AWS Redshift Data Sharing: Unlocking the Power of Collaborative Analytics
In this article, learn about AWS Redshift data sharing, a robust tool that enhances collaboration, reduces costs, and simplifies data governance.
Join the DZone community and get the full member experience.
Join For FreeWhat Is AWS Redshift Data Sharing?
As a data engineer, most of my time will be spent constructing data pipelines from source systems to data lakes, databases, and warehouses. In the cloud world, the databases/warehouses are usually isolated in a private subnet in a VPC, and sharing the data will be a challenge. One of the pain points is to have this data distributed to several teams in the organization. Data can be shared by exporting into files, but this increases the concerns of security, data duplication, and maintenance of these export pipelines.
I was delighted to find that we have a utility in AWS Redshift that will let you share the data between two Redshift clusters without building any ETL infrastructure. AWS Redshift data sharing allows you to securely share live, read-only data between different Redshift clusters within or across AWS accounts and regions. It eliminates the need for data duplication and helps multiple stakeholders access the same dataset, allowing different departments, teams, or external partners to collaborate and derive insights from shared data. By sharing specific databases, schemas, tables, or views from the Producer Cluster to one or more Consumer Clusters, organizations can significantly reduce the complexity of their data pipelines.
In this architecture:
- The Producer Cluster creates and manages the data share.
- Source tables in the producer cluster are added to the data share.
- The producer grants access to one or more Consumer Clusters.
- The consumer clusters access the shared data in real time, without duplication.
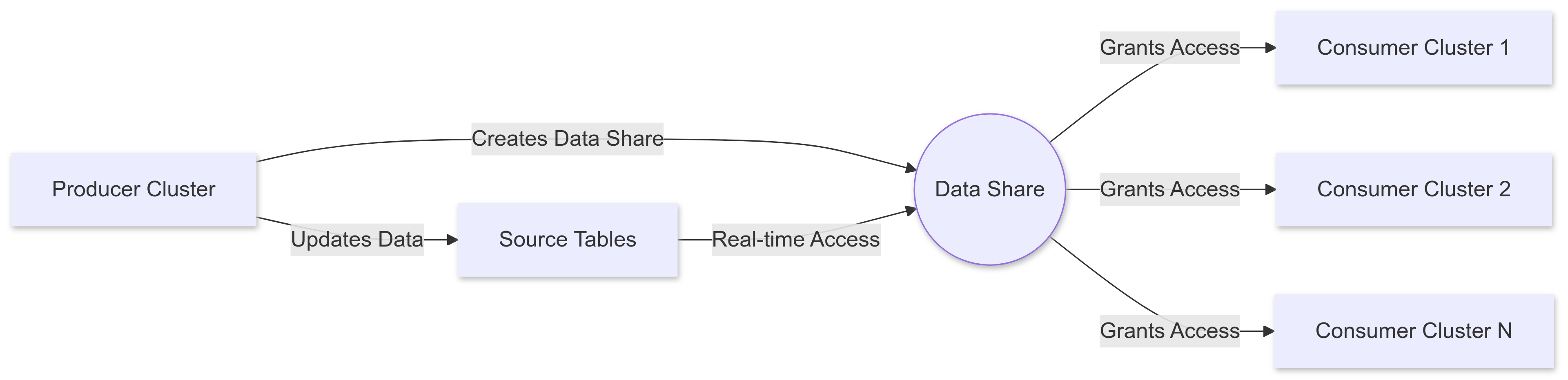
Diagram of data share between AWS Redshift clusters
Requirements for AWS Redshift Data Sharing
Before you start creating a data share, there are several prerequisites to be aware of as of writing this article:
- RA3 node type: Your Redshift cluster must run on RA3 nodes, which decouple storage from compute, optimizing data management and scalability.
- Cluster version: The Redshift cluster version must be 1.0.74503 or later.
- Enhanced VPC routing: This feature must be enabled to ensure secure data flow between your cluster and other AWS services.
- IAM permissions: Appropriate permissions are necessary for creating and managing data shares.
