Code Your Architecture Structure
There are lots of different opinions out there on software architecture structures and views. This article tries to clarify them by proposing a simplification.
Join the DZone community and get the full member experience.
Join For FreeWhen you read about software architecture structures and views, you will find different opinions from different authors. And what is worse, they use the same terms for explaining different concepts, which just contributes to the general confusion.
This article just reviews these concepts and tries to clarify them proposing a simplification.
Let’s take the two current models that I consider most relevant right now: the SEI Model and the C4 Model. Very briefly, the SEI Model usually described in the software architecture books from the Software Engineering Institute (SEI), like Software Architecture in Practice, define three structures:
- Module
- Components & Connectors
- Allocation
As the authors describe, Modules are the way to partition a system. Each module is assigned with specific responsibility. They say that it could be classes in an OO language or it could be layers (“What is a layer and how is that represented in code?”, I ask to myself!). In the Components & Connectors structure, components are runtime elements, they can be stopped and started, and connectors are the way they communicate (HTTP, SOAP, Socket, etc.). And finally, in their Allocation structure, you have modules assigned to teams and Components assigned to hardware.
In the C4 Model, you have the Classes, which are represented by class diagrams, then Components, which are logical grouping of classes, behind a higher level contract. Note here the difference, unfortunately. In the SEI Model, Components are runtime elements while here are static elements. Then, you have the Containers (not Docker), which are the runtime elements, similar to the Component & Connector structure from the SEI Model. And finally, you have the Context, which you use to represent the system and their external dependencies.
Let’s review the following picture which shows different structures from the same tiny application called Calc, and discuss what we see there.
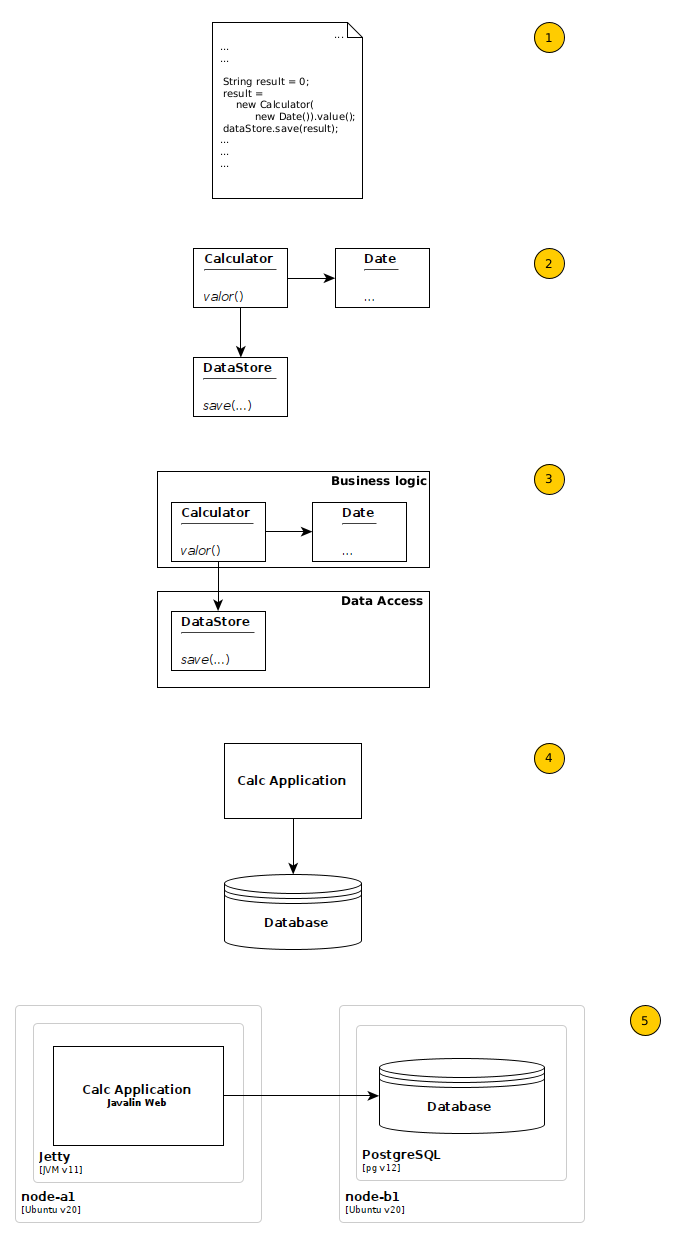
The image starts with source code, the most concrete representation of software. We create software systems using programming languages where each one has a defined syntax and semantics and belong to a specific paradigm. If you use an object oriented programming language, then you can describe the design of your application using a class diagram, which is represented by the image number 2. This corresponds to the Classes abstraction of the C4 Model and the Modules structure of the SEI Model. Then, on image number 3, let’s say we have a layered diagram where you have some classes grouped together with a specific purpose, like business responsibilities depending on classes grouped by another purpose. And what is more important, the dependencies can only go from business classes to data access classes, but not on the other way. This is an architecture rule. This one corresponds to the Module structure of the SEI Model and the Component abstraction of the C4 Model.
