Does Datameer Support a Full Big Data Analysis Process?
Join the DZone community and get the full member experience.
Join For FreeOver the last few days, I had the chance to test Datameer analytics solution (das). Das is a platform for Hadoop which includes data source integration, an analytics engine, and visualization functionality.
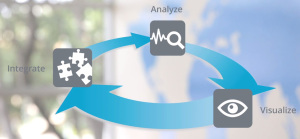
This promise of a fully integrated big data analysis process motivated me to test the product.
It really includes all required functionality for data management or ETL, it provides standard tools to analyze data and there are nice ways to build visualization dashboards. For example, there are connectors for Twitter, IMAP, HDFS, or FTP available. All menus and processes are self-explaining and the complete interface is strongly Excel or spreadsheet oriented. If you are familiar with excel you can do the analyses on your big data out of the box.
For a fast on-the-fly analysis performance you only work with a subset of your data and the analyses you store will then be automatically transformed into a kind of procedure. In the end – or according to a schedule you set – you “run” the analyses on your big data: Das collects the latest data for you, Das creates MapReduce jobs in the background, and updates all your spreadsheets and visualizations. To close the analysis circle you can use the connectors to write your results back to HDFS or a database such as HBase or many more technologies.
Analytics the Way You Need Them
There are a lot of ways that Datameer can prove useful to you, and you don’t want to discount that fact. You will discover that it is likely the case that Datameer is a great way to display a large-scale amount of data in a format that is digestible and useful to you.
We can only absorb so much data as individual human beings, but we can certainly use the information that we receive to make important decisions about our business, our products, and the future experiences that our customers will have as a result. Thus, it makes sense that there are many people who want to use Datameer as a means of getting this done. If you have felt what it is like to see all of your data on a big spreadsheet and be able to visualize what it looks like coming together, then you know that you need Datameer and similar products to help you get the results that you really need.
Das is really designed for big data. If you test it with small data you will be frustrated by the performance – the overhead of creating MapReduce jobs dominates in this situation. But as soon as you start with real big data analyses this overhead gets negligible and das is taking over a lot of your programming work.
My Test Infrastructure
The following figure provides a nice overview of the Datameer infrastructure. Das supports many data sources, it runs on all Hadoop distributions, it provides a rest API and you can add plugins as connectors for other modeling languages such as r (#rstats).
I tested das version 3.1.2 running on our MapR Hadoop cluster version 3.0.2. After getting the latest package version from Datameer support the installation was straightforward and it worked out of the box. Thanks to Datameer for providing a full test license. There are several online tutorials and videos available and there are some tutorial apps. Apps are another great feature of Datameer. You can download Datameer apps which include connectors, workbooks, and visualizations for different analysis examples. And you can create your own app from your analyses and share them with your colleagues or the community.
My Test Data And Analyses
I tested das with the famous “airline on-time performance” data set consisting of flight arrival and departure details for all commercial flights within the USA, from October 1987 to April 2008. I downloaded all the data (including supplements) to MapR FS, created connectors for the data, and imported the data into a workbook.
In the workbook I tested many classical statistical counting analyses:
Grouping functionality for the airports and counting the number of flights
Grouping for the airlines and calculating different statistics as mean values for the air time
Using joins to add additional information like the airline name to the airline identifier
Doing sorts to extract the most interesting airports depending on different measures
I am not an Excel expert. so it took me some time to get used to this low-level process of doing analysis on spreadsheets. But in the end, it is a very intuitive process of creating analyses.
Every new analysis will be available in a new tab in your workbook. There are several nice functionalities to support your work. For example, there is a “sheet dependencies” overview which provides information about the dependencies between sheets.
Apart from the classical analyses, das provides some data mining functionality. It is called “smart analytics”. So far, it covers k-means clustering, decision trees, column dependencies, and recommendations. It works out of the box but is not yet on the level to be satisfying for real analyses. e.g. For k-means clustering, there is no support for choosing the right number of clusters (k) and you can not switch between different distance functions (default is euclidean distance).
Finally, I visualized all my results in a nice “infographic”. There are many different visualization tools and parameters available. After playing around with the settings you can create a nice dashboard and share it with your colleagues.
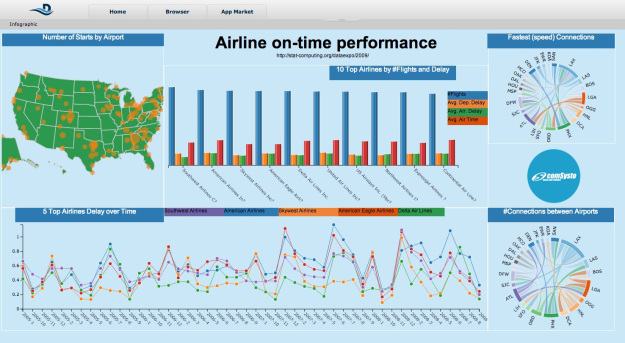
Please be aware that the complete data set is about 5 GB. Importing the data set takes about 30 minutes and running the workbook took more than 3h in my case. In the end, I split my analyses into several workbooks to improve the feasibility.
Summary
It was easy to get started with Datameer analytics solution (das). It is definitely a great tool to do big data analyses without any detailed Hadoop or big data knowledge. Furthermore, it covers many use cases and provides all required functionality for your daily analysis process. However, as soon as your analyses get more complex, the limitations of Datameer become apparent and you will probably look for a more powerful toolset or start implementing your big data analyses directly on Hadoop.
Finally, Datameer supports many steps in the big data analysis process, it works efficiently and the usability is straightforward. But big data is more than ETL, data analysis and visualizing the results. You should never forget to think about your use case and the business value that you want to extract from your data. In the end, this is what should guide you in choosing the tools and/or implementations to use.
Published at DZone with permission of Comsysto Gmbh. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments