DTO: Hipster or Deprecated?
The purpose of this article is to talk a little bit about the usefulness of DTO and address this question.
Join the DZone community and get the full member experience.
Join For FreeData Transfer Objects, known affectionately as DTOs, is the subject of a lot of discussions when we talk about the development of Java applications. DTOs were born in the Java world in EJB 2 for two purposes.
First, to circumvent the EJB serialization problem; second, they implicitly define an assembly phase where all data that will be used for presentation is marshaled before actually going to the presentation layer. Since the EJB is no longer used on a large scale, can DTOs also be discarded? The purpose of this article is to talk a little bit about the usefulness of DTO and address this question.
After all, in an environment of several new topics, (for example, cloud and microservices) does this layer even make sense? When it comes to good software architecture, the answer is practically unanimous: It depends on how closely you want your entity to be coupled to the visualization layer.
Thinking about an underlying architecture in layers, and dividing into three interconnected parts in itself, we have the famous MVC.
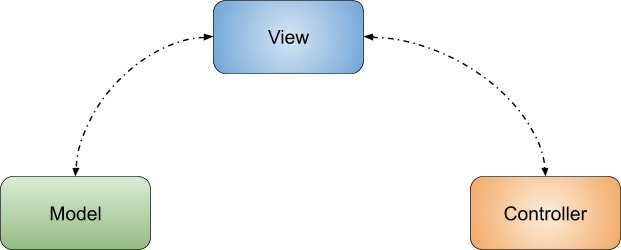
It is worth noting that this strategy is not exclusive to the stack of web applications like Spring MVC and JSF., Exposing your data in a restful application with JSON, The JSON data works as a visualization, even if it is not friendly to a typical user.
Once MVC is briefly explained, we will talk about the advantages and disadvantages of using DTO. Thinking of layered applications, DTO, above all, has the objective of separating the model from the view. Thinking about the problems of DTO:
- Increases the complexity
- There is the possibility of duplicate code
- Adding a new layer has the impact of the delay layer, that is, the possible loss of performance.
In simple systems that do not need a rich model as a premise, not using DTO ends upbringing great benefits to the application. The interesting point is that many serialization frameworks end up forcing the attributes to have accessor or getter and setter methods that are always present and public as mandatory, so, at some point, this will have an impact on application encapsulation and security.
The other option is to add the DTO layer, which basically guarantees the decoupling of the view and the model, as mentioned previously.
It makes it explicit which fields will go to the view layer. Yes, there are several annotations in various frameworks that indicate which fields will not be displayed. However, if you forget to write down, you can export a critical field accidentally, for example, the user's password.
Facilitates drawing in object orientation. One of the points clean code makes clear about object orientation is that OOP hides the data to expose the behavior, and the encapsulation helps with that.
Facilitates updating the database. It is often essential to refactor, migrate the database without this change impacting the customer. This separation facilitates optimizations, modifications to the database without affecting the visualization.
Versioning, backward compatibility is an important point, especially when you have an API for public use and with multiple customers, so it is possible to have a DTO for each version and evolve the business model without worry.
Another benefit is found in the ease of working with the rich model and in the creation of an API that is bullet approved. For example, within my model, I can use a money API; however, within my visualization layer, I export as a simple object with only the monetary value for visualization. That is the right old String in Java.
CQRS. Yes, is Command Query Responsibility Segregation about separating responsibility for writing and reading data and how to do this without DTOs?
In general, adding a layer means decoupling and facilitating maintenance at the expense of adding more classes and complexity, since we also have to think about the conversion operation between these layers. This is the reason, for example, of the existence of MVC, so it is very important to understand that everything is based on impact and trade-offs or what hurts in a given application or situation.
The absence of these layers is very bad, it can result in a Highlander pattern (there can be only one) of which there is a class with all the responsibilities. In the same way, the excess layers become the onion pattern, where the developer cries when passing through each layer.
A more frequent criticism within the DTOs is at work to perform the conversion. The good news is that there are several conversion frameworks, that is, it is not necessary to make the change manually. In this article, we will choose one that is the modelmapper.
