone, pacing, or scaffolding in the UI.
- Explain: tell the user why it did something, at the right level.
- Learn: update policies and models slowly and audibly over time.
Think of this as a control loop:
detect → infer → decide → act → explain → learn
—instrumented with telemetry and audit events at each step (Figure 4 later).
Real deployments often fail in three predictable ways:
- Opaque inference that encourages over-trust (“the model seems confident, so users assume it’s right”).
- Runaway personalization where the UI becomes unpredictable and hard to debug.
- Privacy friction that kills consent quality or blocks useful sensing.
The patterns in this article address those problems using:
- Edge inference where possible.
- Layered consent and data minimization.
- A policy engine between models and actions.
- Structured explanations and an audit bus for every adaptation.
The rest of the article walks through capabilities, architecture, two application patterns, and a concrete risk/guardrail playbook.
Capability Taxonomy for Empathy
From a developer’s perspective, “empathetic behavior” can be decomposed into five capabilities.
Perception
What signals can the system see?
- Textual cues: hedging (“maybe”, “not sure”), frustration markers, repair phrases (“sorry, I meant…”).
- Acoustic cues (when allowed): prosody, speaking rate, pause density.
- Interaction cues: rapid backtracking, long idle times, repeated errors, rage clicks, abandon events.
Key engineering points:
- Always represent uncertainty (confidence scores, timing windows).
- Prefer respectful sensing:
- Opt-in, clearly visible indicators (e.g., “Voice tone analysis enabled”).
- Local feature extraction with raw audio/video staying on device.
Reasoning
Perception features are fused over time into estimates like:
-
Frustration, confusion, confidence, engagement, friction.
Implementation hints:
- Start with simple temporal models (sliding windows, exponential moving averages, small RNNs).
- Output distributions, not single labels, and include an explicit
"unknown"or"insufficient_signal"state.
Action
Empathetic actions should be bounded:
- Choosing from predefined tone sets and microcopy variants.
- Adjusting pacing (slower turn-taking, confirmation prompts).
- Escalation logic (hand off to a human, show “call us” option).
Actions should be:
- Rate-limited (no mood whiplash).
- Policy-driven, not arbitrary model outputs.
Transparency
Users should have a sense of why the system responded the way it did.
Patterns:
-
Short rationales:
“I might be misreading this, but it sounds like this is frustrating. Would you like to see a simpler explanation?”
-
“Why this?” links that reveal inputs in aggregate (e.g., “based on your last few answers and the time spent on this step”), without exposing raw sensitive data.
Learning
Empathy policies should evolve slowly and be easy to roll back.
- Store policy versions and model versions in logs.
- Run drift monitors on:
- Prediction distributions.
- Subgroup performance (dialects, screen readers, etc.).
- Have a clear process for rolling back to a neutral policy if something goes wrong.
Reference Architecture (Figure 1)
Figure 1 shows a deployable architecture that many stacks can implement.
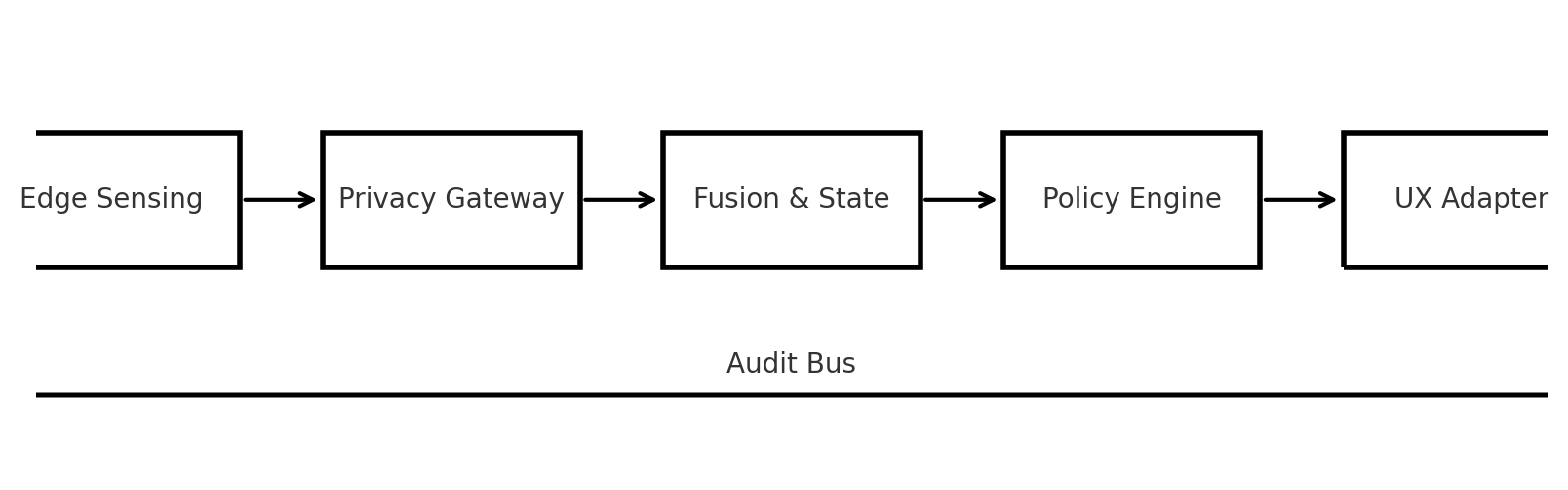
The main components are:
Edge Sensing
- Local extraction of low-level features (pitch, speaking rate, pause density, keystroke, and task telemetry in tutoring).
- When feasible, raw audio/video never leaves the device; only aggregated features or states are sent upstream.
Privacy Gateway
- Handles consent prompts, scopes, and retention choices.
- Performs redaction/tokenization and strips identifiers before events hit core services.
Fusion and State Service
- Temporal model that outputs a state vector like:
JSON
{ "frustration": { "mean": 0.7, "confidence": 0.6 }, "engagement": { "mean": 0.4, "confidence": 0.8 }, "state": "frustrated_low_confidence" - Runs as a microservice or lightweight edge model.
Policy Engine
- Maps state → actions using declarative rules:
YAML
- state: frustrated_low_confidence actions: tone: "reassuring" hint_depth: "high" offer_handoff: true constraints: max_changes_per_session: 3 - Policies are versioned; diffs are logged for audits.
UX Adapter
- Injects microcopy, pacing, and flows into the host app.
- Respects user overrides (“Don’t adapt tone”, “Show standard view”).
Audit Bus
- Emits non-PII events for each loop:
JSON
{ "sessionId": "anon-123", "modelVersion": "v3.1", "policyVersion": "p5", "state": "frustrated_low_confidence", "actions": ["tone:reassuring", "hint:extra"], "userOverride": false } - Feeds analytics, QA, ethics review, and drift monitoring.
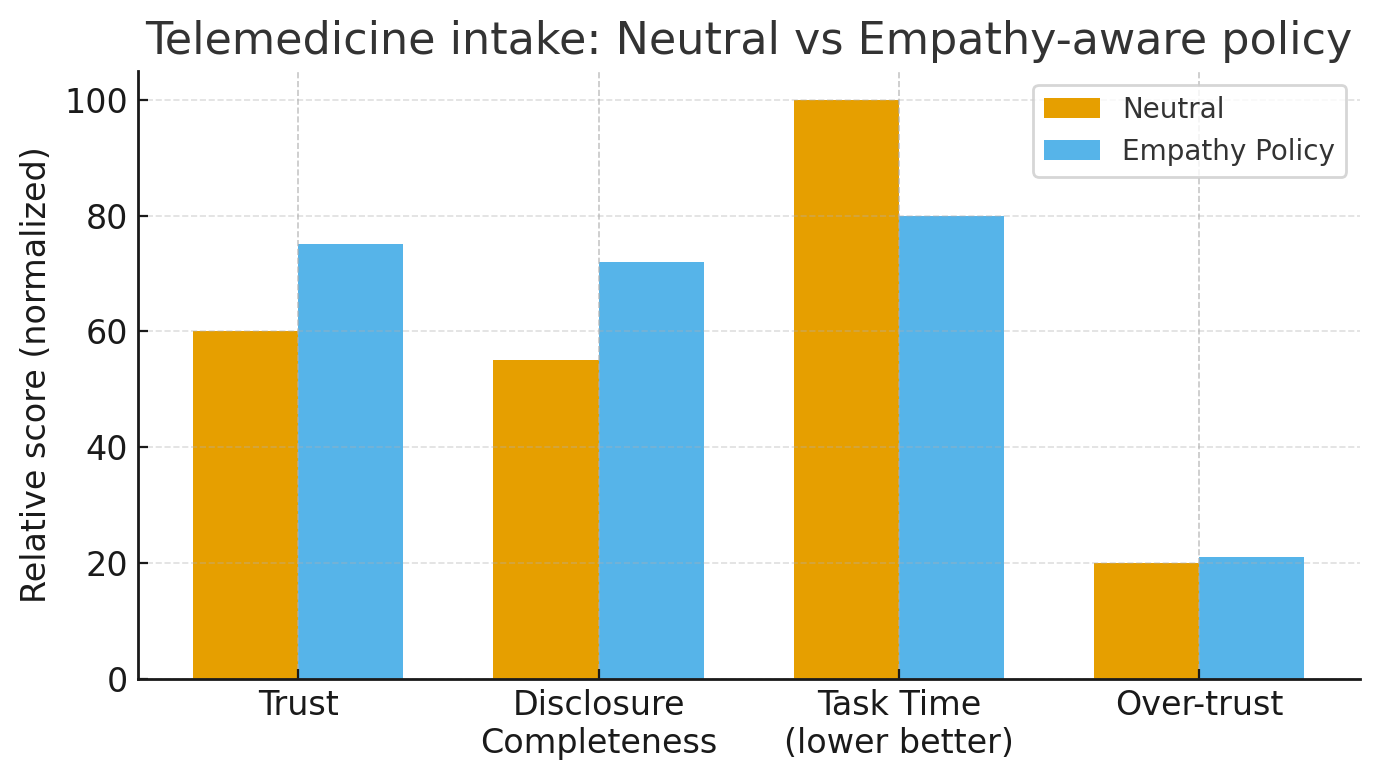
Telemedicine Intake Pattern (Figure 2)
Scenario
A dermatology intake chatbot collects symptoms and photos before a human clinician reviews. The goal: better disclosure quality and lower time-to-completion without increasing over-trust.
Two policies are compared:
- Neutral: standard questions, neutral tone.
- Empathetic: same questions, but tone and pacing adapt using the pipeline above.
Metrics
- Task time (seconds).
- Disclosure completeness (clinician-scored rubric).
- Calibrated trust (trust vs perceived competence).
- Over-trust (willingness to accept high-risk advice without human confirmation).
- Workload (e.g., NASA-TLX subscales).
Findings (Conceptual)
In a small pilot (n≈60):
- Empathetic policy improved normalized disclosure and reduced completion time.
- Over-trust remained roughly constant vs neutral.
- Participants rated explanations as clearer and more respectful.
Implementation Notes for Developers
- Use disambiguation prompts when signals are sparse: “I’m not sure I understood — do you want to focus on pain, itching, or something else?”
- Keep consent short but layered: a single sentence plus “Learn more” link.
- When uncertainty is high, fall back to neutral rather than guessing emotional state.
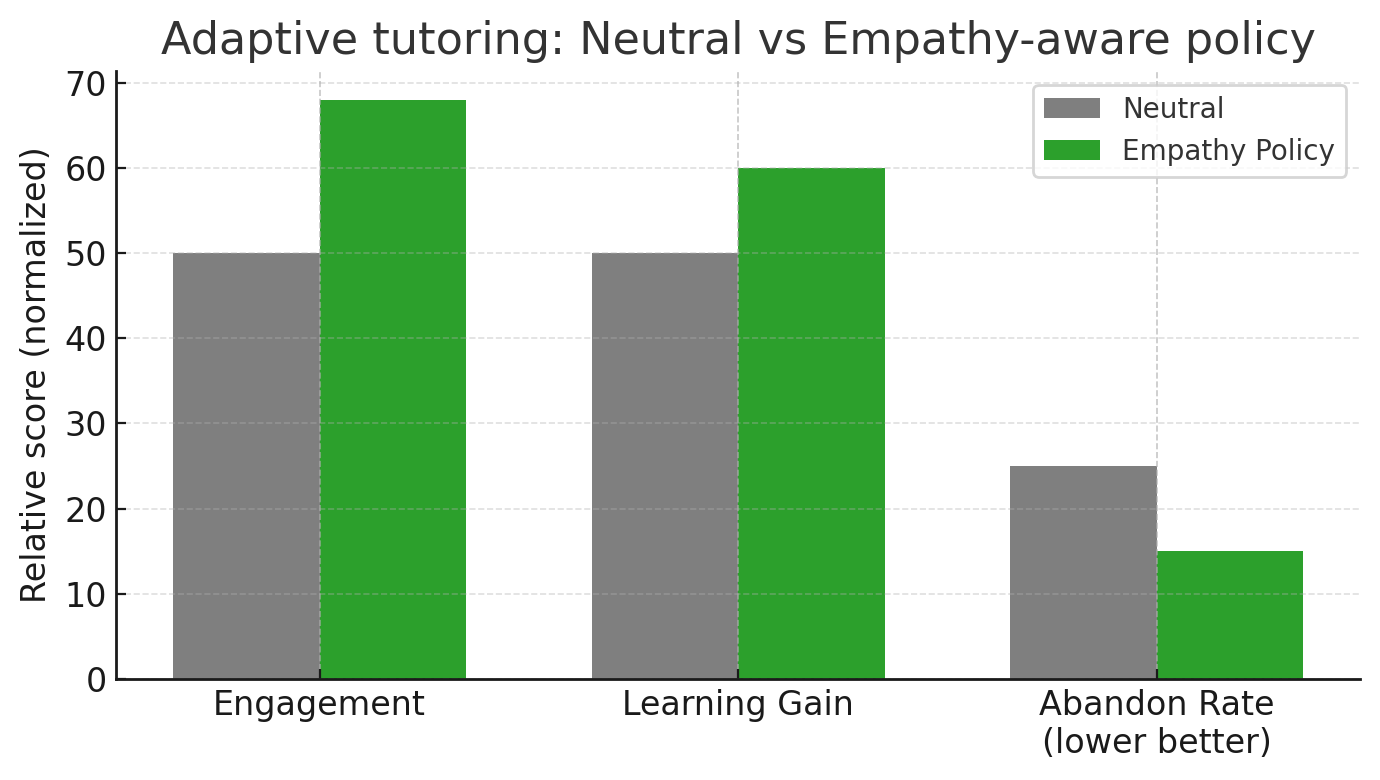
Adaptive Tutoring Pattern (Figure 3)
Scenario
An algebra tutoring system adjusts hints and pacing based on frustration and confidence estimates.
- Inputs: answer correctness history, time per step, backtracking, mild linguistic cues.
- Outputs: state categories like
confused_low_confidenceorbored_high_confidence.
Policy Examples
- If
confused_low_confidence:- Use gentler tone and more scaffolding.
- Show one worked example.
- Ask for a confirmation before moving on.
- If
bored_high_confidence:- Offer challenge problems sooner.
- Tighten hints and skip obvious steps.
Outcomes (Conceptual)
In a pilot (n≈80):
- Higher engagement (time on task without idle).
- Modest post-test gains.
- Fewer unnecessary hints.
Ablation tests showed:
- Removing transparency (“why this hint?”) reduced trust and increased friction.
- Removing pacing control increased abandon rates.
Design Guidelines for Empathy-Aware Systems
Summarizing patterns that generalize across domains:
- Sense respectfully
- Opt-in; visible indicators; easy opt-out.
- Prefer feature extraction at the edge.
- Expose uncertainty
- Use phrases like “might be wrong” and show ranges instead of absolute claims.
- Bound adaptation
- Approved tone sets and message templates.
- Rate-limit changes and always allow human override.
- Layer explanations
- Short rationale + expandable detail, both in plain language.
- Inclusive calibration
- Test across dialects, assistive technologies, and cultural idioms.
- Track subgroup error budgets in monitoring dashboards.
- Monitor trust and friction over time
- Include trust, confusion, and abandon metrics in your standard observability stack.
Risks and Guardrails
Empathy features can backfire without explicit guardrails.
- Bias
- Train with balanced samples; measure subgroup performance.
- Provide a neutral fallback when confidence drops below a threshold.
- Privacy
- Avoid storing raw audio/video where possible.
- Apply purpose-binding and retention limits at the privacy gateway.
- Over-trust
- Use a neutral tone for low-confidence states.
- Always expose a clear “verify with a human” path.
- For high-risk decisions, require explicit confirmation.
- Misclassification
- Support a “not sure” state and ask clarification questions instead of forcing an interpretation.
- Safety
- Have a hard escalation path to a human operator.
- Rate-limit persuasive patterns and sensitive topics.
A simple way to track this is to maintain a risk register with: risk type, indicators, mitigation, owner, and SLA for response.
Reproducibility and Evaluation Playbook
When documenting an empathy-aware system, include:
- Sensors, sampling rates, and feature sets.
- Training sources and data statements.
- Model architecture and size.
- Policy constraints (what actions are allowed and disallowed).
- Explanation styles used in production.
- User demographics and subgroup metrics.
- Ablations (what happens when transparency or pacing is removed).
- Links to scripts or anonymized logs where policies allow.
This makes it easier for other teams — and future you — to audit and extend the system.
Empathy Control Loop (Figure 4)
Putting everything together, the controller loop looks like this:
detect → infer → decide → act → explain → learn
Each cycle emits an event onto the audit bus with:
- Model version
- Policy version
- Inferred state and confidence band
- Actions taken
- Whether a user override occurred
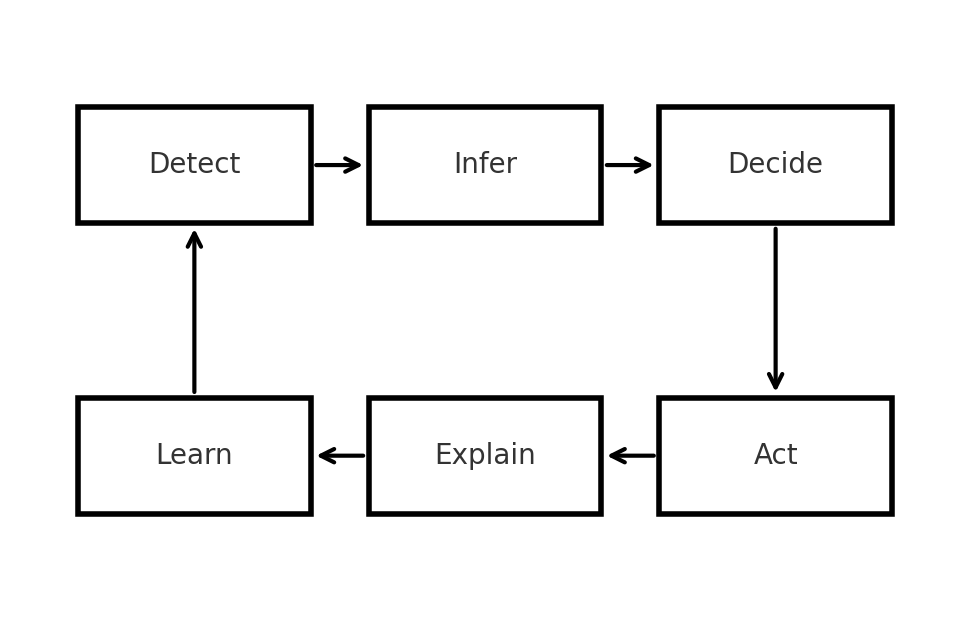
This loop fits naturally into existing backend architectures (microservices, event buses, monitoring stacks) without requiring a separate “empathy platform.”
Related Work and Conclusion
This work builds on ideas from:
- Affective computing (perception and affect modeling).
- Explainable AI and HCI (transparency patterns).
- Trust calibration in human–machine systems (preventing over-trust).
The main novelty for software teams is the deployable framing: a privacy gateway, a policy engine between models and actions, layered consent, and an audit bus, all expressed in terms that can be implemented today.
Empathy can be designed, measured, and audited. With bounded adaptation, layered transparency, inclusive calibration, and on-device privacy, empathy-aware systems can improve outcomes in domains like telemedicine and tutoring without turning into unaccountable black boxes.
Opinions expressed by DZone contributors are their own.
Comments