Don't Make These Mistakes in AI Development
Developing a quality AI deployment is 90% in the prep. Here are 10 AI development mistakes you should be aware of to ensure you develop your very best AI model.
Join the DZone community and get the full member experience.
Join For FreeThe Proof Is in the Preparation
Training an AI model might sound easy: give a neural network some data and bam, you got yourself an AI. This is far from the truth and there are numerous factors that go into developing the right model for the right job.
Developing a quality AI deployment is 90% in the prep coupled with continuous iterations and constant monitoring. Successfully developing and implementing AI systems is a complex process fraught with potential pitfalls. These shortcomings can lead to suboptimal outcomes, inefficient use of resources, and even significant challenges.
Here are 10 AI development mistakes you should be aware of to ensure you develop your very best AI model:
- Poor Data Preprocessing and Poor Data Quality
- Inadequate Model Evaluation
- Inaccurate Alignment
- Ignoring Data Privacy
- Not Preparing for Real-Time Scaling
- Too Much or Too Little Training
- Training on Unrealistic Datasets
- Not Addressing or Accounting for Biases
- Overlooking Need for AI Model Understandability
- Neglecting Monitoring
Poor Data Preprocessing
There is nothing more important than the quality of the data you feed your model. Think about it; if an e-commerce company tried to develop a recommendation system for suggesting products to customers based on purchase history and behavior. If the quality of the data is unorganized and not conducive, things could go awry quickly.
Missing user data, noisy and error filled data, and un-updated data can deliver the wrong results. Customers may start receiving irrelevant product recommendations. leading to poor user experience and potentially lost sales not to mention the investment in the recommendation system development.
Preparing the data with the intention of high quality and organization can deliver much better results. Your model performance will reflect on the quality of data you feed it.
Inaccurate Model Evaluation
It goes without saying that apart from data comes choosing the right model. You can prep your data model but making sure to use the correct model and understanding which models are best for what purpose is essential to being a good AI developer.
For example, if a bank used a machine learning model to predict loan defaults on client account applications trained it based on the accuracy of historical clients. If the bank only used accuracy as the performance metric, it masks important flaws in future defaulters, accepting a probable number of potential defaulters without knowing it.
The bank’s model should use other performance metrics such as precision recall and F1-score. They could also deploy techniques like cross-validation and AUC-ROC analysis to identify how much the model is capable of distinguishing between classes (defaulters, non-defaulters).
Inaccurate Model Alignment
Developers commonly focus on optimizing models based on technical metrics such as accuracy, precision, recall, or F1-score. While these metrics provide an important measure of a model's performance, they do not always correlate directly with business metrics such as revenue generation, cost savings, customer satisfaction, or risk mitigation. As such, aligning technical AI metrics with business metrics is crucial for achieving desired business outcomes.
For example, let's consider a credit card fraud detection model: increasing the model's accuracy or F1-score might lead to more flagged transactions. This could result in an increased number of false positive where legitimate transactions are incorrectly flagged as fraudulent. This has serious business implications, such as reduced usability of an application or platform due to an increase of overcorrected blocked transactions.
Ignoring Data Privacy
Data privacy is like the unsung hero of the AI world. It may not seem as exciting as designing cool algorithms or creating cutting-edge models, but ignoring it can get you into real hot water.
Imagine you're running a health tech startup with a fantastic idea to develop an AI system that predicts potential health risks based on users' personal data, such as age, lifestyle habits, and previous medical history.
While this sounds like a great idea at first, the issue is that this type of data is very sensitive. It's the kind of information that people don't want just anyone to get their hands on. Without following the proper procedures for how to collect, store, and use that data, the model could end up breaking numerous data privacy laws. This, in turn, can lead to serious consequences, like hefty fines or even legal action. Not to mention, it could really damage the company's reputation.
There has been talk about generative AI stealing information on the internet without citing the original source. This can be the case for AI art like Midjourney and Stable Diffusion where artist’s styling is being “copied” by the AI. The current politics on using public data is an ongoing discussion. Privately acquired data is a different story. But user data should always have consent from the users.
Not Preparing for Real-Time Scaling
We’re building an AI model for an exciting new application. It uses AI to create personalized outputs for each user. We’ve tested our model for a limited number of people. So, we launch our app thinking we are all set. But then it goes viral overnight, and now we have thousands, or maybe even millions, of users accessing the system at once.
If we didn't plan for this kind of scale, the AI model might not be able to keep up and overload your resources. That's why it's extremely important to plan for real-time scaling from the start. Think about how the model will handle a large number of users, and then design it to scale up (and down) efficiently. Make sure infrastructure can handle a surge in data processing, and plan for how increased storage needs will be managed.
