Understanding Dropped Updates in Feed Generation Systems in Modern Applications
In this article, understand what dropped updates in feed generation systems are, why they are important, and how to prevent them.
Join the DZone community and get the full member experience.
Join For FreeEvery day, we interact with feed generation systems across various applications. From scrolling through social media updates on Facebook, Instagram, or Twitter to browsing recommendations on Netflix, YouTube, or news aggregator apps, all these platforms rely on feed generation to serve up content tailored to our interests.
This article explores what feed generation systems are, how they work (both in ingesting content and delivering it), and why maintaining a high-quality feed matters for user engagement.
What Is a Feed Generation System?
At a high level, a feed generation system is responsible for providing a user (viewer) with a personalized list of content items (feed items) whenever they open an app or refresh their feed. The system selects and ranks these feed items based on the viewer’s profile and context. Key factors often include:
- Social connections or network: In social media, the people you follow or befriend (friends, pages, companies, etc.) heavily influence which posts you see.
- User interests and history: The system also considers your past behavior and preferences. For example, what genres of movies you watch on Netflix, or which types of videos you engage with on YouTube or TikTok.
In the early days of social media, feeds were primarily network-driven — showing you posts from your friends or people you follow. Nowadays, with the rise of content creators and advanced recommendation algorithms, feeds have become much more content-driven and behavior-driven. Modern feeds often include posts from outside your direct network if the system believes you will find them interesting. In other words, you might see content from strangers or pages you don't follow, because the algorithm predicts you'll engage with it. This shift from a pure social graph to an interest graph is a notable trend across platforms [1][2]. The goal is to increase user engagement by surfacing the most relevant and interesting content for each viewer.
Importantly, the feed items are typically presented in a sorted order, with the most relevant or engaging content at the top. By ranking items this way, platforms increase the likelihood that users will see and interact with compelling content right away, thereby keeping them on the platform longer.
Behind the scenes, delivering a personalized feed is a complex challenge. These systems must ingest vast amounts of content from creators, process and store that content efficiently, and then retrieve and rank content for each viewer in real time. Let's break down the typical architecture into two parts: the ingestion pipeline and the serving (ranking) pipeline.
Feed Content Ingestion Pipeline
Before a piece of content can show up in anyone’s feed, it has to be ingested and stored by the system. Content ingestion is the process by which user-generated posts (or videos, images, etc.) make their way from the front-end (where a user hits "post" or uploads something) into the back-end databases and systems that prepare them for feeds.
Source-of-Truth (SoT) Storage
When a user posts a new content item (e.g., a status update, photo, or video), it is first sent to a backend service via an API (often a POST API endpoint for new feed items). The backend’s source-of-truth service will validate and record the post’s data in a database, acknowledging success back to the user interface once stored. This "SoT" system holds the canonical record of the content (e.g., the text, metadata, author info, timestamps).
Media Handling
If the post includes media (images or videos), that media might be handled by a separate dedicated media storage system. The feed item in the SoT will store references (IDs or URLs) to these media files rather than the binary data itself. This decoupling allows media to be processed (for example, transcoding a video or generating image thumbnails) and served via a specialized media delivery pipeline, while the feed’s SoT focuses on the metadata and textual content.
Derived Timeline Storage
In addition to the primary SoT store, many feed systems maintain secondary derived data stores optimized for retrieving feeds quickly. One common approach is to use a timeline storage or an activity stream storage. In a timeline store, feed updates are often stored in a key-value format, where the key represents a particular timeline or channel, and the value is a list of content items for that timeline. For example, a system might maintain a key like "user123_feed_posts" mapping to a list of recent posts made by User 123, or keys like "user123_likes" mapping to items User 123 has liked. These pre-aggregated lists can be quickly fetched later when assembling feeds. By precomputing and storing content in this way (often via fan-out on write), systems can reduce the work needed at read time to generate a feed [3].
Example: If Alice follows Bob and Carol, the moment Bob or Carol publishes a new post, the system could add that post’s ID to Alice’s timeline list in a fast cache. Later, when Alice opens her app, the system can directly pull the ready-made list of recent posts from Alice’s followees, instead of querying all of Bob and Carol’s posts on the fly. (There are also hybrid approaches and pure on-the-fly retrieval models, but the key is that timeline storage helps serve feeds with low latency.)
The ingestion pipeline ensures that as new content comes in, it’s stored and indexed in all the right places so that it can be efficiently retrieved for any user’s feed request.
Feed Serving Pipeline and Ranking (FPR and SPR)
Once content is ingested and stored, the next challenge is serving a personalized feed to each viewer. Modern feed systems typically use a multi-stage ranking pipeline to gather and sort the best content for a user. Two common terms used to describe these stages are First Pass Ranker (FPR) and Second Pass Ranker (SPR), though different organizations might use slightly different naming. The general idea, however, is consistent: coarse filtering and gathering of candidates in the first stage, followed by refined ranking in the second stage.
Second-Pass Rankers as Candidate Sources
In many architectures, there are multiple content sources feeding into the overall feed. Think of content "buckets" like: posts from people you follow (organic content), sponsored posts/ads, recommended content from pages or hashtags you don't follow, event updates, etc. Each of these sources can have its own logic to retrieve and score content. We can call these source-specific pipelines second-pass rankers (or, in LinkedIn’s terminology, actually first-pass rankers — it's a matter of perspective).
For example, one pipeline might retrieve the top N posts from your connections (friends or people you follow) ranked by some relevance score; another pipeline might retrieve top N recommended posts from outside your network (based on similar users or topics); another might fetch some ads that you’re likely to click, and so on. These systems act in parallel, each pulling candidates from their inventory of content.
First-Pass Ranker (Feed Aggregator)
After these various candidate generators have pulled their top results, the first-pass ranker (or final stage aggregator) will combine all candidates into one list and sort them to produce the unified feed. Essentially, the first-pass ranker takes the inputs from all the candidate sources (the multiple second-pass rankers) and performs a global ranking to decide which items overall should be shown at the top of your feed. This stage may use more holistic scoring algorithms, potentially considering diversity (to avoid showing 10 posts from the same friend in a row, for instance), timing (freshness), and cross-source comparisons (maybe one really relevant ad might outrank a slightly less relevant friend post, or vice versa, depending on the model).
This two-stage approach is common because it balances efficiency and accuracy. The initial candidate fetch (second-pass rankers) can be done quickly and in parallel, often using simpler algorithms or precomputed scores to handle large volumes of content. The final merge (first-pass ranker) can then afford a more complex model to carefully re-rank a smaller set of top candidates from each source [4]. For example, LinkedIn’s feed uses a two-pass ranking architecture where multiple first-pass rankers (they call them FPRs) each select top items from different content types (network updates, job posts, ads, etc.), and then a single second-pass ranker merges them into the final feed list [5].
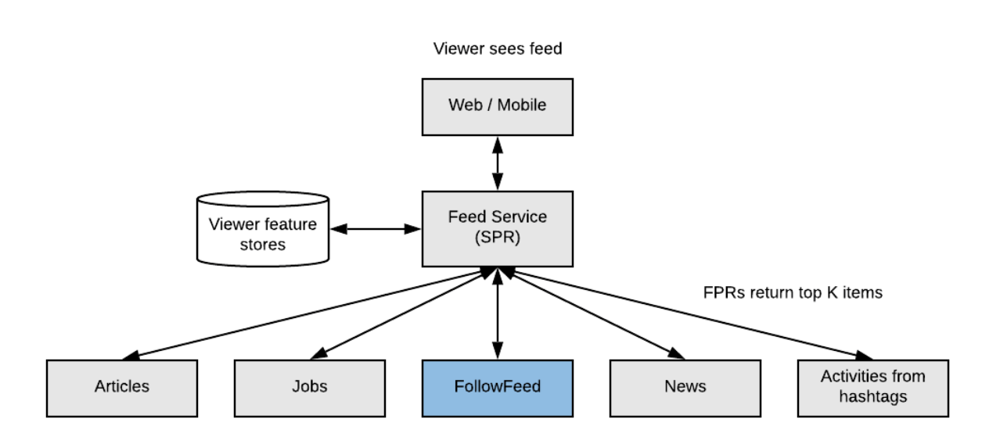 Figure: An illustration of a two-pass feed ranking architecture. Multiple candidate sources (e.g., articles, jobs, network posts, hashtags) each supply top-ranked items via their own models (first stage). These are then combined and re-ranked by a second-stage feed mixer to produce the final personalized feed shown to the user.
Figure: An illustration of a two-pass feed ranking architecture. Multiple candidate sources (e.g., articles, jobs, network posts, hashtags) each supply top-ranked items via their own models (first stage). These are then combined and re-ranked by a second-stage feed mixer to produce the final personalized feed shown to the user.
Each of the candidate source systems (SPR stage in our terminology here) can apply its own filtering and ranking logic. For instance, the "friends and followed accounts" source might filter out posts from people you’ve muted, and rank by a prediction of your interest; the "recommended for you" source might filter out content you’ve seen before and rank by a relevance score; the ads system will choose ads targeting you and rank by some combination of bid and predicted engagement, etc. After these sources return their candidates, the feed aggregator (FPR stage) might apply another layer of filtering (e.g., removing near-duplicates or overly low-quality items) and then sort all items by a unified score to pick, say, the top 20 or 50 items to send to your device.
Why two stages? This design allows different teams or algorithms to specialize (one team can focus on the ads ranking algorithm, another on the friend-posts ranking, etc.), and then a final stage can still ensure a good mix. It’s also more efficient: the system doesn’t waste time deeply ranking content from a source that might only contribute a couple of items in the final feed.
Instead, each source does a quick first cut, and the heavy-lifting model at the end only deals with a relatively small set of candidates [4][6]. Some platforms even include an extra re-ranking step after the second pass — for example, to apply certain business rules or diversity adjustments — but the core idea remains a multi-step refinement.
Handling Dropped Feed Items (Undelivered Content)
Ideally, every content item that the back-end feed service decides to send to a user is something the user can see and interact with. However, in real-world systems, sometimes a feed item is dropped on the way to being displayed (or at the client side) and never actually shown to the user. A "dropped" update means that a slot in the feed was wasted on an item that got filtered out at the last moment (often by the client app or by final sanity checks), resulting in an empty spot or simply one less item shown. There are several reasons this can happen:
- Missing or broken media: One common example is when the feed service includes a post that has an image or video, but the media fails to load or process. Perhaps the image file was corrupted, or the media service (SoT for media) hasn’t finished processing the video. In such cases, the client app might choose to drop that post instead of showing a broken image icon or an unplayable video.
- Temporarily disabled or removed content: Sometimes, the author of a post might temporarily deactivate their account or set their content to private after it was already fetched for the feed. For example, if a friend posted something and then deactivated their profile (or deleted the post) shortly after, the feed service might not know right away — it could attempt to deliver that post, only for the client to realize the author is now inactive or the content is gone. The client then drops the item because it’s no longer viewable. Similarly, if the content was flagged or taken down for policy reasons after being queued for your feed, it should not be displayed.
- Blocked content or privacy settings: Another scenario is when a feed item references a user or content that you have blocked or opted not to see. For instance, imagine your friend tagged someone that you have blocked in a photo. The feed service might retrieve that story (because your friend is in your network), but your app knows you don’t want to see content involving the blocked person, so it will refuse to display it. From the feed system’s perspective, it “dropped” — the back-end thought this post was fine, but the front-end hid it due to user-specific settings.
In all these cases, the dropped item effectively wastes a slot that could have been filled by some other content. The user might scroll and see nothing there (or not see anything missing explicitly, but essentially their feed had one less item than it could have).
Why Dropped Items Are a Problem
Dropping feed updates is undesirable for several reasons:
- Wasted opportunities: Each feed slot is a chance to engage the user. If an item is dropped, the user misses out on a piece of content they might have engaged with. It’s essentially a missed opportunity to keep the user interested.
- Lower engagement: A dropped item often means the user’s feed had less content to interact with, which can directly translate to less time spent, fewer likes or clicks, and generally lower engagement on the platform.
- Revenue impact: On platforms that show ads or sponsored posts within the feed, every dropped (unused) slot could have been an ad impression or some valuable content. Fewer items shown can mean fewer ads shown, impacting revenue. Even aside from ads, lower overall engagement can hurt revenue indirectly (especially if it leads to users visiting less frequently over time).