The first step is to define the project's dependencies, for example, in Maven:
<dependency>
<groupId>org.modelmapper</groupId>
<artifactId>modelmapper</artifactId>
<version>2.3.6</version>
</dependency>
To illustrate this concept of DTO, we will create an application using JAX-RS connected to MongoDB, all these thanks to Jakarta EE, using Payara as a server. We manage a user with username, salary, birthday, and list of languages the user can speak. As we will work with MongoDB in Jakarta EE, we will use Jakarta NoSQL.
xxxxxxxxxx
import jakarta.nosql.mapping.Column;
import jakarta.nosql.mapping.Convert;
import jakarta.nosql.mapping.Entity;
import jakarta.nosql.mapping.Id;
import my.company.infrastructure.MonetaryAmountAttributeConverter;
import javax.money.MonetaryAmount;
import java.time.LocalDate;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.Objects;
public class User {
private String nickname;
(MonetaryAmountAttributeConverter.class)
private MonetaryAmount salary;
private List<String> languages;
private LocalDate birthday;
private Map<String, String> settings;
//only getter
}
In general, it makes no sense to have entities have getters and setters for all attributes; after all, that would be the same as leaving the attribute public directly. Since the focus of our article is not on the DDD or rich models, we will omit the details of that entity. For our DTO, we will have all the fields that the entity has; however, for visualization, our 'MonetaryAmount' will be a 'String', and the anniversary date will follow the same line.
xxxxxxxxxx
import java.util.List;
import java.util.Map;
public class UserDTO {
private String nickname;
private String salary;
private List<String> languages;
private String birthday;
private Map<String, String> settings;
//getter and setter
}
The great benefit of the mapper is that we don't have to worry about doing this manually. The only point to note is that particular types, for example, the Money-API's 'MonetaryAmount', will need to create a convert to become 'String' and vice versa.
xxxxxxxxxx
import org.modelmapper.AbstractConverter;
import javax.money.MonetaryAmount;
public class MonetaryAmountStringConverter extends AbstractConverter<MonetaryAmount, String> {
protected String convert(MonetaryAmount source) {
if (source == null) {
return null;
}
return source.toString();
}
}
import org.javamoney.moneta.Money;
import org.modelmapper.AbstractConverter;
import javax.money.MonetaryAmount;
public class StringMonetaryAmountConverter extends AbstractConverter<String, MonetaryAmount> {
protected MonetaryAmount convert(String source) {
if (source == null) {
return null;
}
return Money.parse(source);
}
}
The converters are ready; our next step is to instantiate the class that performs the 'ModelMapper' conversion, a big point of using dependency injection is that we can define it as the application level. From now on, the entire application can use the same mapper; for that, it is only necessary to use the annotation 'Inject' as we will see ahead.
xxxxxxxxxx
import org.modelmapper.ModelMapper;
import javax.annotation.PostConstruct;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Produces;
import java.util.function.Supplier;
import static org.modelmapper.config.Configuration.AccessLevel.PRIVATE;
public class MapperProducer implements Supplier<ModelMapper> {
private ModelMapper mapper;
public void init() {
this.mapper = new ModelMapper();
this.mapper.getConfiguration()
.setFieldMatchingEnabled(true)
.setFieldAccessLevel(PRIVATE);
this.mapper.addConverter(new StringMonetaryAmountConverter());
this.mapper.addConverter(new MonetaryAmountStringConverter());
this.mapper.addConverter(new StringLocalDateConverter());
this.mapper.addConverter(new LocalDateStringConverter());
this.mapper.addConverter(new UserDTOConverter());
}
public ModelMapper get() {
return mapper;
}
}
One of the significant advantages of using Jakarta NoSQL is its ease of integrating the database. For example, in this article, we will use the concept of a repository from which we will create an interface for which Jakarta NoSQL will take care of this implementation.
xxxxxxxxxx
import jakarta.nosql.mapping.Repository;
import javax.enterprise.context.ApplicationScoped;
import java.util.stream.Stream;
public interface UserRepository extends Repository<User, String> {
Stream<User> findAll();
}
In the last step, we will make our appeal with JAX-RS. The critical point is that the data exposure will all be done from the DTO; that is, it is possible to carry out any modification within the entity without the customer knowing, thanks to the DTO. As mentioned, the mapper was injected, and the 'map' method greatly facilitates this integration between the DTO and the entity without much code for that.
xxxxxxxxxx
import javax.inject.Inject;
import javax.ws.rs.Consumes;
import javax.ws.rs.DELETE;
import javax.ws.rs.GET;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
import javax.ws.rs.Produces;
import javax.ws.rs.WebApplicationException;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.Response;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
("users")
(MediaType.APPLICATION_JSON)
(MediaType.APPLICATION_JSON)
public class UserResource {
private UserRepository repository;
private ModelMapper mapper;
public List<UserDTO> getAll() {
Stream<User> users = repository.findAll();
return users.map(u -> mapper.map(u, UserDTO.class))
.collect(Collectors.toList());
}
public void insert(UserDTO dto) {
User map = mapper.map(dto, User.class);
repository.save(map);
}
("id")
public void update(("id") String id, UserDTO dto) {
User user = repository.findById(id).orElseThrow(() ->
new WebApplicationException(Response.Status.NOT_FOUND));
User map = mapper.map(dto, User.class);
user.update(map);
repository.save(map);
}
("id")
public void delete(("id") String id) {
repository.deleteById(id);
}
}
Managing databases, code, and integrations is always hard, even on the cloud. Indeed, the server is still there, and someone needs to watch it, run installations and backups, and maintain health in general. The twelve-factor APP requires a strict separation of config from code.
Thankfully, Platform.sh provides a PaaS that manages services, such as databases and message queues, with support for several languages, including Java. Everything is built on the concept of Infrastructure as Code (IaC), managing and provisioning services through YAML files.
In previous posts, we mentioned how this is done on Platform.sh primarily with three files:
1) One to define the services used by the applications (services.yaml).
x
mongodb
typemongodb3.6
disk1024
2) One to define public routes (routes.yaml).
xxxxxxxxxx
"https://{default}/":
typeupstream
upstream"app:http"
"https://www.{default}/"
typeredirect
to"https://{default}/"
It's important to stress that the routes are for applications that we want to share publicly. Therefore, if we want the client to only access these microservices, we can remove their access to the conferences, sessions, and speakers from the routes.yaml file.
3) Platform.sh makes configuring single applications and microservices simple with the '.platform.app.yaml' file. Unlike single applications, each microservice application will have its own directory in the project root and its own '.platform.app.yaml' file associated with that single application. Each application will describe its language and the services it will connect to. Since the client application will coordinate each of the microservices of our application, it will specify those connections using the 'relationships' block of its '.platform.app.yaml' file.
xxxxxxxxxx
nameapp
type"java:11"
disk1024
hooks
buildmvn clean package payara-microbundle
relationships
mongodb'mongodb:mongodb'
web
commands
start
export MONGO_PORT='echo $PLATFORM_RELATIONSHIPS|base64 -d|json_pp|jq -r ".mongodb[0].port"'
export MONGO_HOST='echo $PLATFORM_RELATIONSHIPS|base64 -d|json_pp|jq -r ".mongodb[0].host"'
export MONGO_ADDRESS="${MONGO_HOST}:${MONGO_PORT}"
export MONGO_PASSWORD='echo $PLATFORM_RELATIONSHIPS|base64 -d|json_pp|jq -r ".mongodb[0].password"'
export MONGO_USER='echo $PLATFORM_RELATIONSHIPS|base64 -d|json_pp|jq -r ".mongodb[0].username"'
export MONGO_DATABASE='echo $PLATFORM_RELATIONSHIPS|base64 -d|json_pp|jq -r ".mongodb[0].path"'
java -jar -Xmx1024m -Ddocument.settings.jakarta.nosql.host=$MONGO_ADDRESS \
-Ddocument.database=$MONGO_DATABASE -Ddocument.settings.jakarta.nosql.user=$MONGO_USER \
-Ddocument.settings.jakarta.nosql.password=$MONGO_PASSWORD \
-Ddocument.settings.mongodb.authentication.source=$MONGO_DATABASE \
target/microprofile-microbundle.jar --port $PORT
In this presentation, we talked about integrating an application with the DTO, in addition to the tools to deliver and map your DTO with your entity in a straightforward way. We also covered the advantages and disadvantages of this layer.
Opinions expressed by DZone contributors are their own.
Comments