But what is a Layer? Do we have a syntactical construction to represent the Business Logic box and the Data Access box as we do have with classes? The diagrams in this category or abstraction, which can be found in the literature as: layered, modular, components, etc., is the one that usually causes us more confusion or the one that we usually invent to hide our reality. I mean, we often show stakeholders nice boxes and arrows created with a diagram tool, but source code is a mess, it’s spaghetti, it's a big ball of mud.
And why does this happen? Is it because we usually have pressure from the business to come up with releases every two or three weeks?
This occurs mainly because we don't know that we have to find first a syntactical construction in the programming language that we are using that we can use to build those business logic and data access boxes. Most mainstream programming languages like PHP, C#, Ruby, Java, etc., provide namespaces, packages, or modules constructions to group classes. Use them!
After that, you have the hard job to decide how to organize the classes. Are you going to group them horizontally (layers, technical concerns)? Are you going to group them vertically (by functionality, by modules)? Are you going to group them because they are reused together (CRP Common Reuse Principle by Uncle Bob) or because they change together when there are new requirements (CCP Common Closure Principle by Uncle Bob)? There are several ways of organizing classes and there are several architecture styles (that belong to this abstraction), like modular, layered, hexagonal or clean, which can be studied in the book Coding an Architecture Style.
So, choose an organization, define how they will depend between them, and then enforce them on every commit. To say it in another way, define your architecture rules and enforce them. This will give you some clarity on where the changes will impact.
How can that be enforced? If you use a compiled programming language (C# or Java), it is pretty easy — just compile each the box independently. For example, you can compile the Data Access box (image number 3) represented in source code by a namespaces, packages or modules, isolated, without including business logic namespaces. If it compiles you are fine; if not, it is because you have an invalid dependency. Or, you can use a static analysis tool like ArchUnit in Java. Or, just use the fantastic Java Module system to organize your packages and classes, which will guarantee the rules defined. In the end, diagrams that belong to this abstraction should come from source code, so you won’t have to invent.
This cannot be ignored. This can not be part of your technical debt list. If ignored, in the near future, you will have to deal with a big ball of mud, which means that you won't have any idea where a change will impact.
Coming back then to our picture, we can see at image 4 software elements at runtime, which correspond to the Container abstraction of the C4 Model or the Components & Connectors of the SEI Model. And finally, at image 5, you can see a deployment diagram (allocation structure from the SEI Model).
So, to put it in a simple way, we have:
- Structures that map to source code abstraction or syntactical constructions (images 2 and 3).
- Structures that map to software elements at runtime (image 4).
- Structures that map software elements to physical (or virtual) hardware (image 5).
This article is an extraction from the book Coding an Architecture Style.
Opinions expressed by DZone contributors are their own.
Comments