Duplicate Strings: How to Get Rid of Them and Save Memory
Learn why duplicate stings emerge in Java applications and how you can detect and remove them to avoid numerous memory problems.
Join the DZone community and get the full member experience.
Join For FreeIIn many Java applications, instances of java.lang.String consume a lot of memory. Strings are ubiquitous, because all kinds of data - names of people, products, countries, as well as URLs, queries, units etc. - are naturally represented as strings. However, consider this: the number of distinct strings in most of the categories above is not very high. For example, there are just about 200 countries in the world. What follows is: if the proportion of your app's memory used by strings is high, there is a good chance that some of these strings are duplicates. That is, there are strings a and b such that they have the same value (a.equals(b) ), yet they are different objects ( a != b), and use twice the memory.
Why do such objects emerge? Because when a string is created (e.g. by serialization/deserialization code that reads [byte[] b from a stream and then invokes new String(b) , or by code that extracts and concatenates strings, etc.), the JVM doesn't check if a string with the same value already exists. This would be too expensive, and is unnecessary in most cases. Many strings are short-lived, small or not very numerous even if duplicate.
However, it turns out that redundant strings that stay alive for long time, have many replicas and/or are big, may consume a lot of memory. How much? In my experience, in the majority of unoptimized Java applications, 15..25 per cent of the heap is occupied by long-lived duplicate strings. In several cases that I've investigated, it exceeded 70 per cent. To be fair, some of these cases were memory leaks, e.g. in one situation an app retained in memory every copy of the same SQL query that ran repeatedly. But even in an otherwise perfect application, a lot of memory can be used up by duplicate strings, and trivialities like "http" or "true" can be replicated many thousand times! Such strings increase your app's memory requirements and/or put unnecessary pressure on the garbage collector (conversely, getting rid of unnecessary objects can improve your GC time so that you don't need GC tuning anymore). Thus if you never checked your application for duplicate strings and/or don't know how to deal with them, read on.
Detecting Duplicate Strings
As with most other memory problems, detection of duplicate strings is difficult without proper tooling. Guessing almost never works. And without knowing exactly where the memory is wasted, you may spend a lot of time chasing wrong targets.
Thus, you need to inspect your app's heap with a tool. From experience, the most optimal way to analyze the JVM memory (measured as the amount of information available vs. the tool's impact on application performance) is to obtain a heap dump and then look at it offline. A heap dump is essentially a full snapshot of the heap. It can be either taken at an arbitrary moment by invoking the jmap utility, or the JVM can be configured to produce it automatically if it fails with OutOfMemoryError. If you Google for "JVM heap dump", you will immediately see a bunch of articles explaining in detail how to obtain a dump.
A heap dump is a binary file of about the size of your JVM's heap, so it can only be read and analyzed with special tools. There is a number of such tools available, both open-source and commercial. The most popular open-source tool is Eclipse MAT; there is also VisualVM and some less powerful and lesser-known tools. The commercial tools include the general-purpose Java profilers: JProfiler and YourKit, as well as one tool built specifically for heap dump analysis called JXRay (disclaimer: the author has developed the latter).
Unlike the other tools, JXRay analyzes a heap dump upfront for many common problems, including duplicate strings. It generates a report with all the collected information in HTML format. JXRay calculates the overhead (how much memory you would save if you get rid of a particular problem) in bytes and as a percentage of used heap. Speaking of duplicate strings, it prints both the overall stats (the total number of duplicate strings, how much memory they waste, values of strings that waste most memory)...