- Resource waste: It costs computational effort to fetch, rank, and send out feed items. If items get dropped at the last step, those computing resources (CPU time, network bandwidth) were spent for nothing. Among millions of users, a high drop rate could mean significant inefficiency in the system.
In short, dropping updates reduces the efficiency of the feed system and can harm user experience (if, for example, the user notices their feed is oddly empty or misses updates they should have seen).
Reducing Dropped Updates: Improving Feed Quality
The good news is that many dropped items can be prevented by making the feed generation system smarter about what it sends in the first place. The backend should ideally be aware of those “bad” candidates and filter them out before sending the feed to the user. Here are some strategies:
Integrate Signals and Checks in Ranking
The feed generation pipeline can consume signals from various source-of-truth systems to know if a piece of content is no longer valid to show. For example, the profile/account database can send a signal if a user deactivated their account or made their posts private — the feed system should then exclude that user’s posts from candidate generation. Similarly, the media processing service can flag content that failed to process (or is still processing), so the feed can hold off on delivering those posts until the media is ready. By incorporating these signals in real time (or near-real time), the feed rankers (FPR/SPR) will drop those items server-side, rather than relying on the client to do it.
Up-to-Date Filtering Rules
Continuously update the business logic in feed ranking to reflect client-side rules. If the product adds a feature like “mute posts containing certain keywords” or “hide posts where a blocked user is tagged,” then the feed generation service should incorporate equivalent filtering logic. This might involve checking candidate posts against the viewer’s block/mute lists and content preferences and removing them from the ranking set proactively.
Testing and Monitoring
It’s important to monitor how often drops happen and why. Logging when a feed item is dropped at the client (with reasons, if possible) can help engineers update the server logic accordingly. Over time, the goal is to make the server’s chosen feed list as close as possible to what the user will actually see.
When the feed system successfully minimizes dropped updates, the benefits are clear: higher efficiency and a better user experience. The system isn’t wasting effort on doomed content, and users get a fuller feed with more relevant items (leading to higher engagement and potential revenue). In other words, a clean feed generation pipeline that delivers only what the user can and should see translates to a win–win for both the platform and its users.
Conclusion
Feed generation systems are the backbone of many modern apps, quietly deciding what content you see and in what order. They involve a sophisticated architecture: ingesting content from creators, storing it in ways that can be retrieved quickly, and using multi-stage ranking algorithms to personalize each viewer’s feed. As social platforms have evolved from showing purely network-centric updates to using powerful recommendation algorithms, the importance of efficient feed systems has only grown. Understanding this pipeline is not only fascinating from a system design perspective, but it’s crucial for improving user engagement. By ensuring that only high-quality, relevant content makes it through the pipeline (and preemptively filtering out anything broken or unwanted), platforms can keep users scrolling happily — seeing more of what they like, and less of what they don’t.
Overall, a well-tuned feed generation system results in increased efficiency, better engagement, and ultimately a more satisfying experience for users on any content-rich platform. By continuously refining both the ranking algorithms and the filtering mechanisms, engineers aim to serve a feed that feels both personal and seamless every time you open your app.
Sources:
- Sorilbran Stone, "Mastering Social Media Algorithms: The Interest Graph vs the Social Graph," The Shelf Blog, April 2025 [1][2]. (Discusses the shift from network-based feeds to interest-based recommendations in social media platforms.)
- Ali Mohamed et al., "Community-focused Feed Optimization," LinkedIn Engineering Blog, June 2019 [5]. (Describes LinkedIn’s two-pass feed ranking architecture with first pass candidate selection and second pass aggregation.)
- PyImageSearch, "LinkedIn Feed Recommendation Systems," August 2023 [4][6]. (Overview of LinkedIn’s feed ranking system with multiple First Pass Rankers and a Second Pass Ranker combining them.)
- Activity Streams and Feed Frameworks – Grokipedia [3][7]. (On the use of timeline storage and feed pre-computation for scalable social feeds.)
Opinions expressed by DZone contributors are their own.
Comments