You could set a cap of users to ensure no server overload but could leave potential users to bounce. Think about the situation when ChatGPT first launched. It was a fast-growing internet app with 100 million users in just two months. There was a period in which users would not be able to access the site without being greeted with a “We are at capacity” message. Not expecting the huge surge of users, OpenAI told its users in the header of the page that it was upgrading it infrastructure.
By all means, don’t over-prepare, though, and incur a huge startup cost unfeasible to cover.
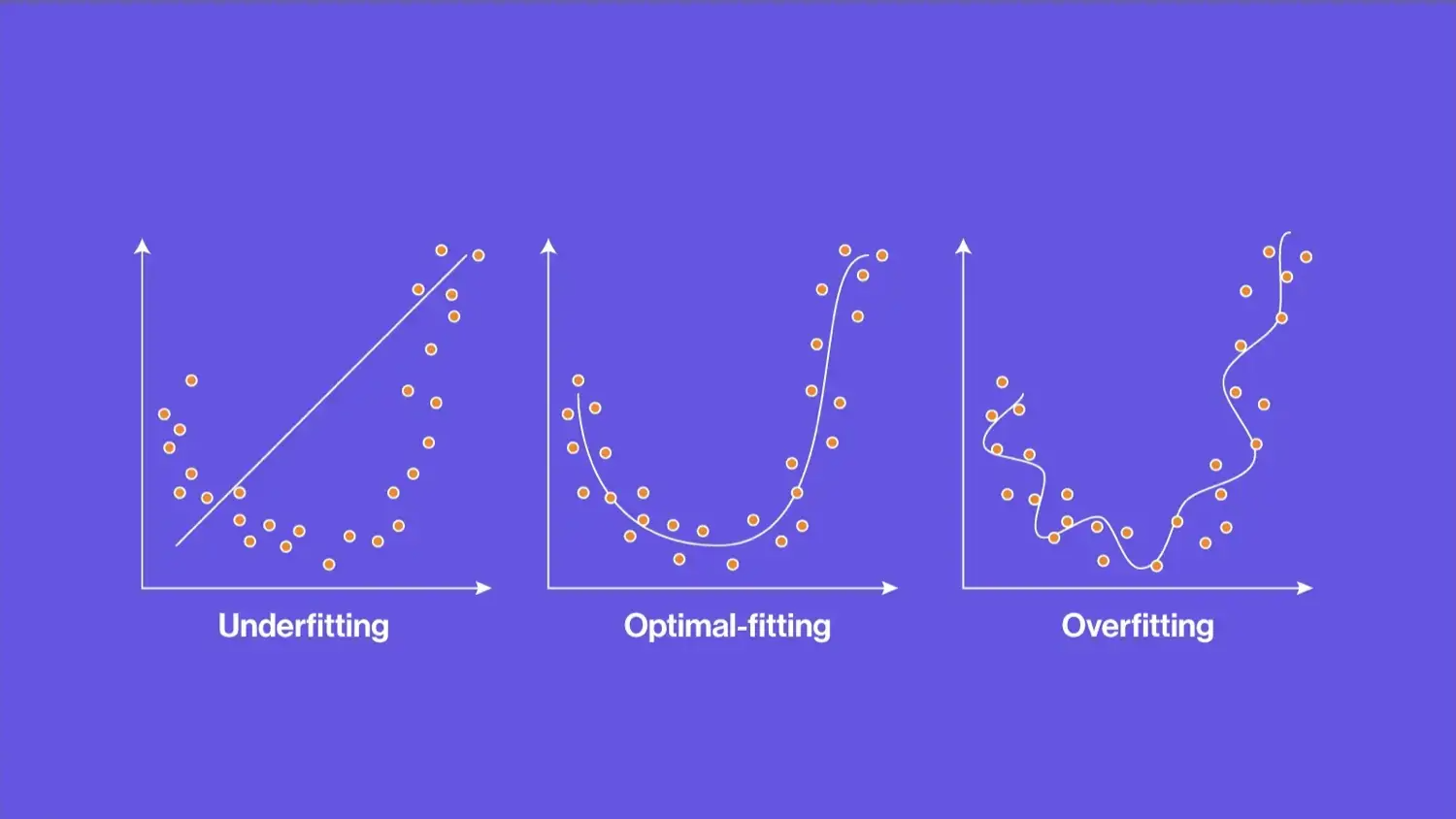
Too Much or Too Little Training
Overfitting occurs when your model learns the training data too well it performs poorly on the test and actual data, similar to just memorization instead of applied inferencing. Overfitted models lack the ability to generalize. When a model is trained too much on the training dataset, it can lead to overfitting.