...and then groups duplicate strings that are reachable from some GC root via the same reference chain, or from the same data field, as in the example below:
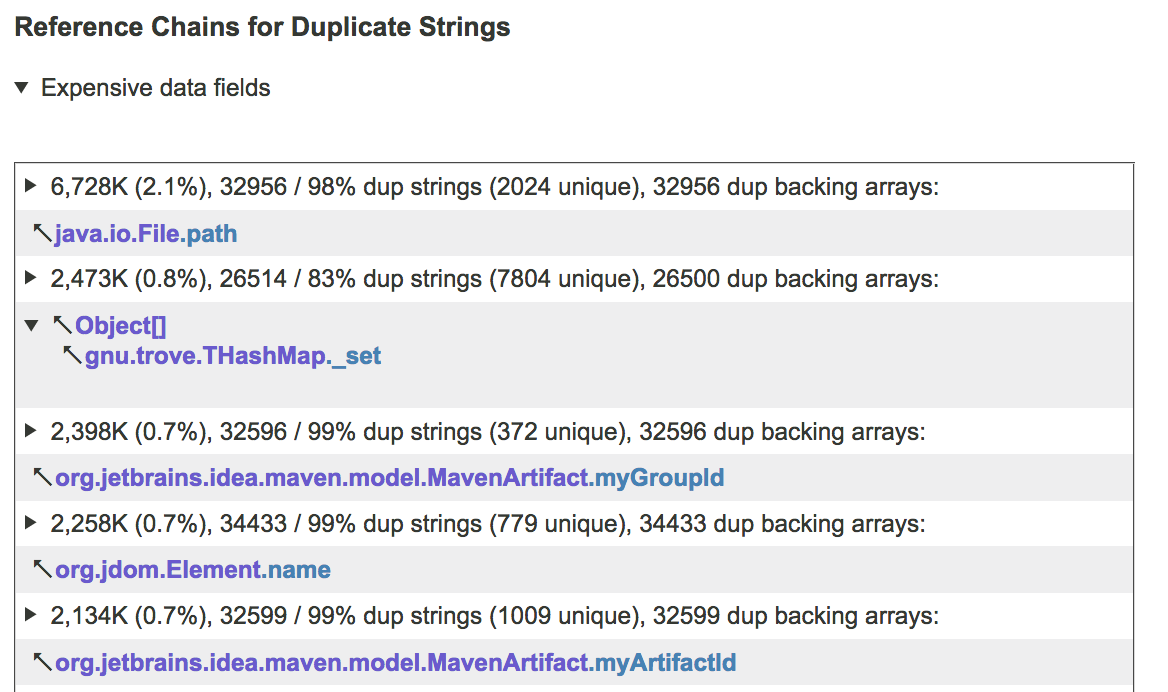
This information allows you to easily deduce the code that manages the problematic strings. The good news is that the amount of such code tends to be small. Often the top 3-5 data structures in the list given by JXRay are responsible for a half of the total overhead, and the next 5-10 for another 45-49 per cent. The remaining 1-2 percent of duplicates scattered about many places in memory are usually not worth optimizing.
Eliminating Duplicate Strings
The JDK developers realized long ago that strings are prone to duplication, and provided a solution: the java.lang.String.intern() method. The following example illustrates how it works:
char[] c = new char[]{'f','o','o'};
String s1 = new String(c);
String s2 = new String(c);
System.out.println(s1.equals(s2)); // Prints 'true'
System.out.println(s1 == s2); // Prints 'false'
// s1 and s2 are distinct objects
s1 = s1.intern();
s2 = s2.intern();
System.out.println(s1 == s2); // Prints 'true'
// Now s1 and s2 point to the same objectintern(s) checks its argument with value "foo" against an internal hash set (string pool) maintained by the JVM. If "foo" is not there, s is added to the pool and returned back. Otherwise an existing, old copy of the "foo" string is returned. The pool works similar to java.util.WeakHashMap : an element that is not referenced from anywhere except this pool is collected by the GC.
Interestingly, despite the importance of string interning, this mechanism had serious shortcomings for quite a long time, until about middle JDK 7. That's why in some older code you can still see string pooling implemented through manually managed maps, for example Guava Interners. More details on the evolution and inner workings of String.intern() can be found in this comprehensive article. These days, unless you use some ancient JDK version, it can be safely assumed that it is the best way of eliminating duplicate strings.
So, if JXRay tells you that duplicate strings come from a certain data structure, and you can change the relevant code, your job is easy enough. For example, for a problematic field Foo.bar , typically you should just add .intern() in the constructor of Foo and/or in other places where bar can be initialized or updated, for example:
public Foo(String bar) {
this.bar = bar != null ? bar.intern() : null;
}Things get a little more complicated if bar is a collection rather than a single string reference. You will need to write some more code (which in a big application should likely be extracted into a utility method), for example:
public Foo(List<String> bar) {
for (int i = 0; i < bar.size(); i++) {
String s = bar.get(i);
bar.set(i, s != null ? s.intern() : null);
}
this.bar = bar;
}Note that here we implicitly assume that the provided list is a java.util.ArrayList or equivalent, where the cost of random access to elements is constant. For a linked list or map, sometimes a better solution is to create and return a whole new collection, where the elements are interned.
But what if the code that manages duplicate strings is not accessible to you at all? For example, the data fields in question are private fields in some library class that you definitely cannot modify?
Deduplicating "Inaccessible" Strings Using Reflection
The author once needed to optimize a big application in which more than a quarter of memory was wasted by duplicate strings, and a considerable portion of this waste was due to strings privately owned by java.net.URI instances. It turns out that constructors of this class always concatenate and re-parse input strings before initializing the internal private data fields such as scheme, host, path etc. This results in memory full of copies of e.g. "http:" string, and there is no conventional way to force this class to intern them.
However, it turns out that these fields can still be updated using Java Reflection, which, in the absence of explicit security barrier, allows you to read and write any data field of any object. This mechanism may not work well in all situations because of its speed and security implications. However, in our case the tradeoff was acceptable. The resulting code looked like
private static Class uriClass = URI.class;
private static Field schemeField, ... // Other fields of URI
static {
schemeField = uriClass.getDeclaredField("scheme");
... // Same for other String fields of URI
// Note that the calls below will throw an exception if a Java SecurityManager
// is installed and configured to forbid invoking setAccessible(). In our app
// this never happens.
schemeField.setAccessible(true);
... // Same for other String fields of URI
}
public static URI internStringsInUri(URI uri) {
if (uri == null) return null;
String scheme = (String) schemeField.get(uri);
if (scheme != null) schemeField.set(uri, scheme.intern());
... // Same for other String fields of URI
return uri;
}Fully Automatic String Deduplication
Still, in some situations the data structures that manage duplicate strings may be really difficult to modify, or you simply may not have time for making elaborate changes. In this case, consider another mechanism, that is available starting from JDK 8u20 and only with the G1 garbage collector. It is enabled with the -XX:+UseStringDeduplication JVM command line flag.
With this flag, the JVM starts a background thread, that, when spare CPU cycles are available to it, scans the heap, looking for duplicate strings. When two different String objects s1 and s2 with identical values are found, they are deduplicated. Only the strings that survived a certain minimum number of GC cycles (3 by default) are processed, to avoid wasting effort on very short-lived objects that, statistically, have a very high chance to become garbage anyway.
Note that this mechanism doesn't work in the same way as String.intern() . To understand the difference, recall that in the JVM, a string is actually represented as two objects: a java.lang.String instance and a char[] array. The former contains several data fields and a private reference to the latter, that in turn contains the actual string contents. After automatic deduplication, s1 and s2 remain separate objects. That means that each of them still sits in memory, taking at least 24 bytes (the exact size of a String object depends on the JVM configuration, but 24 bytes is a minimum). Deduplication just makes both s1 and s2 point to the same char[] array with string contents, whereas the other array becomes garbage and eventually gets collected. Consequently, this mechanism saves less memory in relative terms when the duplicate strings are numerous but short.
Since automatic string deduplication doesn't know in advance which strings are more likely to be duplicates, operates only when spare CPU cycles are available, and doesn't eliminate the redundant string objects entirely, it's less efficient than manual string interning. This article describes it in more detail and provides some benchmarking results.
Summary
Many unoptimized Java applications waste 15-25 percent of memory on duplicate strings. String.intern() is very efficient when applied to strings that are most likely to be duplicate. Such strings tend to concentrate in a relatively small number of places. To find them, you need a tool for Java memory analysis. If you cannot modify the code that manages duplicate strings, you can use the less efficient automatic string deduplication mechanism available since JDK8u20 with G1 garbage collector.
Opinions expressed by DZone contributors are their own.
Comments