Prerequisites: IAM Permissions
Your IAM role should include the following permissions to create and manage data shares:
redshift:CreateDataShareredshift:AlterDataShareredshift:DeleteDataShareredshift:DescribeDataShareredshift:AuthorizeDataShareredshift:RevokeDataShare
Step-by-Step Guide: Creating a Data Share in AWS Redshift
Here is a detailed walkthrough for creating and managing a data share:
Step 1: Create the Data Share
CREATE DATASHARE my_datashare;This creates an empty data share.
Step 2: Add Objects to the Data Share
ALTER DATASHARE my_datashare ADD SCHEMA public;
ALTER DATASHARE my_datashare ADD TABLE public.customers;
ALTER DATASHARE my_datashare ADD ALL TABLES IN SCHEMA sales;You can add entire schemas, specific tables, or all tables within a schema to the data share.
Step 3: Grant Access to Consumers
GRANT USAGE ON DATASHARE my_datashare TO NAMESPACE '1234567890';Replace '1234567890' with the consumer's AWS account ID. This grants access to the shared data.
Step 4: (Optional) Modify Data Share
You can add or remove objects from the data share dynamically:
ALTER DATASHARE my_datashare REMOVE TABLE public.sensitive_data;Step 5: Consumer Cluster Creates Database From Data Share
CREATE DATABASE shared_data FROM DATASHARE my_datashare OF NAMESPACE '0987654321';This links the data share to the consumer cluster, allowing access to the shared data.
Step 6: Grant Access to Users/Groups on the Consumer Cluster
GRANT USAGE ON DATABASE shared_data TO GROUP analysts;
GRANT SELECT ON ALL TABLES IN SCHEMA shared_data.public TO GROUP analysts;This gives specific users or groups the ability to query the shared data.

Flow chart of data share build between AWS Redshift Clusters
Benefits of AWS Redshift Data Sharing
AWS Redshift data sharing offers numerous advantages for organizations:
- Real-time access: Consumers can query live data without delays, enabling faster decision-making.
- Reduced data duplication: Sharing data eliminates the need to replicate it, minimizing storage costs and maintaining data integrity.
- Simplified governance: Producers control access to shared data, ensuring compliance with regulations.
- Enhanced collaboration: Teams across departments or organizations can easily access and analyze the same datasets.
- Cross-account and cross-region sharing: Data can be shared securely across accounts and regions.
- Cost efficiency: Consumers can query data without adding to the producer’s compute load.
Best Practices for Redshift Data Sharing
- Plan data shares strategically: Design data shares based on consumer needs.
- Enforce access controls: Use precise permission settings to restrict access to relevant datasets.
- Monitor data usage: Regularly track data share usage to optimize performance and ensure efficient sharing.
- Maintain clear documentation: Keep detailed records of what is shared and with whom to ensure transparency and security.
Monitoring Data Shares
You can monitor data shares using system views like SVV_DATASHARES, SVV_DATASHARE_CONSUMERS, and SVV_DATASHARE_OBJECTS. Here’s a query example:
SELECT ds.share_name, ds.share_owner, ds.source_database,
dsc.consumer_account, dso.object_name, dso.object_type
FROM SVV_DATASHARES ds
JOIN SVV_DATASHARE_CONSUMERS dsc ON ds.share_name = dsc.share_name
JOIN SVV_DATASHARE_OBJECTS dso ON ds.share_name = dso.share_name
ORDER BY ds.share_name, dso.object_name;
Conclusion
AWS Redshift data sharing is a robust tool that enhances collaboration, reduces costs, and simplifies data governance. By implementing data sharing, organizations can unlock the full potential of their data infrastructure, promoting faster decision-making and innovation across teams. With careful planning, monitoring, and adherence to best practices, Redshift data sharing can be a game-changer in your organization’s data strategy.
By leveraging these capabilities, your organization can foster a more collaborative, data-driven environment and stay ahead in today’s competitive, data-intensive world.
Opinions expressed by DZone contributors are their own.
Comments