Dissecting the Disruptor: Demystifying Memory Barriers
Join the DZone community and get the full member experience.
Join For FreeMy recent slow-down in posting is because I've been trying to write a post explaining memory barriers and their applicability in the Disruptor. The problem is, no matter how much I read and no matter how many times I ask the ever-patient Martin and Mike
questions trying to clarify some point, I just don't intuitively grasp
the subject. I guess I don't have the deep background knowledge
required to fully understand.
So, rather than make an idiot of myself trying to explain something I
don't really get, I'm going to try and cover, at an abstract /
massive-simplification level, what I do understand in the area. Martin
has written a post going into memory barriers in some detail, so hopefully I can get away with skimming the subject.
Disclaimer: any errors in the explanation are completely my own, and no
reflection on the implementation of the Disruptor or on the LMAX guys who actually do know about this stuff.
What's the point?
My main aim in this series of blog posts is to explain how the Disruptor
works and, to a slightly lesser extent, why. In theory I should be
able to provide a bridge between the code and the technical paper by talking about it from the point of view of a developer who might want to use it.
The paper mentioned memory barriers, and I wanted to understand what they were, and how they apply.
What's a Memory Barrier?
It's a CPU instruction. Yes, once again, we're thinking about CPU-level
stuff in order to get the performance we need (Martin's famous
Mechanical Sympathy). Basically it's an instruction to a) ensure the
order in which certain operations are executed and b) influence
visibility of some data (which might be the result of executing some
instruction).
Compilers and CPUs can re-order instructions, provided the end result is
the same, to try and optimise performance. Inserting a memory barrier
tells the CPU and the compiler that what happened before that command
needs to stay before that command, and what happens after needs to stay
after. All similarities to a trip to Vegas are entirely in your own
mind.
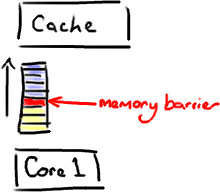
The other thing a memory barrier does is force an update of the various CPU caches - for example, a write barrier will flush all the data that was written before the barrier out to cache, therefore any other thread that tries to read that data will get the most up-to-date version regardless of which core or which socket it might be executing by.
What's this got to do with Java?
Now I know what you're thinking - this isn't assembler. It's Java.
The magic incantation here is the word volatile (something I felt was never clearly explained in the Java certification). If your field is volatile, the Java Memory Model inserts a write barrier instruction after you write to it, and a read barrier instruction before you read from it.

This means if you write to a volatile field, you know that:
- Any thread accessing that field after the point at which you wrote to it will get the updated value
- Anything you did before you wrote that field is guaranteed to have happened and any updated data values will also be visible, because the memory barrier flushed all earlier writes to the cache.

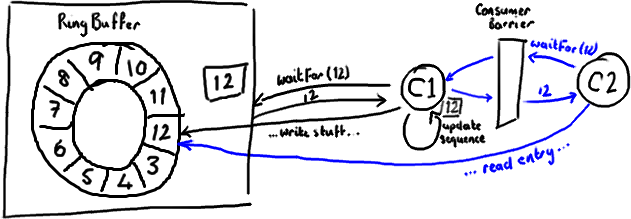
So, if your downstream consumer (C2) sees that an earlier consumer (C1) reaches number 12, when C2 reads entries up to 12 from the ring buffer it will get all updates C1 made to the entries before it updated its sequence number.
Basically everything that happens after C2 gets the updated sequence number (shown in blue above) must occur after everything C1 did to the ring buffer before updating its sequence number (shown in black).
Impact on performance
Memory barriers, being another CPU-level instruction, don't have the same cost as locks - the kernel isn't interfering and arbitrating between multiple threads. But nothing comes for free. Memory barriers do have a cost - the compiler/CPU cannot re-order instructions, which could potentially lead to not using the CPU as efficiently as possible, and refreshing the caches obviously has a performance impact. So don't think that using volatile instead of locking will get you away scot free.
You'll notice that the Disruptor implementation tries to read from and write to the sequence number as infrequently as possible. Every read or write of a volatile field is a relatively costly operation. However, recognising this also plays in quite nicely with batching behaviour - if you know you shouldn't read from or write to the sequences too frequently, it makes sense to grab a whole batch of Entries and process them before updating the sequence number, both on the Producer and Consumer side. Here's an example from BatchConsumer:
long nextSequence = sequence + 1;
while (running)
{
try
{
final long availableSequence = consumerBarrier.waitFor(nextSequence);
while (nextSequence <= availableSequence)
{
entry = consumerBarrier.getEntry(nextSequence);
handler.onAvailable(entry);
nextSequence++;
}
handler.onEndOfBatch();
sequence = entry.getSequence();
}
...
catch (final Exception ex)
{
exceptionHandler.handle(ex, entry);
sequence = entry.getSequence();
nextSequence = entry.getSequence() + 1;
}
}
(You'll note this is the "old" code and naming conventions, because this is inline with my previous blog posts, I thought it was slightly less confusing than switching straight to the new conventions).
In the code above, we use a local variable to increment during our loop over the entries the consumer is processing. This means we read from and write to the volatile sequence field (shown in bold) as infrequently as we can get away with.
In Summary
Memory barriers are CPU instructions that allow you to make certain assumptions about when data will be visible to other processes. In Java, you implement them with the volatile keyword. Using volatile means you don't necessarily have to add locks willy nilly, and will give you performance improvements over using them. However you need to think a little more carefully about your design, in particular how frequently you use volatile fields, and how frequently you read and write them.
PS Given that the New World Order in the Disruptor uses totally different naming conventions now to everything I've blogged about so far, I guess the next post is mapping the old world to the new one.
From http://mechanitis.blogspot.com/2011/08/dissecting-disruptor-why-its-so-fast.html
Opinions expressed by DZone contributors are their own.
Comments