Use regularization techniques like L1 (Lasso) and L2 (Ridge) add a penalty term to the loss function to constrain the coefficients of the model, preventing them from becoming too large.
But training too little can cause underfitting where the model’s understanding of the data is far too simple to capture the underlying attributes of the data. The model has not learned enough about the training data, that it performs just as poorly with real world data.
To address underfitting, you might need a more complex model, additional features, more data, or even use synthetic data. You could increase the number of parameters in a neural network or increase the maximum depth in a decision tree.
Training AI Models on Unrealistic Data
When researchers train and test models, they often use datasets that are clean, well-labeled, and generally not reflective of real-world data distributions. The results, therefore, look impressive on paper because the model performs well on the test data, which shares the same distribution as the training data. This is referred to as "in-distribution" performance.
However, in real-world scenarios, the data a model encounters ("out-of-distribution" data) often has a different distribution than the one it was trained on. The data may be noisier, have less clear-cut labels, or include classes and features not seen in the training data. Consequently, the model's performance may significantly degrade when it's deployed in the real world. This is referred to as "out-of-distribution" performance.
This challenge has led to a growing focus on "robust AI," which involves developing models that can maintain their performance even when faced with out-of-distribution data. One approach to address this issue is to use techniques like domain adaptation, which try to adjust the model's predictions to better fit the new data distribution.
Not Addressing or Accounting for Biases
Bias in AI models occurs when the algorithms make systematic errors or unfair decisions due to underlying prejudice in the training data or the way the model was designed. Because AI models are trained by humans, they will inherit the bias of humans.
If the AI model isn't checked for bias, it may learn and reproduce unfair patterns, systematically disadvantaging certain data points. It can be hard to avoid biases in the dataset so a good way to combat bias is to set guidelines and rules, monitor and review, and share how data is selected and cleaned to ensure that bias implications are known and addressed.
Overlooking Model Understandability
It can be very easy to set up the model, run it, and then walk away, hoping that it’s doing its job. For AI to be adopted and trusted, it is essential to make its decisions transparent. understandable, and explainable, for responsible AI and upholding AI ethics.
Neural networks are referred to as black boxes because their inner workings can be hard to unveil and understand which can make it difficult to uncover reasonings as to why you model is outputting false positives.
Scientists have been working on making complex AI models, like deep neural networks, more transparent and understandable. They have come up with techniques to help explain why these models make certain decisions.
One method is using attention mechanisms or saliency maps, which highlight the important parts of the input that influenced the model's decision. This lets users see which aspects had the most impact.

Having said that, the best approach to maintaining transparency and ensuring ease of understanding for an AI model is to maintain thorough documentation. This documentation should include detailed information about the data used to train the AI model, including its sources, quality, and any preprocessing steps that were applied.
By keeping comprehensive documentation, we provide transparency regarding the model's foundation and the steps taken to refine the data. This detailed documentation contributes to a clearer understanding of an AI model and instills confidence in its decision-making process.
Neglecting Continuous Monitoring
With daily data changes and shifts in underlying patterns, models can become outdated or less accurate. These changes could stem from various factors such as evolving consumer behaviors, emerging market trends, changes in the competitive landscape, policy modifications, or even global events like a pandemic. This phenomenon is often referred to as concept drift.
As such, for a company that continuously predicts product demand, it's critical to monitor model performance over time. Even though the model may have initially provided accurate predictions, over time, its accuracy might degrade due to the aforementioned changes in real-life data. In order to address such an issue, companies need to maintain regular real-time monitoring by continuously tracking the model's outputs against the actual demand and monitoring performance metrics in real-time.
Additionally, applying incremental learning techniques is crucial. This approach enables the model to learn from new data while retaining the valuable knowledge gained from previously observed data.
By adopting these strategies, companies can effectively adapt to concept drift without disregarding valuable prior information and ensure accurate predictions for product demand.
Develop the Best AI Model
Successfully navigating the world of AI development isn't a cakewalk. It's a journey filled with a lot of considerations, a dash of uncertainties, and a good measure of potential pitfalls. But with a keen eye for detail, a commitment to ethical practices, and a strong grip on robust methodologies, we can create AI solutions that are not only effective and efficient, but also responsible and ethical.
Published at DZone with permission of Kevin Vu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments